


1. 介紹
未來大部分工作將會由人工智慧 (AI) 自動化,這是因為許多研究人員和專業人士正在努力將他們的工作上傳到網路上。這些貢獻不僅幫助我們理解基本概念,還能改進 AI 模型,最終讓我們有更多時間專注於其他活動。
然而,有一個概念即使在專家之間也常常被誤解,那就是時間序列分析中的虛假回歸 (spurious regression)。這個問題發生在回歸模型顯示變數之間有強烈關係時,實際上卻並不存在這種關係。這通常出現在時間序列回歸方程中,雖然 R² 值很高(表示擬合度很高),但 Durbin-Watson 統計量卻非常低,這表示誤差項之間存在強烈的自相關性。
特別令人驚訝的是,幾乎所有的計量經濟學教科書都警告自相關誤差的危險,但這個問題在許多已發表的論文中仍然存在。Granger 和 Newbold (1974) 提出了幾個例子。他們發現某些已發表的方程式的 R² 值為 0.997,而 Durbin-Watson 統計量 (d) 則為 0.53。最極端的例子是一個方程式的 R² 值為 0.999,d 值為 0.093。
這在經濟學和金融學中特別成問題,因為許多關鍵變數顯示出自相關性或相鄰值之間的序列相關性,尤其是在取樣間隔很小的情況下,例如一週或一個月,如果處理不當,可能會導致誤導性的結論。例如,今天的 GDP 與上一季度的 GDP 之間有很強的相關性。我們的文章將詳細解釋 Granger 和 Newbold (1974) 的結果,以及使用 Python 模擬的結果(見第七節),重現他們文章中的關鍵結果。
無論你是經濟學家、數據科學家還是處理時間序列數據的分析師,理解這個問題對於確保你的模型產生有意義的結果至關重要。
接下來的部分將介紹隨機漫步和 ARIMA(0,1,1) 過程。在第三節中,我們將解釋 Granger 和 Newbold (1974) 如何描述無意義回歸的出現,並在第四節中舉例說明。最後,我們將展示如何在處理時間序列數據時避免虛假回歸。
2. 隨機漫步和 ARIMA(0,1,1) 過程的簡單介紹
2.1 隨機漫步
讓 𝐗ₜ 是一個時間序列。如果它的表示為:
𝐗ₜ = 𝐗ₜ₋₁ + 𝜖ₜ. (1)
其中 𝜖ₜ 是白噪音。它可以寫成白噪音的總和,這是一個有用的模擬形式。這是一個非平穩時間序列,因為它的方差依賴於時間 t。
2.2 ARIMA(0,1,1) 過程
ARIMA(0,1,1) 過程表示為:
𝐗ₜ = 𝐗ₜ₋₁ + 𝜖ₜ − 𝜃 𝜖ₜ₋₁. (2)
其中 𝜖ₜ 是白噪音。ARIMA(0,1,1) 過程是非平穩的。它可以寫成獨立隨機漫步和白噪音的總和:
𝐗ₜ = 𝐗₀ + 隨機漫步 + 白噪音. (3) 這種形式對於模擬很有用。
這些非平穩序列通常被用作其他模型預測性能的基準。
3. 隨機漫步可能導致無意義回歸
首先,讓我們回顧線性回歸模型。線性回歸模型表示為:
𝐘 = 𝐗𝛽 + 𝜖. (4)
其中 𝐘 是 T × 1 的因變數向量,𝛽 是 K × 1 的係數向量,𝐗 是 T × K 的自變數矩陣,包含一列全為 1 的列和 (K−1) 列每個 (K−1) 自變數的 T 次觀測值,這些自變數是隨機的,但與 T × 1 的誤差向量 𝜖 獨立分佈。一般假設:
𝐄(𝜖) = 0, (5)
和
𝐄(𝜖𝜖′) = 𝜎²𝐈. (6)
其中 𝐈 是單位矩陣。
檢驗自變數對解釋因變數貢獻的測試是 F 檢驗。檢驗的虛無假設為:
𝐇₀: 𝛽₁ = 𝛽₂ = ⋯ = 𝛽ₖ₋₁ = 0, (7)
檢驗的統計量為:
𝐅 = (𝐑² / (𝐊−1)) / ((1−𝐑²) / (𝐓−𝐊)). (8)
其中 𝐑² 是決定係數。
如果我們想構建檢驗的統計量,假設虛無假設為真,然後嘗試將經濟時間序列的水平擬合為 (方程式 4) 的回歸。接下來假設這些序列不是平穩的或高度自相關。在這種情況下,檢驗程序是無效的,因為 (方程式 8) 中的 𝐅 在虛無假設下並不服從 F 分佈 (方程式 7)。事實上,在虛無假設下,(方程式 4) 的誤差或殘差為:
𝜖ₜ = 𝐘ₜ − 𝐗𝛽₀ ; t = 1, 2, …, T. (9)
並且將具有與原始序列 𝐘 相同的自相關結構。
當出現以下情況時,分佈問題可能會出現:
𝐘ₜ = 𝛽₀ + 𝐗ₜ𝛽₁ + 𝜖ₜ. (10)
其中 𝐘ₜ 和 𝐗ₜ 遵循獨立的一階自回歸過程:
𝐘ₜ = 𝜌 𝐘ₜ₋₁ + 𝜂ₜ, 和 𝐗ₜ = 𝜌* 𝐗ₜ₋₁ + 𝜈ₜ. (11)
其中 𝜂ₜ 和 𝜈ₜ 是白噪音。
我們知道在這種情況下,𝐑² 是 𝐘ₜ 和 𝐗ₜ 之間的相關性的平方。他們使用 Knowles (1954) 文章中的 Kendall 結果,表達 𝐑 的方差:
𝐕𝐚𝐫(𝐑) = (1/T)* (1 + 𝜌𝜌*) / (1 − 𝜌𝜌*). (12)
由於 𝐑 被限制在 -1 和 1 之間,如果它的方差大於 1/3,則 𝐑 的分佈不能在 0 處有模式。這意味著 𝜌𝜌* > (T−1) / (T+1)。
因此,例如,如果 T = 20 且 𝜌 = 𝜌*,如果 𝜌 > 0.86,則會獲得一個在 0 處不是單峰的分佈;如果 𝜌 = 0.9,則 𝐕𝐚𝐫(𝐑) = 0.47。因此 𝐄(𝐑²) 將接近 0.47。
已經顯示,當 𝜌 接近 1 時,𝐑² 可能非常高,暗示 𝐘ₜ 和 𝐗ₜ 之間有強烈的關係。然而,實際上,這兩個序列是完全獨立的。當 𝜌 接近 1 時,兩個序列的行為類似於隨機漫步或接近隨機漫步。此外,這兩個序列高度自相關,這使得回歸的殘差也強烈自相關。因此,Durbin-Watson 統計量 𝐝 將非常低。
這就是為什麼在這種情況下,不能將高 R² 視為兩個序列之間真實關係的證據。
為了探索在回歸兩個獨立隨機漫步時獲得虛假回歸的可能性,下一節將進行 Granger 和 Newbold (1974) 提出的系列模擬。
4. 使用 Python 的模擬結果
在這一節中,我們將通過模擬顯示,使用獨立隨機漫步的回歸模型會使係數的估計產生偏差,且係數的假設檢驗無效。將在第六節中展示生成模擬結果的 Python 代碼。
Granger 和 Newbold (1974) 提出的回歸方程為:
𝐘ₜ = 𝛽₀ + 𝐗ₜ𝛽₁ + 𝜖ₜ
其中 𝐘ₜ 和 𝐗ₜ 被生成為獨立隨機漫步,每個長度為 50。值 𝐒 = |𝛽̂₁| / √(𝐒𝐄̂(𝛽̂₁)),表示檢驗 𝛽₁ 顯著性的統計量,將在下表中報告 100 次模擬的結果。

如果 𝐘ₜ 和 𝐗ₜ 之間沒有關係的虛無假設在 5% 的水平上被拒絕,則當 𝐒 > 2 時。這張表顯示,虛無假設 (𝛽 = 0) 在約四分之一的情況下(71 次)被錯誤拒絕。這很尷尬,因為這兩個變數是獨立的隨機漫步,意味著實際上沒有關係。讓我們來分析為什麼會發生這種情況。
如果 𝛽̂₁ / 𝐒𝐄̂ 服從 𝐍(0,1),則 𝐒 的期望值的絕對值應該是 √2 / π ≈ 0.8(√2/π 是標準正態分佈的絕對值的均值)。然而,模擬結果顯示平均值為 4.59,這意味著估計的 𝐒 被低估的倍數為:
4.59 / 0.8 = 5.7
在經典統計中,我們通常使用約 2 的 t 檢驗閾值來檢查係數的顯著性。然而,這些結果顯示,在這種情況下,您需要使用 11.4 的閾值來正確檢查顯著性:
2 × (4.59 / 0.8) = 11.4
解釋:我們剛剛顯示,包含不屬於模型的變數——特別是隨機漫步——會導致係數的顯著性檢驗完全無效。
為了讓模擬更加清晰,Granger 和 Newbold (1974) 進行了一系列回歸,使用遵循隨機漫步或 ARIMA(0,1,1) 過程的變數。
他們的模擬設置如下:
他們將因變數 𝐘ₜ 回歸於 m 個系列 𝐗ⱼ,ₜ(j = 1, 2, …, m),m 的值從 1 變到 5。因變數 𝐘ₜ 和自變數 𝐗ⱼ,ₜ 遵循相同類型的過程,並測試四種情況:
案例 1(水平):𝐘ₜ 和 𝐗ⱼ,ₜ 遵循隨機漫步。
案例 2(差分):他們使用隨機漫步的一階差分,這是平穩的。
案例 3(水平):𝐘ₜ 和 𝐗ⱼ,ₜ 遵循 ARIMA(0,1,1)。
案例 4(差分):他們使用前面 ARIMA(0,1,1) 過程的一階差分,這是平穩的。
每個系列的長度為 50 次觀測,並對每個案例進行 100 次模擬。
所有誤差項均分佈為 𝐍(0,1),ARIMA(0,1,1) 系列是通過隨機漫步和獨立白噪音的總和得出的。基於 100 次重複的模擬結果,總結如下表。

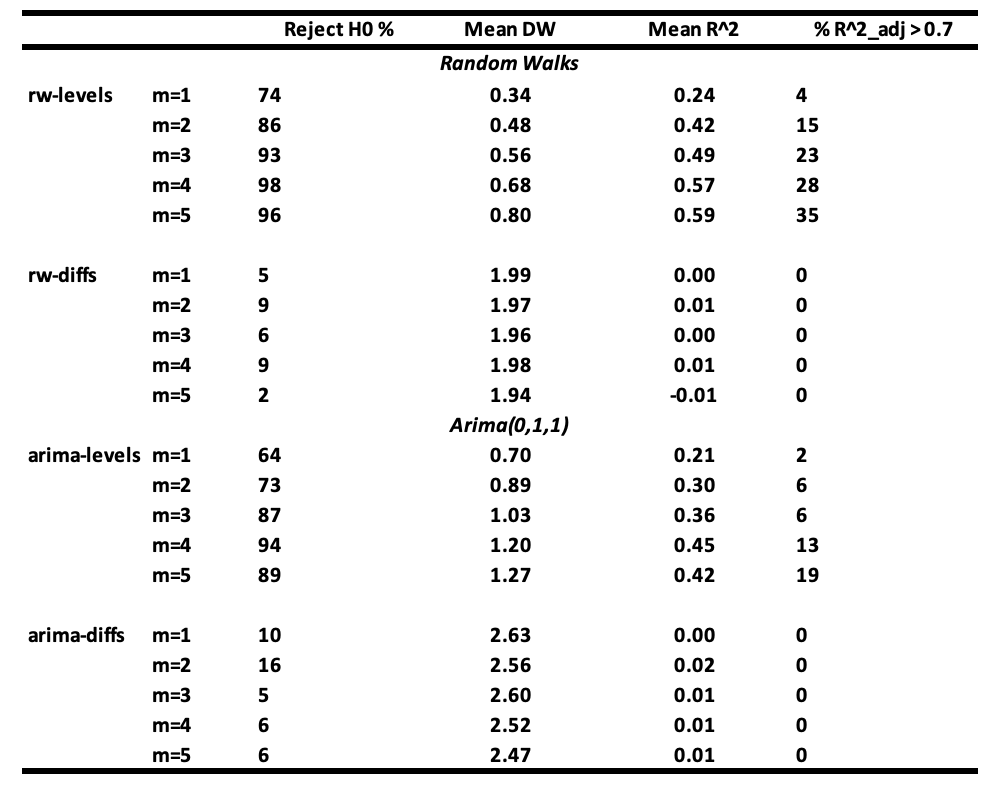
結果解釋:
當 m ≥ 3 時,使用隨機漫步系列(rw-levels)進行回歸時,不拒絕虛無假設的概率變得非常小。𝐑² 和平均 Durbin-Watson 值增加。當使用 ARIMA(0,1,1) 系列(arima-levels)進行回歸時,會得到類似的結果。
當使用白噪音系列(rw-diffs)時,經典回歸分析是有效的,因為誤差系列將是白噪音,最小二乘法將是有效的。
然而,當使用 ARIMA(0,1,1) 系列的差分(arima-diffs)或一階移動平均系列 MA(1) 過程進行回歸時,虛無假設平均被拒絕的次數為:
(10 + 16 + 5 + 6 + 6) / 5 = 8.6
這大於 5% 的情況。
如果你的變數是隨機漫步或接近隨機漫步,並且在回歸中包含不必要的變數,你將經常得到錯誤的結果。高 𝐑² 和低 Durbin-Watson 值並不確認真實關係,而是表明可能是虛假的關係。
5. 如何避免時間序列中的虛假回歸
要列出避免虛假回歸的完整方法真的很難。然而,有幾個良好的做法可以幫助你盡量減少風險。
如果對時間序列數據進行回歸分析,發現殘差強烈自相關,那麼在解釋方程的係數時會有嚴重問題。要檢查殘差中的自相關性,可以使用 Durbin-Watson 測試或 Portmanteau 測試。
根據上述研究,我們可以得出結論,如果對經濟變數進行的回歸分析產生強烈自相關的殘差,這意味著 Durbin-Watson 統計量較低,那麼分析的結果很可能是虛假的,無論觀察到的決定係數 R² 的值是多少。
在這種情況下,了解錯誤規範的來源是很重要的。根據文獻,錯誤規範通常分為三類:(i) 忽略相關變數,(ii) 包含不相關變數,或 (iii) 誤差的自相關性。大多數情況下,錯誤規範來自這三個來源的混合。
為了避免時間序列中的虛假回歸,可以提出幾個建議:
第一個建議是選擇可能解釋因變數的正確宏觀經濟變數。這可以通過查閱文獻或諮詢該領域的專家來實現。
第二個建議是通過取一階差分來使系列平穩。在大多數情況下,宏觀經濟變數的一階差分是平穩的,並且仍然容易解釋。對於宏觀經濟數據,強烈建議對系列進行一次差分,以減少殘差的自相關性,尤其是在樣本量較小的情況下。事實上,這些變數中有時會觀察到強烈的序列相關性。簡單的計算顯示,一階差分幾乎總是比原始序列具有更小的序列相關性。
第三個建議是使用 Box-Jenkins 方法單獨建模每個宏觀經濟變數,然後通過關聯每個單獨模型的殘差來尋找系列之間的關係。這裡的想法是,Box-Jenkins 過程提取系列的解釋部分,留下的殘差僅包含無法通過系列自身過去行為解釋的部分。這使得檢查這些未解釋部分(殘差)是否在變數之間相關變得更容易。
6. 結論
許多計量經濟學教科書警告回歸模型中的規範錯誤,但這個問題仍然出現在許多已發表的論文中。Granger 和 Newbold (1974) 強調了虛假回歸的風險,其中高 R² 值伴隨著非常低的 Durbin-Watson 統計量。
通過使用 Python 模擬,我們展示了這些虛假回歸的一些主要原因,特別是包括不屬於模型的變數和高度自相關的變數。我們還演示了這些問題如何完全扭曲對係數的假設檢驗。
希望這篇文章能幫助減少未來計量經濟分析中虛假回歸的風險。
7. 附錄:模擬的 Python 代碼。
##################################################### 模擬代碼表 1 #####################################################
import numpy as np
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
np.random.seed(123)
M = 100
n = 50
S = np.zeros(M)
for i in range(M):
#—————————————————————
# 生成數據
#—————————————————————
espilon_y = np.random.normal(0, 1, n)
espilon_x = np.random.normal(0, 1, n)
Y = np.cumsum(espilon_y)
X = np.cumsum(espilon_x)
#—————————————————————
# 擬合模型
#—————————————————————
X = sm.add_constant(X)
model = sm.OLS(Y, X).fit()
#—————————————————————
# 計算統計量
#——————————————————
S[i] = np.abs(model.params[1])/model.bse[1]
#——————————————————
# S 的最大值
#——————————————————
S_max = int(np.ceil(max(S)))
#——————————————————
# 創建區間
#——————————————————
bins = np.arange(0, S_max + 2, 1)
#——————————————————
# 計算直方圖
#——————————————————
frequency, bin_edges = np.histogram(S, bins=bins)
#——————————————————
# 創建數據框
#——————————————————
df = pd.DataFrame(
“S 區間”: [f”int(bin_edges[i])-int(bin_edges[i+1])” for i in range(len(bin_edges)-1)],
“頻率”: frequency
)
print(df)
print(np.mean(S))
##################################################### 模擬代碼表 2 #####################################################
import numpy as np
import pandas as pd
import statsmodels.api as sm
from statsmodels.stats.stattools import durbin_watson
from tabulate import tabulate
np.random.seed(1) # 使結果可重複
#——————————————————
# 定義函數
#——————————————————
def generate_random_walk(T):
“””
生成長度為 T 的隨機漫步系列:
Y_t = Y_t-1 + e_t,
其中 e_t ~ N(0,1).
“””
e = np.random.normal(0, 1, size=T)
return np.cumsum(e)
def generate_arima_0_1_1(T):
“””
根據 Granger & Newbold 的方法生成 ARIMA(0,1,1):
該系列是通過將隨機漫步和獨立白噪音相加來獲得的。
“””
rw = generate_random_walk(T)
wn = np.random.normal(0, 1, size=T)
return rw + wn
def difference(series):
“””
計算一維系列的一階差分。
返回長度為 T-1 的系列。
“””
return np.diff(series)
#——————————————————
# 參數
#——————————————————
T = 50 # 每個系列的長度
n_sims = 100 # 模擬次數
alpha = 0.05 # 顯著性水平
#——————————————————
# 定義模擬函數
#——————————————————
def run_simulation_case(case_name, m_values=[1,2,3,4,5]):
“””
case_name : 用於生成類型的標識符:
– ‘rw-levels’ : 隨機漫步(水平)
– ‘rw-diffs’ : 隨機漫步的差分(白噪音)
– ‘arima-levels’ : ARIMA(0,1,1) 的水平
– ‘arima-diffs’ : ARIMA(0,1,1) 的差分 => MA(1)
m_values : 回歸變數的數量列表。
返回一個數據框,其中每個 m 包含:
– 拒絕 H0 的百分比
– 平均 Durbin-Watson
– 平均 R^2
– % R^2 > 0.1
“””
results = []
for m in m_values:
count_reject = 0
dw_list = []
r2_adjusted_list = []
for _ in range(n_sims):
#————————————–
# 1) 生成獨立的 Y_t 和 X_j,t。
#—————————————-
if case_name == ‘rw-levels’:
Y = generate_random_walk(T)
Xs = [generate_random_walk(T) for __ in range(m)]
elif case_name == ‘rw-diffs’:
# Y 和 X 是隨機漫步的差分,即 ~ 白噪音
Y_rw = generate_random_walk(T)
Y = difference(Y_rw)
Xs = []
for __ in range(m):
X_rw = generate_random_walk(T)
Xs.append(difference(X_rw))
# 注意:現在 Y 和 Xs 的長度為 T-1
# => 調整 T_effectif = T-1
# => 將使用 T_effectif 點進行回歸
elif case_name == ‘arima-levels’:
Y = generate_arima_0_1_1(T)
Xs = [generate_arima_0_1_1(T) for __ in range(m)]
elif case_name == ‘arima-diffs’:
# ARIMA(0,1,1) 的差分 => MA(1)
Y_arima = generate_arima_0_1_1(T)
Y = difference(Y_arima)
Xs = []
for __ in range(m):
X_arima = generate_arima_0_1_1(T)
Xs.append(difference(X_arima))
# 2) 準備回歸數據
# 根據情況,長度為 T 或 T-1
if case_name in [‘rw-levels’,’arima-levels’]:
Y_reg = Y
X_reg = np.column_stack(Xs) if m>0 else np.array([])
else:
# 在差分的情況下,長度為 T-1
Y_reg = Y
X_reg = np.column_stack(Xs) if m>0 else np.array([])
# 3) OLS 回歸
X_with_const = sm.add_constant(X_reg) # 添加截距
model = sm.OLS(Y_reg, X_with_const).fit()
# 4) 全局 F 檢驗:H0:所有 beta_j = 0
# 檢查 p 值是否 < alpha
if model.f_pvalue is not None and model.f_pvalue < alpha:
count_reject += 1
# 5) R^2, Durbin-Watson
r2_adjusted_list.append(model.rsquared_adj)
dw_list.append(durbin_watson(model.resid))
# 在 n_sims 次重複中統計
reject_percent = 100 * count_reject / n_sims
dw_mean = np.mean(dw_list)
r2_mean = np.mean(r2_adjusted_list)
r2_above_0_7_percent = 100 * np.mean(np.array(r2_adjusted_list) > 0.7)
results.append(
‘m’: m,
‘拒絕 %’: reject_percent,
‘平均 DW’: dw_mean,
‘平均 R^2’: r2_mean,
‘% R^2_adj>0.7’: r2_above_0_7_percent
)
return pd.DataFrame(results)
#——————————————————
# 應用模擬
#——————————————————
cases = [‘rw-levels’, ‘rw-diffs’, ‘arima-levels’, ‘arima-diffs’]
all_results =
for c in cases:
df_res = run_simulation_case(c, m_values=[1,2,3,4,5])
all_results[c] = df_res
#——————————————————
# 將數據存儲在表中
#——————————————————
for case, df_res in all_results.items():
print(f”\n\n案例”)
print(tabulate(df_res, headers=’keys’, tablefmt=’fancy_grid’))


參考文獻
Granger, Clive WJ, and Paul Newbold. 1974. “計量經濟學中的虛假回歸。” 《計量經濟學期刊》 2 (2): 111–20.
Knowles, EAG. 1954. “理論統計練習。”牛津大學出版社。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!



")




{kind=link}