


在快速發展的人工智慧領域中,檢索增強生成 (Retrieval Augmented Generation, RAG) 成為了一個改變遊戲規則的技術,徹底改變了基礎模型 (Foundation Models, FMs) 與特定組織數據的互動方式。隨著企業越來越依賴人工智慧驅動的解決方案,對於準確、具上下文意識和量身定制的回應需求比以往任何時候都更為重要。
現在,亞馬遜基石 (Amazon Bedrock)、LlamaIndex 和 RAGAS 這三個強大工具的組合,將重新定義 RAG 回應的評估和優化。這篇文章將深入探討這些創新工具如何協同工作,提升你的人工智慧應用表現,確保它們不僅能滿足,還能超越企業級部署的高標準。
無論你是資深的人工智慧從業者,還是探索生成式人工智慧潛力的商業領袖,這份指南將為你提供知識和工具,幫助你:
利用亞馬遜基石的強大基礎模型
使用 RAGAS 的全面評估指標來評估 RAG 系統
在這篇文章中,我們將探討如何利用亞馬遜基石、LlamaIndex 和 RAGAS 來增強你的 RAG 實施。你將學到實用的技術來評估和優化你的人工智慧系統,使其能夠提供更準確、具上下文意識的回應,符合你組織的特定需求。讓我們一起深入了解這些強大工具如何幫助你建立更有效和可靠的人工智慧解決方案。
RAG 評估
RAG 評估對於確保 RAG 模型產生準確、一致和相關的回應非常重要。通過分析檢索和生成組件,RAG 評估有助於識別瓶頸、監控性能並改善整體系統。目前的 RAG 流程經常使用基於相似性的指標,如 ROUGE、BLEU 和 BERTScore 來評估生成回應的質量,這對於精煉和提升模型的能力至關重要。
上述提到的 ROUGE、BLEU 和 BERTScore 指標在評估相關性和檢測幻覺方面存在限制。需要更複雜的指標來評估事實的一致性和準確性。
使用基礎模型評估 RAG 組件
我們也可以使用基礎模型作為評判,計算檢索和生成的各種指標。以下是這些指標的一些例子:
檢索組件
上下文精確度 – 評估所有在上下文中存在的真實相關項目是否被排名更高。
上下文召回率 – 確保上下文包含回答問題所需的所有相關信息。
生成器組件
可信度 – 驗證生成的答案是否根據提供的上下文事實準確,有助於識別錯誤或“幻覺”。
答案相關性 – 衡量答案與問題的匹配程度。分數越高,表示答案完整且相關,分數越低則表示缺少或冗餘的信息。
解決方案概述
這篇文章將指導你如何使用 RAGAS 和 LlamaIndex 以及亞馬遜基石來評估 RAG 回應的質量。
在這篇文章中,我們還將利用 Langchain 創建一個示範 RAG 應用。
亞馬遜基石是一項完全管理的服務,提供來自 AI21 Labs、Anthropic、Cohere、Meta、Stability AI 和亞馬遜等領先人工智慧公司的高效基礎模型 (FMs),通過單一 API 提供,並提供構建生成式人工智慧應用所需的廣泛功能,確保安全性、隱私和負責任的人工智慧。
檢索增強生成評估 (RAGAS) 框架提供多種指標來評估 RAG 系統管道的每個部分,識別改進的領域。它利用基礎模型來測試各個組件,幫助確定需要開發的模塊,以提升整體結果。
LlamaIndex 是一個用於構建大型語言模型 (LLM) 應用的框架。它簡化了來自各種來源的數據整合,並提供數據索引、引擎、代理和應用集成的工具。它優化了搜索和檢索,簡化了查詢 LLM 和檢索文檔的過程。這篇文章專注於使用它的可觀察性/評估模塊。
LangChain 是一個開源框架,簡化了基於基礎模型的應用創建。它提供了鏈接 LLM 操作、管理上下文和整合外部數據來源的工具。LangChain 主要用於構建聊天機器人、問答系統和其他需要複雜語言處理能力的人工智慧驅動應用。
架構圖
以下圖表是一個高層次的參考架構,解釋了如何使用 RAGAS 或 LlamaIndex 評估 RAG 解決方案。

該解決方案由以下組件組成:
評估數據集 – RAG 的源數據來自亞馬遜 SageMaker FAQ,代表 170 對問題和答案。這對應於架構圖中的第一步。
構建示範 RAG – 文檔被分割成塊並存儲在亞馬遜基石知識庫中 (第 2-4 步)。我們使用 Langchain 檢索問答來回答用戶查詢。此過程在運行時從索引中檢索相關數據並將其傳遞給基礎模型 (FM)。
RAG 評估 – 為了評估檢索增強生成 (RAG) 解決方案的質量,我們可以使用 RAGAS 和 LlamaIndex。LLM 通過將其預測與真實答案進行比較來執行評估 (第 5-6 步)。
你必須遵循提供的筆記本來重現該解決方案。我們在這篇文章中詳細說明了主要代碼組件。
前提條件
要實施此解決方案,你需要以下內容:
一個具有創建 AWS 身份和訪問管理 (IAM) 角色和策略權限的 AWS 帳戶。更多信息,請參見訪問管理概述:權限和策略。
亞馬遜 Titan 嵌入 G1 – 文本模型和 Anthropic Claude 3 Sonnet 在亞馬遜基石上的訪問權限已啟用。詳細說明,請參見模型訪問。
運行提供的 Python 前提代碼
導入 FAQ 數據
第一步是導入 SageMaker FAQ 數據。為此,LangChain 提供了一個 WebBaseLoader 對象,將 HTML 網頁中的文本加載到文檔格式中。然後,我們將每個文檔分割成多個 2000 個標記的塊,並有 100 個標記的重疊。請參見以下代碼:
text_chunks = split_document_from_url(SAGEMAKER_URL, chunck_size= 2000, chunk_overlap=100)
retriever_db= get_retriever(text_chunks, bedrock_embeddings)
設置嵌入和 LLM 與亞馬遜基石和 LangChain
為了構建示範 RAG 應用,我們需要一個 LLM 和一個嵌入模型:
LLM – Anthropic Claude 3 Sonnet
嵌入 – 亞馬遜 Titan 嵌入 – 文本 V2
這段代碼設置了一個使用亞馬遜基石的 LangChain 應用,配置 Titan 的嵌入和 Claude 3 Sonnet 模型進行文本生成,並設置特定參數來控制模型的輸出。請參見以下代碼:
from botocore.client import Config
from langchain.llms.bedrock import Bedrock
from langchain_aws import ChatBedrock
from langchain.embeddings import BedrockEmbeddings
from langchain.retrievers.bedrock import AmazonKnowledgeBasesRetriever
from langchain.chains import RetrievalQA
import nest_asyncio
nest_asyncio.apply()
#URL 以獲取文檔
SAGEMAKER_URL=”https://aws.amazon.com/sagemaker/faqs/”
#基石參數
EMBEDDING_MODEL=”amazon.titan-embed-text-v2:0″
BEDROCK_MODEL_ID=”anthropic.claude-3-sonnet-20240229-v1:0″
bedrock_embeddings = BedrockEmbeddings(model_id=EMBEDDING_MODEL,client=bedrock_client)
model_kwargs = {
“temperature”: 0,
“top_k”: 250,
“top_p”: 1,
“stop_sequences”: [“\\n\\nHuman:”]
}
llm_bedrock = ChatBedrock(
model_id=BEDROCK_MODEL_ID,
model_kwargs=model_kwargs
)
設置知識庫
我們將創建亞馬遜基石知識庫的網頁爬蟲數據源,並處理 SageMaker FAQ 數據。
在以下代碼中,我們將嵌入的文檔加載到知識庫中,並使用 LangChain 設置檢索器:
from utils import split_document_from_url, get_bedrock_retriever
from botocore.exceptions import ClientError
text_chunks = split_document_from_url(SAGEMAKER_URL, chunck_size= 2000, chunk_overlap=100)
retriever_db= get_bedrock_retriever(text_chunks, region)
建立問答鏈以查詢檢索 API
在數據庫填充後,創建一個問答檢索鏈,從向量存儲中提取上下文進行問題回答。你還需要根據 Claude 提示工程的指導原則定義一個提示模板。請參見以下代碼:
from langchain_core.prompts import ChatPromptTemplate
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_retrieval_chain
system_prompt = (
“使用給定的上下文回答問題。 “
“如果你不知道答案,請說你不知道。 “
“最多使用三個句子,保持答案簡潔明瞭。 “
“上下文: {context}”
)
prompt_template = ChatPromptTemplate.from_messages([
(“system”, system_prompt),
(“human”, “{input}”)
]
)
question_answer_chain = create_stuff_documents_chain(llm_bedrock, prompt_template)
chain = create_retrieval_chain(retriever_db, question_answer_chain)
建立數據集以評估 RAG 應用
為了評估 RAG 應用,我們需要以下數據集的組合:
問題 – 作為 RAG 流程輸入的用戶查詢
上下文 – 根據提供的查詢從企業或外部數據源檢索的信息
答案 – LLM 生成的回應
真實答案 – 人工標註的理想答案,可用作與 LLM 生成的答案進行比較的基準
我們準備好評估 RAG 應用。如前所述,我們選擇 3 個指標來評估我們的 RAG 解決方案:
可信度
答案相關性
答案正確性
欲了解更多信息,請參見指標。
這一步涉及定義一個評估數據集,包含一組真實問題和答案。對於這篇文章,我們從 SageMaker FAQ 中隨機選擇了四個問題。請參見以下代碼:
EVAL_QUESTIONS = [
“我可以手動停止 SageMaker 自動駕駛工作嗎?”,
“我在 SageMaker Studio 中創建和運行的每個筆記本會單獨收費嗎?”,
“我會因為創建和設置 SageMaker Studio 域而被收費嗎?”,
“我的數據會被用來更新使用 SageMaker JumpStart 的客戶所提供的基礎模型嗎?”,
]
#為每個問題定義真實答案
EVAL_ANSWERS = [
“是的。你可以隨時停止工作。當 SageMaker 自動駕駛工作被停止時,所有進行中的試驗將被停止,並且不會開始新的試驗。”,
“””不會。你可以在同一計算實例上創建和運行多個筆記本。
你只需為你使用的計算付費,而不是為每個項目付費。
你可以在我們的計費指南中了解更多信息。
除了筆記本,你還可以在 SageMaker Studio 中啟動和運行終端和交互式外殼,所有這些都在同一計算實例上進行。”””,
“不,創建或配置 SageMaker Studio 域(包括添加、更新和刪除用戶配置檔)不會收費。”,
“不,你的推理和訓練數據不會被用來或分享以更新或訓練 SageMaker JumpStart 提供給客戶的基礎模型。”
]
使用 RAGAS 評估 RAG
評估 RAG 解決方案需要將 LLM 的預測與真實答案進行比較。為此,我們使用 LangChain 的 batch() 函數對評估數據集中的所有問題進行推斷。
然後,我們可以使用 RAGAS 的 evaluate() 函數對每個指標(答案相關性、可信度和答案正確性)進行評估。它使用 LLM 來計算指標。隨意使用 RAGAS 的其他指標。
請參見以下代碼:
from ragas.metrics import answer_relevancy, faithfulness, answer_correctness
from ragas import evaluate
#批量調用和數據集創建
result_batch_questions = chain.batch([{“input”: q} for q in EVAL_QUESTIONS])
dataset= build_dataset(EVAL_QUESTIONS,EVAL_ANSWERS,result_batch_questions, text_chunks)
result = evaluate(dataset=dataset, metrics=[ answer_relevancy, faithfulness, answer_correctness ],llm=llm_bedrock, embeddings=bedrock_embeddings, raise_exceptions=False )
df = result.to_pandas()
df.head()
以下截圖顯示了評估結果和 RAGAS 的答案相關性分數。

答案相關性
在答案相關性分數列中,接近 1 的分數表示生成的回應與輸入查詢相關。
可信度
在第二列中,第一個查詢結果的可信度分數較低(0.2),這表示回應不是基於上下文而來,是幻覺。其餘查詢結果的可信度分數較高(1.0),表示回應是基於上下文而來。
答案正確性
在最後一列答案正確性中,第二行和最後一行的答案正確性較高,意味著 LLM 提供的答案更接近真實答案。
使用 LlamaIndex 評估 RAG
LlamaIndex 與 RAGAS 類似,提供了一個全面的 RAG(檢索增強生成)評估模塊。這個模塊提供多種指標來評估你的 RAG 系統的性能。評估過程生成兩個關鍵輸出:
反饋:評判 LLM(語言模型)以字符串形式提供詳細的評估反饋,提供對系統性能的定性見解。
分數:這個數值指示答案滿足評估標準的程度。根據具體的評估指標,計分系統會有所不同。例如,像答案相關性和可信度這樣的指標通常在 0 到 1 的範圍內進行計分。
這些輸出允許對你的 RAG 系統性能進行定性和定量評估,使你能夠識別改進的領域並跟踪進展。
以下是來自筆記本的代碼示例:
from llama_index.llms.bedrock import Bedrock
from llama_index.core.evaluation import (
AnswerRelevancyEvaluator,
CorrectnessEvaluator,
FaithfulnessEvaluator
)
from utils import evaluate_llama_index_metric
bedrock_llm_llama = Bedrock(model=BEDROCK_MODEL_ID)
faithfulness= FaithfulnessEvaluator(llm=bedrock_llm_llama)
answer_relevancy= AnswerRelevancyEvaluator(llm=bedrock_llm_llama)
correctness= CorrectnessEvaluator(llm=bedrock_llm_llama)
答案相關性
df_answer_relevancy= evaluate_llama_index_metric(answer_relevancy, dataset)
df_answer_relevancy.head()
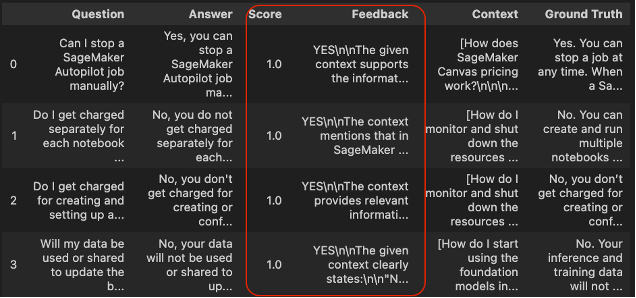
分數列定義了答案相關性評估標準的結果。所有通過的值都設置為 1,這意味著所有預測都與檢索的上下文相關。
此外,反饋列提供了通過分數結果的清晰解釋。我們可以觀察到所有答案都與從檢索器提取的上下文一致。
答案正確性
df_correctness= evaluate_llama_index_metric(correctness, dataset)
df_correctness.head()
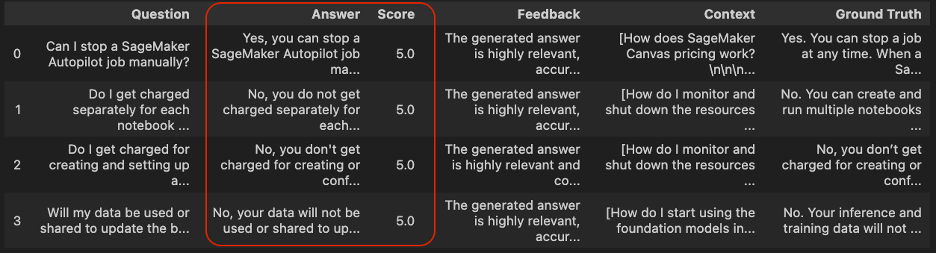
所有分數列的值都設置為 5.0,這意味著所有預測與真實答案一致。
可信度
以下截圖顯示了答案可信度的評估結果。
df_faithfulness= evaluate_llama_index_metric(faithfulness, dataset)
df_faithfulness.head()

所有分數列的值都設置為 1.0,這意味著 LLM 生成的所有答案都與檢索的上下文一致。
結論
雖然基礎模型提供了令人印象深刻的生成能力,但在解決特定組織查詢方面的有效性一直是一個持續的挑戰。檢索增強生成框架作為一個強大的解決方案出現,通過使 LLM 能夠利用外部的、特定於組織的數據源來彌補這一差距。
要真正釋放 RAG 流程的潛力,RAGAS 框架與 LlamaIndex 結合提供了一個全面的評估解決方案。通過仔細評估檢索和生成組件,這種方法使組織能夠確定改進的領域並精煉其 RAG 實施。結果是?不僅事實準確,而且對用戶查詢高度相關的回應。
通過採用這種整體評估方法,企業可以充分利用生成式人工智慧應用的變革力量。這不僅最大化了從這些技術中獲得的價值,還為更智能、具上下文意識和可靠的人工智慧系統鋪平了道路,這些系統能夠真正理解和解決組織的獨特需求。
隨著我們不斷推進人工智慧的可能性,像亞馬遜基石、LlamaIndex 和 RAGAS 這樣的工具將在塑造企業人工智慧應用的未來中發揮關鍵作用。通過擁抱這些創新,組織可以自信地駕馭生成式人工智慧的激動人心的前沿,開啟新的效率、洞察和競爭優勢。
對於進一步探索,對增強人工智慧生成內容可靠性感興趣的讀者可以查看亞馬遜基石的 Guardrails 功能,該功能提供額外的工具,如上下文基礎檢查。
關於作者
 Madhu 是一位高級合作夥伴解決方案架構師,專注於全球公共部門的網絡安全夥伴。擁有超過 20 年的軟體設計和開發經驗,他與 AWS 夥伴合作,確保客戶實施符合嚴格合規和安全目標的解決方案。他的專業知識在於為各種企業需求構建可擴展、高可用、安全和彈性的應用。
Madhu 是一位高級合作夥伴解決方案架構師,專注於全球公共部門的網絡安全夥伴。擁有超過 20 年的軟體設計和開發經驗,他與 AWS 夥伴合作,確保客戶實施符合嚴格合規和安全目標的解決方案。他的專業知識在於為各種企業需求構建可擴展、高可用、安全和彈性的應用。
 Babu Kariyaden Parambath 是 AWS 的高級人工智慧/機器學習專家。在 AWS,他喜歡與客戶合作,幫助他們識別具有商業價值的正確商業用例,並利用 AWS 的人工智慧/機器學習解決方案和服務來解決它。在加入 AWS 之前,Babu 是一位人工智慧宣導者,擁有 20 年的多元行業經驗,為客戶提供人工智慧驅動的商業價值。
Babu Kariyaden Parambath 是 AWS 的高級人工智慧/機器學習專家。在 AWS,他喜歡與客戶合作,幫助他們識別具有商業價值的正確商業用例,並利用 AWS 的人工智慧/機器學習解決方案和服務來解決它。在加入 AWS 之前,Babu 是一位人工智慧宣導者,擁有 20 年的多元行業經驗,為客戶提供人工智慧驅動的商業價值。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!



")




{kind=link}