


在這個教學中,我們將學習如何使用 IBM 的開源 Granite 3B 模型,結合 Hugging Face Transformers,輕鬆地對文本數據進行情感分析。情感分析是一種廣泛使用的自然語言處理 (NLP) 技術,可以快速識別文本中表達的情感。這對於希望了解客戶反饋並改善產品和服務的企業來說非常重要。現在,讓我們一步一步來安裝必要的庫,載入 IBM Granite 模型,分類情感,並可視化結果,所有這些都可以在 Google Colab 中輕鬆執行。
首先,我們將安裝三個必要的庫——transformers、torch 和 accelerate,這些庫是用來無縫加載和運行強大的 NLP 模型。Transformers 提供了預建的 NLP 模型,torch 是深度學習任務的後端,而 accelerate 確保在 GPU 上高效利用資源。
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import pandas as pd
import matplotlib.pyplot as plt
接下來,我們將導入所需的 Python 庫。我們將使用 torch 進行高效的張量運算,使用 transformers 從 Hugging Face 加載預訓練的 NLP 模型,使用 pandas 管理和處理結構化數據,並使用 matplotlib 來清晰直觀地解釋分析結果。
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map=’auto’,
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
generator = pipeline(“text-generation”, model=model, tokenizer=tokenizer)
在這裡,我們將使用 Hugging Face 的 AutoTokenizer 和 AutoModelForCausalLM 載入 IBM 的開源 Granite 3B 指令跟隨模型,具體是 ibm-granite/granite-3.0-3b-a800m-instruct。這個緊湊的指令調整模型被優化來直接在 Colab 中處理情感分類等任務,即使在有限的計算資源下也能運行。
prompt = f”””將以下評論的情感分類為正面、負面或中立。
評論: “{review}”
情感:”””
response = generator(
prompt,
max_new_tokens=5,
do_sample=False,
pad_token_id=tokenizer.eos_token_id
)
sentiment = response[0][‘generated_text’].split(“情感:”)[-1].split(“n”)[0].strip()
return sentiment
現在我們將定義核心函數 classify_sentiment。這個函數利用 IBM Granite 3B 模型,通過基於指令的提示來將任何給定的評論分類為正面、負面或中立。這個函數格式化輸入評論,使用精確的指令調用模型,並從生成的文本中提取結果情感。
reviews = [
“我非常喜歡這項服務!肯定會再來。”,
“物品到達時損壞,感到非常失望。”,
“普通產品,沒什麼特別的。”,
“超級棒的體驗,超出了所有期望!”,
“不值得這個價格,質量差。”
]
reviews_df = pd.DataFrame(reviews, columns=[‘review’])
接下來,我們將使用 Pandas 創建一個簡單的 DataFrame reviews_df,裡面包含一組示例評論。這些示例評論作為情感分類的輸入數據,讓我們能夠觀察 IBM Granite 模型在實際情況下如何有效地判斷客戶情感。
print(reviews_df)
在定義了評論之後,我們將對 DataFrame 中的每個評論應用 classify_sentiment 函數。這將生成一個新的列 sentiment,IBM Granite 模型將每個評論分類為正面、負面或中立。通過打印更新後的 reviews_df,我們可以看到原始文本及其對應的情感分類。
sentiment_counts = reviews_df[‘sentiment’].value_counts()
plt.figure(figsize=(8, 6))
sentiment_counts.plot.pie(autopct=”%1.1f%%”, explode=[0.05]*len(sentiment_counts), colors=[‘#66bb6a’, ‘#ff7043’, ‘#42a5f5’])
plt.ylabel(”)
plt.title(‘評論情感分佈’)
plt.show()
最後,我們將在餅圖中可視化情感分佈。這一步提供了一個清晰直觀的概覽,讓我們更容易理解模型的整體表現。Matplotlib 讓我們能夠快速看到正面、負面和中立情感的比例,讓你的情感分析流程完整。
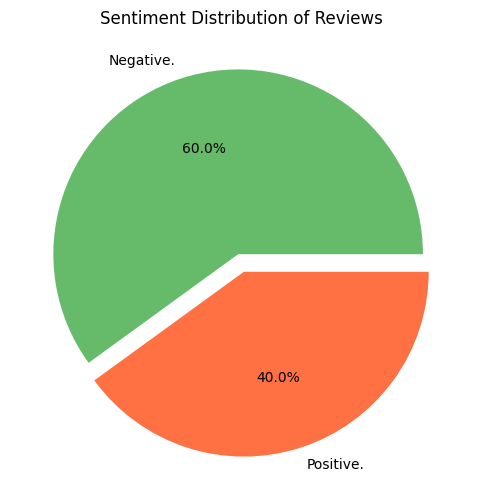
總結來說,我們成功地使用 IBM 的 Granite 3B 開源模型在 Hugging Face 上實現了一個強大的情感分析流程。你學會了如何利用預訓練模型快速將文本分類為正面、負面或中立情感,有效地可視化見解,並解釋你的發現。這種基礎方法使你能夠輕鬆地將這些技能應用於分析數據集或探索其他 NLP 任務。IBM 的 Granite 模型結合 Hugging Face Transformers 提供了一種高效的方式來執行先進的 NLP 任務。
這是 Colab 筆記本。還有,別忘了在 Twitter 上關注我們,加入我們的 Telegram 頻道和 LinkedIn 群組。別忘了加入我們的 80k+ ML SubReddit。
🚨 推薦閱讀 – LG AI 研究發布 NEXUS:一個先進的系統,整合代理 AI 系統和數據合規標準,以解決 AI 數據集中的法律問題。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!



")




{kind=link}