


大型語言模型如何改變語言處理
大型語言模型透過自我監督的預訓練,利用大量的文本數據,徹底改變了自然語言處理的方式。受到這一成功的啟發,研究人員開始探索複雜的語音標記方法,將連續的語音信號轉換成離散的標記,這樣就可以將語言建模技術應用於語音數據中。然而,現有的方法要麼專注於語義(內容)標記,可能會失去聲音的資訊;要麼專注於聲學標記,則有可能失去語義(內容)資訊。擁有多種標記類型也使得架構變得複雜,並需要額外的預訓練。
dMel的簡單表示法
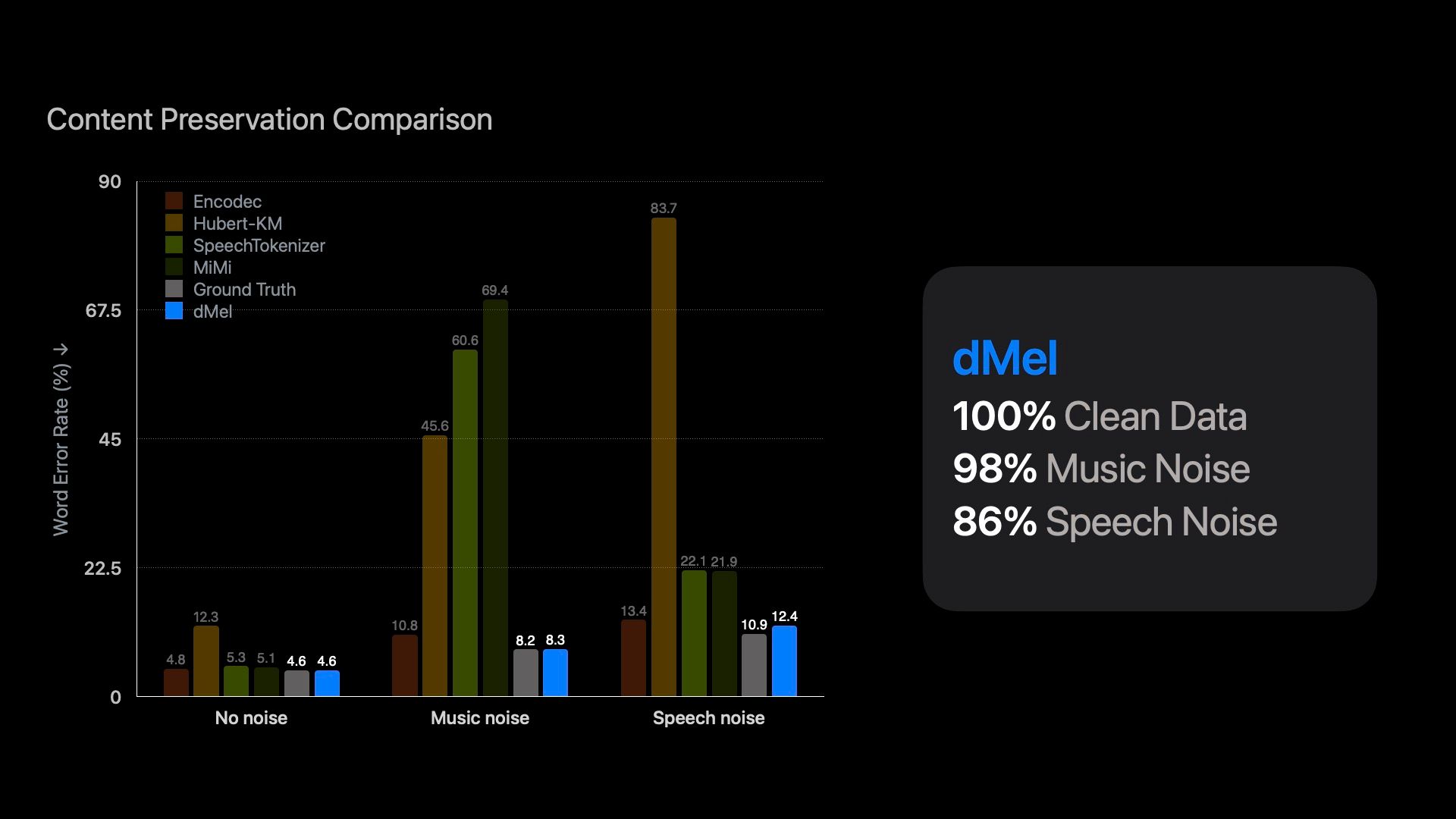
我們展示了一種新的方法,將梅爾濾波器頻道離散化為離散的強度區間,這種表示法稱為dMel,並且它的表現優於其他現有的語音標記方法。我們使用一種LM風格的變壓器架構來進行語音與文本的建模,全面評估了不同的語音標記方法在語音識別(ASR)和語音合成(TTS)上的表現。我們的結果顯示,dMel在這兩個任務中都能在統一的框架內達到高效能,為語音和文本的有效聯合建模鋪平了道路。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!



")




{kind=link}