


幾年前,我進入了動漫的世界,從此無法自拔。隨著我的觀影清單越來越少,找到下一部好看的動漫變得越來越困難。市面上有這麼多隱藏的寶石,我該如何發現它們呢?這時我想到——為什麼不讓機器學習的老師來做這些繁重的工作呢?聽起來很興奮,對吧?
在我們的數位時代,推薦系統就像是默默無聞的娛樂英雄,為我們的日常網上體驗提供支持。無論是建議電視劇、創建個性化的音樂播放列表,還是根據瀏覽歷史推薦產品,這些算法在背後運行,以提高用戶的參與度。
這篇指南將帶你建立一個隨時運行的動漫推薦引擎,無需傳統的雲平台。透過實際案例、代碼片段和詳細的架構探索,你將能夠建立和部署自己的推薦引擎。
學習目標
- 了解整個數據處理和模型訓練的工作流程,以確保效率和可擴展性。
- 在 Hugging Face Spaces 上建立和部署一個引人入勝的用戶友好推薦系統,並擁有動態介面。
- 獲得使用機器學習方法(如 SVD、協同過濾和基於內容的過濾)開發端到端推薦引擎的實踐經驗。
- 使用 Docker 無縫容器化你的項目,以便在不同環境中保持一致的部署。
- 在一個互動應用中結合各種推薦策略,以提供個性化的推薦。
這篇文章是作為數據科學博客馬拉松的一部分發表的。
使用 Hugging Face 的動漫推薦系統:數據收集
任何推薦系統的基礎在於高質量的數據。對於這個項目,數據集來自 Kaggle,然後存儲在 Hugging Face 數據集中心,以便於訪問和整合。主要使用的數據集包括:
- 動漫:詳細描述動漫標題及相關元數據的數據集。
- Anime_UserRatings:每部動漫的用戶評分數據。
- UserRatings:提供觀影習慣見解的一般用戶評分。
動漫推薦應用的前置條件
在開始之前,請確保你已完成以下步驟:
1. 註冊並登錄
- 前往 Hugging Face,如果你還沒有帳號,請創建一個。
- 登錄到你的 Hugging Face 帳號,以訪問 Spaces 部分。
2. 創建一個新空間
- 從你的個人資料或儀表板導航到“Spaces”部分。
- 點擊“創建新空間”按鈕。
- 為你的空間提供一個唯一的名稱,並選擇“Streamlit”作為應用介面。
- 根據你的喜好將空間設置為公開或私有。
3. 克隆空間庫
創建空間後,你將被重定向到新空間的庫頁面。
使用以下命令將庫克隆到你的本地機器:
git clone https://huggingface.co/spaces/your-username/your-space-name4. 設置虛擬環境
導航到你的項目目錄,並使用 Python 的內建 venv 工具創建一個新的虛擬環境。
# 創建虛擬環境
## 對於 macOS 和 Linux:
python3 -m venv env
## 對於 Windows:
python -m venv env# 啟動環境
## 對於 macOS 和 Linux:
source env/bin/activate
## 對於 Windows:
.\env\Scripts\activate5. 安裝依賴項
在克隆的庫中,創建一個 requirements.txt 文件,列出你的應用所需的所有依賴項(例如,Streamlit、pandas 等)。
使用以下命令安裝依賴項:
pip install -r requirements.txt在深入代碼之前,了解系統的各個組件如何互動是至關重要的。請查看下面的項目架構。
文件結構
這個項目採用模塊化的文件結構,旨在符合行業標準,以確保可擴展性和可維護性。
ANIME-RECOMMENDATION-SYSTEM/ # 項目目錄
├── anime_recommender/ # 包含所有模塊的主包
│ │── __init__.py # 包初始化
│ │
│ ├── components/ # 推薦系統的核心組件
│ │ │── __init__.py # 包初始化
│ │ │── collaborative_recommender.py # 協同過濾模型
│ │ │── content_based_recommender.py # 基於內容的過濾模型
│ │ │── data_ingestion.py # 獲取和加載數據
│ │ │── data_transformation.py # 預處理和轉換數據
│ │ │── top_anime_recommenders.py # 過濾頂級動漫
│ │
│ ├── constant/
│ │ │── __init__.py # 存儲項目中使用的常量值
│ │
│ ├── entity/ # 定義結構化實體,如配置和工件
│ │ │── __init__.py
│ │ │── artifact_entity.py # 模型工件的數據結構
│ │ │── config_entity.py # 配置參數和設置
│ │
│ ├── exception/ # 自定義異常處理
│ │ │── __init__.py
│ │ │── exception.py # 處理錯誤和異常
│ │
│ ├── loggers/ # 日誌和監控設置
│ │ │── __init__.py
│ │ │── logging.py # 配置日誌設置
│ │
│ ├── model_trainer/ # 模型訓練腳本
│ │ │── __init__.py
│ │ │── collaborative_modelling.py # 訓練協同過濾模型
│ │ │── content_based_modelling.py # 訓練基於內容的模型
│ │ │── top_anime_filtering.py # 根據評分過濾頂級動漫
│ │
│ ├── pipelines/ # 端到端的機器學習管道
│ │ │── __init__.py
│ │ │── training_pipeline.py # 訓練管道
│ │
│ ├── utils/ # 實用函數
│ │ │── __init__.py
│ │ ├── main_utils/
│ │ │ │── __init__.py
│ │ │ │── utils.py # 用於特定處理的實用函數
├── notebooks/ # 用於探索性數據分析和實驗的 Jupyter 筆記本
│ ├── EDA.ipynb # 探索性數據分析
│ ├── final_ARS.ipynb # 最終實現筆記本
├── .gitattributes # Git 配置,用於處理文件格式
├── .gitignore # 指定在版本控制中忽略的文件
├── app.py # 主要 Streamlit 應用
├── Dockerfile # Docker 配置,用於容器化
├── README.md # 項目文檔
├── requirements.txt # 依賴項和庫
├── run_pipeline.py # 運行整個訓練管道
├── setup.py # 包安裝的設置腳本
常量
constant/__init__.py 文件定義了所有基本常量,例如文件路徑、目錄名稱和模型文件名。這些常量在數據獲取、轉換和模型訓練階段標準化配置,確保一致性、可維護性和對關鍵項目配置的輕鬆訪問。
"""定義訓練管道的常見常量變數"""
PIPELINE_NAME: str = "AnimeRecommender"
ARTIFACT_DIR: str = "Artifacts"
ANIME_FILE_NAME: str = "Animes.csv"
RATING_FILE_NAME: str = "UserRatings.csv"
MERGED_FILE_NAME: str = "Anime_UserRatings.csv"
ANIME_FILE_PATH: str = "krishnaveni76/Animes"
RATING_FILE_PATH: str = "krishnaveni76/UserRatings"
ANIMEUSERRATINGS_FILE_PATH: str = "krishnaveni76/Anime_UserRatings"
MODELS_FILEPATH = "krishnaveni76/anime-recommendation-models"
"""數據獲取相關常量以 DATA_INGESTION 變量名稱開頭"""
DATA_INGESTION_DIR_NAME: str = "data_ingestion"
DATA_INGESTION_FEATURE_STORE_DIR: str = "feature_store"
DATA_INGESTION_INGESTED_DIR: str = "ingested"
"""數據轉換相關常量以 DATA_VALIDATION 變量名稱開頭"""
DATA_TRANSFORMATION_DIR: str = "data_transformation"
DATA_TRANSFORMATION_TRANSFORMED_DATA_DIR: str = "transformed"
"""模型訓練相關常量以 MODEL TRAINER 變量名稱開頭"""
MODEL_TRAINER_DIR_NAME: str = "trained_models"
MODEL_TRAINER_COL_TRAINED_MODEL_DIR: str = "collaborative_recommenders"
MODEL_TRAINER_SVD_TRAINED_MODEL_NAME: str = "svd.pkl"
MODEL_TRAINER_ITEM_KNN_TRAINED_MODEL_NAME: str = "itembasedknn.pkl"
MODEL_TRAINER_USER_KNN_TRAINED_MODEL_NAME: str = "userbasedknn.pkl"
MODEL_TRAINER_CON_TRAINED_MODEL_DIR: str = "content_based_recommenders"
MODEL_TRAINER_COSINESIMILARITY_MODEL_NAME: str = "cosine_similarity.pkl"
實用工具
utils/main_utils/utils.py 文件包含用於數據保存/加載、導出數據框、保存模型和上傳模型到 Hugging Face 的實用函數。這些可重用的函數簡化了整個項目的流程。
def export_data_to_dataframe(dataframe: pd.DataFrame, file_path: str) -> pd.DataFrame:
dir_path = os.path.dirname(file_path)
os.makedirs(dir_path, exist_ok=True)
dataframe.to_csv(file_path, index=False, header=True)
return dataframe
def load_csv_data(file_path: str) -> pd.DataFrame:
df = pd.read_csv(file_path)
return df
def save_model(model: object, file_path: str) -> None:
os.makedirs(os.path.dirname(file_path), exist_ok=True)
with open(file_path, "wb") as file_obj:
joblib.dump(model, file_obj)
def load_object(file_path: str) -> object:
if not os.path.exists(file_path):
error_msg = f"文件:{file_path} 不存在。"
raise Exception(error_msg)
with open(file_path, "rb") as file_obj:
return joblib.load(file_obj)
def upload_model_to_huggingface(model_path: str, repo_id: str, filename: str):
api = HfApi()
api.upload_file(path_or_fileobj=model_path, path_in_repo=filename, repo_id=repo_id, repo_type="model")
配置設置
entity/config_entity.py 文件保存了訓練管道不同階段的配置細節。這包括數據獲取、轉換和模型訓練的路徑,適用於協同和基於內容的推薦系統。這些配置確保了整個項目的結構化和有序工作流程。
class TrainingPipelineConfig:
def __init__(self, timestamp=datetime.now()):
timestamp = timestamp.strftime("%m_%d_%Y_%H_%M_%S")
self.pipeline_name = PIPELINE_NAME
self.artifact_dir = os.path.join(ARTIFACT_DIR, timestamp)
self.model_dir = os.path.join("final_model")
self.timestamp: str = timestamp
class DataIngestionConfig:
def __init__(self, training_pipeline_config: TrainingPipelineConfig):
self.data_ingestion_dir: str = os.path.join(training_pipeline_config.artifact_dir, DATA_INGESTION_DIR_NAME)
self.feature_store_anime_file_path: str = os.path.join(self.data_ingestion_dir, DATA_INGESTION_FEATURE_STORE_DIR, ANIME_FILE_NAME)
self.feature_store_userrating_file_path: str = os.path.join(self.data_ingestion_dir, DATA_INGESTION_FEATURE_STORE_DIR, RATING_FILE_NAME)
self.anime_filepath: str = ANIME_FILE_PATH
self.rating_filepath: str = RATING_FILE_PATH
class DataTransformationConfig:
def __init__(self, training_pipeline_config: TrainingPipelineConfig):
self.data_transformation_dir: str = os.path.join(training_pipeline_config.artifact_dir, DATA_TRANSFORMATION_DIR)
self.merged_file_path: str = os.path.join(self.data_transformation_dir, DATA_TRANSFORMATION_TRANSFORMED_DATA_DIR, MERGED_FILE_NAME)
class CollaborativeModelConfig:
def __init__(self, training_pipeline_config: TrainingPipelineConfig):
self.model_trainer_dir: str = os.path.join(training_pipeline_config.artifact_dir, MODEL_TRAINER_DIR_NAME)
self.svd_trained_model_file_path: str = os.path.join(self.model_trainer_dir, MODEL_TRAINER_COL_TRAINED_MODEL_DIR, MODEL_TRAINER_SVD_TRAINED_MODEL_NAME)
self.user_knn_trained_model_file_path: str = os.path.join(self.model_trainer_dir, MODEL_TRAINER_COL_TRAINED_MODEL_DIR, MODEL_TRAINER_USER_KNN_TRAINED_MODEL_NAME)
self.item_knn_trained_model_file_path: str = os.path.join(self.model_trainer_dir, MODEL_TRAINER_COL_TRAINED_MODEL_DIR, MODEL_TRAINER_ITEM_KNN_TRAINED_MODEL_NAME)
class ContentBasedModelConfig:
def __init__(self, training_pipeline_config: TrainingPipelineConfig):
self.model_trainer_dir: str = os.path.join(training_pipeline_config.artifact_dir, MODEL_TRAINER_DIR_NAME)
self.cosine_similarity_model_file_path: str = os.path.join(self.model_trainer_dir, MODEL_TRAINER_CON_TRAINED_MODEL_DIR, MODEL_TRAINER_COSINESIMILARITY_MODEL_NAME)
工件實體
entity/artifact_entity.py 文件定義了在各個階段生成的工件類。這些工件有助於跟踪和管理中間輸出,例如處理過的數據集和訓練模型。
@dataclass
class DataIngestionArtifact:
feature_store_anime_file_path: str
feature_store_userrating_file_path: str
@dataclass
class DataTransformationArtifact:
merged_file_path: str
@dataclass
class CollaborativeModelArtifact:
svd_file_path: str
item_based_knn_file_path: str
user_based_knn_file_path: str
@dataclass
class ContentBasedModelArtifact:
cosine_similarity_model_file_path: str
推薦系統 – 模型訓練
在這個項目中,我們實現了三種類型的推薦系統,以增強動漫推薦體驗:
- 協同推薦系統
- 基於內容的推薦系統
- 頂級動漫推薦系統
每種方法在提供個性化推薦方面都扮演著獨特的角色。通過分解每個組件,我們將獲得更深入的理解。
1. 協同推薦系統
這個協同推薦系統根據其他用戶的偏好和行為向用戶建議項目。它的運作假設是,如果兩個用戶在過去顯示出相似的興趣,那麼他們在未來也可能有相似的偏好。這種方法廣泛應用於 Netflix、Amazon 和動漫推薦引擎等平台,以提供個性化的建議。在我們的案例中,我們應用這種推薦技術來識別具有相似偏好的用戶,並根據他們的共同興趣建議動漫。
我們將遵循以下工作流程來構建我們的推薦系統。每一步都經過精心設計,以確保無縫集成,從數據收集開始,然後是轉換,最後訓練一個模型以生成有意義的推薦。
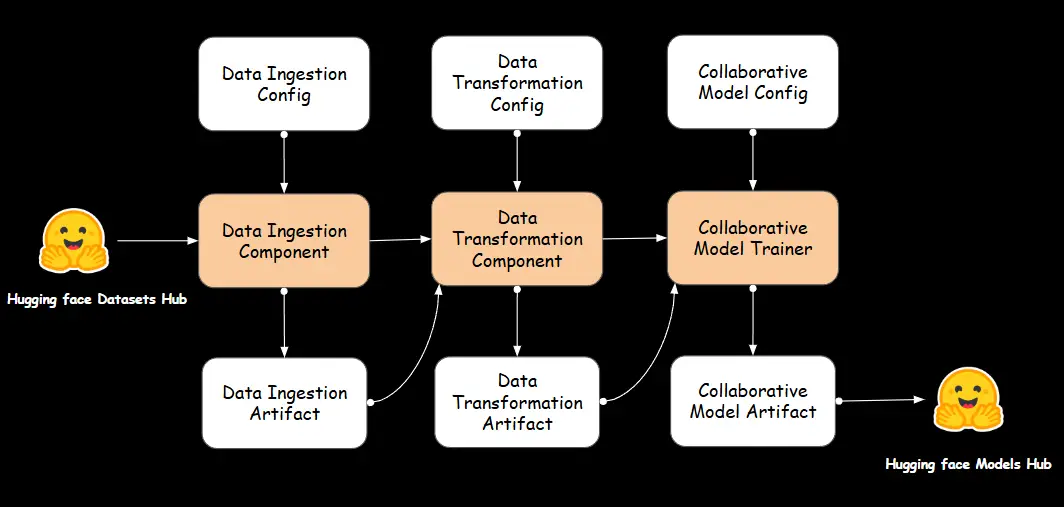
A. 數據獲取
數據獲取是將數據從各種來源收集、導入和轉移到數據存儲系統或管道中的過程,以便進一步處理和分析。這是任何數據驅動應用中的關鍵第一步,因為它使系統能夠訪問和處理生成見解、訓練模型或執行其他任務所需的原始數據。
數據獲取組件
我們在 components/data_ingestion.py 文件中定義了一個 DataIngestion 類,該類處理從 Hugging Face 數據集中心獲取數據集並將其加載到 Pandas DataFrame 中的過程。它利用 DataIngestionConfig 獲取獲取過程所需的文件路徑和配置。ingest_data 方法加載動漫和用戶評分數據集,將其導出為 CSV 文件到特徵存儲,並返回一個包含已獲取文件路徑的 DataIngestionArtifact。這個類封裝了數據獲取邏輯,確保數據被正確獲取、存儲並可供管道的後續階段訪問。
class DataIngestion:
def __init__(self, data_ingestion_config: DataIngestionConfig):
self.data_ingestion_config = data_ingestion_config
def fetch_data_from_huggingface(self, dataset_path: str, split: str = None) -> pd.DataFrame:
dataset = load_dataset(dataset_path, split=split)
df = pd.DataFrame(dataset['train'])
return df
def ingest_data(self) -> DataIngestionArtifact:
anime_df = self.fetch_data_from_huggingface(self.data_ingestion_config.anime_filepath)
rating_df = self.fetch_data_from_huggingface(self.data_ingestion_config.rating_filepath)
export_data_to_dataframe(anime_df, file_path=self.data_ingestion_config.feature_store_anime_file_path)
export_data_to_dataframe(rating_df, file_path=self.data_ingestion_config.feature_store_userrating_file_path)
dataingestionartifact = DataIngestionArtifact(
feature_store_anime_file_path=self.data_ingestion_config.feature_store_anime_file_path,
feature_store_userrating_file_path=self.data_ingestion_config.feature_store_userrating_file_path
)
return dataingestionartifact
B. 數據轉換
數據轉換是將原始數據轉換為適合分析、建模或集成到系統中的格式或結構的過程。這是數據預處理管道中的關鍵步驟,特別是對於機器學習,因為它有助於確保數據乾淨、一致,並以模型能有效使用的方式格式化。
數據轉換組件
在 components/data_transformation.py 文件中,我們實現了 DataTransformation 類,以管理將原始數據轉換為清理和合併的數據集,準備進一步處理。該類包括從 CSV 文件讀取數據、合併兩個數據集(動漫和評分)、清理和過濾合併數據的方法。具體而言,merge_data 方法根據共同列(anime_id)合併數據集,而 clean_filter_data 方法處理替換缺失值、將列轉換為數值類型、根據條件過濾行和刪除不必要的列等任務。initiate_data_transformation 方法協調整個轉換過程,使用 DataTransformationArtifact 實體將結果轉換後的數據集存儲在指定位置。
class DataTransformation:
def __init__(self, data_ingestion_artifact: DataIngestionArtifact, data_transformation_config: DataTransformationConfig):
self.data_ingestion_artifact = data_ingestion_artifact
self.data_transformation_config = data_transformation_config
@staticmethod
def read_data(file_path) -> pd.DataFrame:
return pd.read_csv(file_path)
@staticmethod
def merge_data(anime_df: pd.DataFrame, rating_df: pd.DataFrame) -> pd.DataFrame:
merged_df = pd.merge(rating_df, anime_df, on="anime_id", how="inner")
return merged_df
@staticmethod
def clean_filter_data(merged_df: pd.DataFrame) -> pd.DataFrame:
merged_df['average_rating'].replace('UNKNOWN', np.nan)
merged_df['average_rating'] = pd.to_numeric(merged_df['average_rating'], errors="coerce")
merged_df['average_rating'].fillna(merged_df['average_rating'].median())
merged_df = merged_df[merged_df['average_rating'] > 6]
cols_to_drop = [ 'username', 'overview', 'type', 'episodes', 'producers', 'licensors', 'studios', 'source', 'rank', 'popularity', 'favorites', 'scored by', 'members' ]
cleaned_df = merged_df.copy()
cleaned_df.drop(columns=cols_to_drop, inplace=True)
return cleaned_df
def initiate_data_transformation(self) -> DataTransformationArtifact:
anime_df = DataTransformation.read_data(self.data_ingestion_artifact.feature_store_anime_file_path)
rating_df = DataTransformation.read_data(self.data_ingestion_artifact.feature_store_userrating_file_path)
merged_df = DataTransformation.merge_data(anime_df, rating_df)
transformed_df = DataTransformation.clean_filter_data(merged_df)
export_data_to_dataframe(transformed_df, self.data_transformation_config.merged_file_path)
data_transformation_artifact = DataTransformationArtifact( merged_file_path=self.data_transformation_config.merged_file_path)
return data_transformation_artifact
C. 協同推薦器
協同過濾廣泛應用於推薦系統,根據用戶與項目的互動而不是項目的顯式特徵來進行預測。
協同建模
CollaborativeAnimeRecommender 類旨在使用協同過濾技術提供個性化的動漫推薦。它使用三種不同的模型:
- 奇異值分解 (SVD):一種矩陣分解技術,學習表示用戶偏好和動漫特徵的潛在因素,使基於過去評分的個性化推薦成為可能。
- 基於項目的 K 最近鄰 (KNN):根據用戶評分模式找到相似的動漫標題,推薦與給定動漫相似的節目。
- 基於用戶的 K 最近鄰 (KNN):識別具有相似偏好的用戶,並建議那些志同道合的用戶喜歡的動漫。
該類處理原始用戶評分,構建交互矩陣,並訓練模型以生成量身定制的推薦。推薦器為個別用戶提供預測,推薦相似的動漫標題,並根據用戶相似性建議新節目。通過利用協同過濾技術,該系統通過提供個性化和相關的動漫推薦來增強用戶體驗。
class CollaborativeAnimeRecommender:
def __init__(self, df):
self.df = df
self.svd = None
self.knn_item_based = None
self.knn_user_based = None
self.prepare_data()
def prepare_data(self):
self.df = self.df.drop_duplicates()
reader = Reader(rating_scale=(1, 10))
self.data = Dataset.load_from_df(self.df[['user_id', 'anime_id', 'rating']], reader)
self.anime_pivot = self.df.pivot_table(index='name', columns="user_id", values="rating").fillna(0)
self.user_pivot = self.df.pivot_table(index='user_id', columns="name", values="rating").fillna(0)
def train_svd(self):
self.svd = SVD()
cross_validate(self.svd, self.data, cv=5)
trainset = self.data.build_full_trainset()
self.svd.fit(trainset)
def train_knn_item_based(self):
item_user_matrix = csr_matrix(self.anime_pivot.values)
self.knn_item_based = NearestNeighbors(metric="cosine", algorithm='brute')
self.knn_item_based.fit(item_user_matrix)
def train_knn_user_based(self):
user_item_matrix = csr_matrix(self.user_pivot.values)
self.knn_user_based = NearestNeighbors(metric="cosine", algorithm='brute')
self.knn_user_based.fit(user_item_matrix)
def print_unique_user_ids(self):
unique_user_ids = self.df['user_id'].unique()
return unique_user_ids
def get_svd_recommendations(self, user_id, n=10, svd_model=None) -> pd.DataFrame:
svd_model = svd_model or self.svd
if svd_model is None:
raise ValueError("SVD 模型未提供或未訓練。")
if user_id not in self.df['user_id'].unique():
return f"用戶 ID '{user_id}' 在數據集中未找到。"
anime_ids = self.df['anime_id'].unique()
predictions = [(anime_id, svd_model.predict(user_id, anime_id).est) for anime_id in anime_ids]
predictions.sort(key=lambda x: x[1], reverse=True)
recommended_anime_ids = [pred[0] for pred in predictions[:n]]
recommended_anime = self.df[self.df['anime_id'].isin(recommended_anime_ids)].drop_duplicates(subset="anime_id")
recommended_anime = recommended_anime.head(n)
return pd.DataFrame({ '動漫名稱': recommended_anime['name'].values, '類型': recommended_anime['genres'].values, '圖片網址': recommended_anime['image url'].values, '評分': recommended_anime['average_rating'].values})
def get_item_based_recommendations(self, anime_name, n_recommendations=10, knn_item_model=None):
knn_item_based = knn_item_model or self.knn_item_based
if knn_item_based is None:
raise ValueError("基於項目的 KNN 模型未提供或未訓練。")
if anime_name not in self.anime_pivot.index:
return f"動漫標題 '{anime_name}' 在數據集中未找到。"
query_index = self.anime_pivot.index.get_loc(anime_name)
distances, indices = knn_item_based.kneighbors(self.anime_pivot.iloc[query_index, :].values.reshape(1, -1), n_neighbors=n_recommendations + 1)
recommendations = []
for i in range(1, len(distances.flatten())):
anime_title = self.anime_pivot.index[indices.flatten()[i]]
distance = distances.flatten()[i]
recommendations.append((anime_title, distance))
recommended_anime_titles = [rec[0] for rec in recommendations]
filtered_df = self.df[self.df['name'].isin(recommended_anime_titles)].drop_duplicates(subset="name")
filtered_df = filtered_df.head(n_recommendations)
return pd.DataFrame({ '動漫名稱': filtered_df['name'].values, '圖片網址': filtered_df['image url'].values, '類型': filtered_df['genres'].values, '評分': filtered_df['average_rating'].values })
def get_user_based_recommendations(self, user_id, n_recommendations=10, knn_user_model=None) -> pd.DataFrame:
knn_user_based = knn_user_model or self.knn_user_based
if knn_user_based is None:
raise ValueError("基於用戶的 KNN 模型未提供或未訓練。")
user_id = float(user_id)
if user_id not in self.user_pivot.index:
return f"用戶 ID '{user_id}' 在數據集中未找到。"
user_idx = self.user_pivot.index.get_loc(user_id)
distances, indices = knn_user_based.kneighbors(self.user_pivot.iloc[user_idx, :].values.reshape(1, -1), n_neighbors=n_recommendations + 1)
user_rated_anime = set(self.user_pivot.columns[self.user_pivot.iloc[user_idx, :] > 0])
all_neighbor_ratings = []
for i in range(1, len(distances.flatten())):
neighbor_idx = indices.flatten()[i]
neighbor_rated_anime = self.user_pivot.iloc[neighbor_idx, :]
neighbor_ratings = neighbor_rated_anime[neighbor_rated_anime > 0]
all_neighbor_ratings.extend(neighbor_ratings.index)
anime_counter = Counter(all_neighbor_ratings)
recommendations = [(anime, count) for anime, count in anime_counter.items() if anime not in user_rated_anime]
recommendations.sort(key=lambda x: x[1], reverse=True)
recommended_anime_titles = [rec[0] for rec in recommendations[:n_recommendations]]
filtered_df = self.df[self.df['name'].isin(recommended_anime_titles)].drop_duplicates(subset="name")
filtered_df = filtered_df.head(n_recommendations)
return pd.DataFrame({ '動漫名稱': filtered_df['name'].values, '圖片網址': filtered_df['image url'].values, '類型': filtered_df['genres'].values, '評分': filtered_df['average_rating'].values })
協同模型訓練器組件
CollaborativeModelTrainer 自動化模型的訓練、保存和部署。它確保訓練好的模型被本地存儲,並且也上傳到 Hugging Face,使其易於訪問以生成推薦。
class CollaborativeModelTrainer:
def __init__(self, collaborative_model_trainer_config: CollaborativeModelConfig, data_transformation_artifact: DataTransformationArtifact):
self.collaborative_model_trainer_config = collaborative_model_trainer_config
self.data_transformation_artifact = data_transformation_artifact
def initiate_model_trainer(self) -> CollaborativeModelArtifact:
df = load_csv_data(self.data_transformation_artifact.merged_file_path)
recommender = CollaborativeAnimeRecommender(df)
# 訓練並保存 SVD 模型
recommender.train_svd()
save_model(model=recommender.svd, file_path=self.collaborative_model_trainer_config.svd_trained_model_file_path)
upload_model_to_huggingface(
model_path=self.collaborative_model_trainer_config.svd_trained_model_file_path,
repo_id=MODELS_FILEPATH,
filename=MODEL_TRAINER_SVD_TRAINED_MODEL_NAME
)
svd_model = load_object(self.collaborative_model_trainer_config.svd_trained_model_file_path)
svd_recommendations = recommender.get_svd_recommendations(user_id=436, n=10, svd_model=svd_model)
# 訓練並保存基於項目的 KNN 模型
recommender.train_knn_item_based()
save_model(model=recommender.knn_item_based, file_path=self.collaborative_model_trainer_config.item_knn_trained_model_file_path)
upload_model_to_huggingface(
model_path=self.collaborative_model_trainer_config.item_knn_trained_model_file_path,
repo_id=MODELS_FILEPATH,
filename=MODEL_TRAINER_ITEM_KNN_TRAINED_MODEL_NAME
)
item_knn_model = load_object(self.collaborative_model_trainer_config.item_knn_trained_model_file_path)
item_based_recommendations = recommender.get_item_based_recommendations(
anime_name="One Piece", n_recommendations=10, knn_item_model=item_knn_model
)
# 訓練並保存基於用戶的 KNN 模型
recommender.train_knn_user_based()
save_model(model=recommender.knn_user_based, file_path=self.collaborative_model_trainer_config.user_knn_trained_model_file_path)
upload_model_to_huggingface(
model_path=self.collaborative_model_trainer_config.user_knn_trained_model_file_path,
repo_id=MODELS_FILEPATH,
filename=MODEL_TRAINER_USER_KNN_TRAINED_MODEL_NAME
)
user_knn_model = load_object(self.collaborative_model_trainer_config.user_knn_trained_model_file_path)
user_based_recommendations = recommender.get_user_based_recommendations(
user_id=817, n_recommendations=10, knn_user_model=user_knn_model
)
return CollaborativeModelArtifact(
svd_file_path=self.collaborative_model_trainer_config.svd_trained_model_file_path,
item_based_knn_file_path=self.collaborative_model_trainer_config.item_knn_trained_model_file_path,
user_based_knn_file_path=self.collaborative_model_trainer_config.user_knn_trained_model_file_path
)
2. 基於內容的推薦系統
這個基於內容的推薦系統通過分析項目的屬性(如類型、關鍵字或描述)來向用戶建議項目,以根據相似性生成推薦。
例如,在動漫推薦系統中,如果用戶喜歡某部動漫,模型會根據類型、配音演員或主題等屬性識別相似的動漫。TF-IDF(詞頻-逆文檔頻率)、餘弦相似度和機器學習模型等技術有助於對相關項目進行排名和建議。
與依賴用戶互動的協同過濾不同,基於內容的過濾獨立於其他用戶的偏好,即使在用戶互動較少的情況下(冷啟動問題)也能有效。
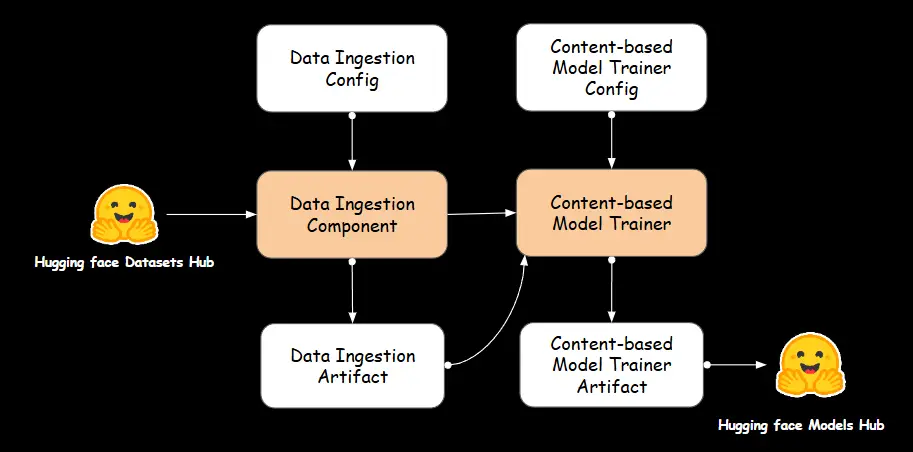
A. 數據獲取
我們使用之前討論的數據獲取組件中的工件來訓練基於內容的推薦器。
B. 基於內容的推薦器
基於內容的推薦器負責訓練分析項目屬性的推薦模型,以生成個性化的建議。它處理數據,提取相關特徵,並構建模型,根據內容識別項目之間的相似性。
基於內容的建模
ContentBasedRecommender 類利用 TF-IDF(詞頻-逆文檔頻率)和餘弦相似度來根據類型相似性建議動漫。該模型首先通過刪除缺失值和將文本類型信息轉換為數值特徵向量來處理數據集,然後計算動漫標題之間的餘弦相似度,以測量它們的內容相似性。訓練好的模型被保存,並在稍後根據給定標題檢索最相似的動漫以提供個性化推薦。
class ContentBasedRecommender:
def __init__(self, df):
self.df = df.dropna()
self.indices = pd.Series(self.df.index, index=self.df['name']).drop_duplicates()
self.tfv = TfidfVectorizer(min_df=3, strip_accents="unicode", analyzer="word", token_pattern=r'\w{1,}', ngram_range=(1, 3), stop_words="english")
self.tfv_matrix = self.tfv.fit_transform(self.df['genres'])
self.cosine_sim = cosine_similarity(self.tfv_matrix, self.tfv_matrix)
def save_model(self, model_path):
os.makedirs(os.path.dirname(model_path), exist_ok=True)
with open(model_path, 'wb') as f:
joblib.dump((self.tfv, self.cosine_sim), f)
def get_rec_cosine(self, title, model_path, n_recommendations=5):
with open(model_path, 'rb') as f:
self.tfv, self.cosine_sim = joblib.load(f)
if self.df is None:
raise ValueError("數據框未加載,無法進行推薦。")
if title not in self.indices.index:
return f"動漫標題 '{title}' 在數據集中未找到。"
idx = self.indicesHow to Build an Anime Recommendation System with Hugging Face?
cosinesim_scores = list(enumerate(self.cosine_sim[idx]))
cosinesim_scores = sorted(cosinesim_scores, key=lambda x: x[1], reverse=True)[1:n_recommendations + 1]
anime_indices = [i[0] for i in cosinesim_scores]
return pd.DataFrame({ '動漫名稱': self.df['name'].iloc[anime_indices].values, '圖片網址': self.df['image url'].iloc[anime_indices].values, '類型': self.df['genres'].iloc[anime_indices].values, '評分': self.df['average_rating'].iloc[anime_indices].values })
基於內容的模型訓練器組件
ContentBasedModelTrainer 類負責自動化基於內容的推薦模型的訓練和部署。它從數據獲取工件中加載處理過的動漫數據集,初始化 ContentBasedRecommender,並使用 TF-IDF 向量化和餘弦相似度進行訓練。訓練好的模型隨後被保存並上傳到 Hugging Face。
class ContentBasedModelTrainer:
def __init__(self, content_based_model_trainer_config: ContentBasedModelConfig, data_ingestion_artifact: DataIngestionArtifact):
self.content_based_model_trainer_config = content_based_model_trainer_config
self.data_ingestion_artifact = data_ingestion_artifact
def initiate_model_trainer(self) -> ContentBasedModelArtifact:
df = load_csv_data(self.data_ingestion_artifact.feature_store_anime_file_path)
recommender = ContentBasedRecommender(df=df )
recommender.save_model(model_path=self.content_based_model_trainer_config.cosine_similarity_model_file_path)
upload_model_to_huggingface(
model_path=self.content_based_model_trainer_config.cosine_similarity_model_file_path,
repo_id=MODELS_FILEPATH,
filename=MODEL_TRAINER_COSINESIMILARITY_MODEL_NAME
)
cosine_recommendations = recommender.get_rec_cosine(title="One Piece", model_path=self.content_based_model_trainer_config.cosine_similarity_model_file_path, n_recommendations=10)
content_model_trainer_artifact = ContentBasedModelArtifact(cosine_similarity_model_file_path=self.content_based_model_trainer_config.cosine_similarity_model_file_path)
return content_model_trainer_artifact
3. 頂級動漫推薦系統
對於動漫新手來說,通常會首先尋找最受歡迎的標題。這個頂級動漫推薦系統旨在幫助那些新進動漫世界的人輕鬆發現受歡迎、高評價和排名靠前的動漫,通過簡單的排序和過濾來實現。
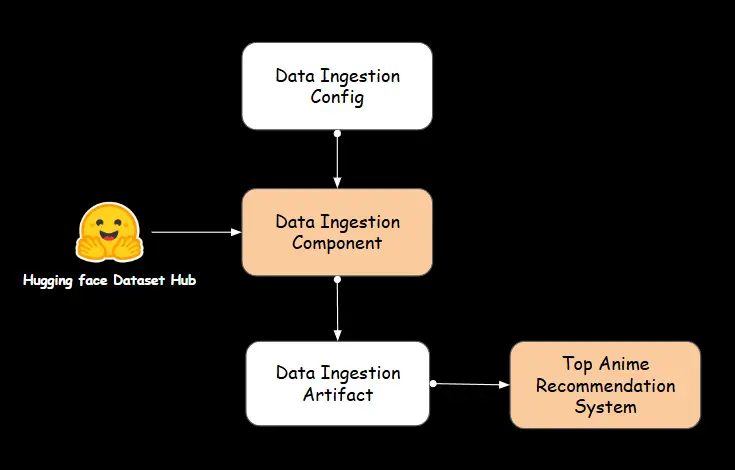
A. 數據獲取
我們在這個推薦系統中利用之前討論的數據獲取組件中的工件。
B. 頂級動漫推薦器組件
頂級動漫過濾
PopularityBasedFiltering 類負責使用預定義的基於人氣的參數對動漫進行排名和排序。它通過評估評分、收藏數、社區規模和排名位置等屬性來分析數據集。該類包括專門的函數,以提取每個類別中的表現最佳的動漫,確保過濾的結構化方法。此外,它管理缺失數據並優化輸出以提高可讀性。通過提供數據驅動的見解,這個類在識別受歡迎和高評價的動漫方面發揮了關鍵作用。
class PopularityBasedFiltering:
def __init__(self, df):
self.df = df
self.df['average_rating'] = pd.to_numeric(self.df['average_rating'], errors="coerce")
self.df['average_rating'].fillna(self.df['average_rating'].median())
def popular_animes(self, n=10):
sorted_df = self.df.sort_values(by=['popularity'], ascending=True)
top_n_anime = sorted_df.head(n)
return self._format_output(top_n_anime)
def top_ranked_animes(self, n=10):
self.df['rank'] = self.df['rank'].replace('UNKNOWN', np.nan).astype(float)
df_filtered = self.df[self.df['rank'] > 1]
sorted_df = df_filtered.sort_values(by=['rank'], ascending=True)
top_n_anime = sorted_df.head(n)
return self._format_output(top_n_anime)
def overall_top_rated_animes(self, n=10):
sorted_df = self.df.sort_values(by=['average_rating'], ascending=False)
top_n_anime = sorted_df.head(n)
return self._format_output(top_n_anime)
def favorite_animes(self, n=10):
sorted_df = self.df.sort_values(by=['favorites'], ascending=False)
top_n_anime = sorted_df.head(n)
return self._format_output(top_n_anime)
def top_animes_members(self, n=10):
sorted_df = self.df.sort_values(by=['members'], ascending=False)
top_n_anime = sorted_df.head(n)
return self._format_output(top_n_anime)
def popular_anime_among_members(self, n=10):
sorted_df = self.df.sort_values(by=['members', 'average_rating'], ascending=[False, False]).drop_duplicates(subset="name")
popular_animes = sorted_df.head(n)
return self._format_output(popular_animes)
def top_avg_rated(self, n=10):
self.df['average_rating'] = pd.to_numeric(self.df['average_rating'], errors="coerce")
median_rating = self.df['average_rating'].median()
self.df['average_rating'].fillna(median_rating)
top_animes = (self.df.drop_duplicates(subset="name").nlargest(n, 'average_rating')[['name', 'average_rating', 'image url', 'genres']])
return self._format_output(top_animes)
def _format_output(self, anime_df):
return pd.DataFrame({ '動漫名稱': anime_df['name'].values, '圖片網址': anime_df['image url'].values, '類型': anime_df['genres'].values, '評分': anime_df['average_rating'].values })
頂級動漫推薦器
PopularityBasedRecommendor 類負責根據不同的受歡迎指標推薦動漫。它利用存儲在 feature_store_anime_file_path 中的動漫數據集,這是 DataIngestionArtifact。該類整合了 PopularityBasedFiltering 類,以根據各種過濾標準生成動漫推薦,例如排名最高的動漫、最受歡迎的選擇、社區最愛和評分最高的節目。通過選擇特定的 filter_type,用戶可以根據他們的偏好標準檢索最佳匹配。
class PopularityBasedRecommendor:
def __init__(self, data_ingestion_artifact=DataIngestionArtifact):
self.data_ingestion_artifact = data_ingestion_artifact
def initiate_model_trainer(self, filter_type: str):
df = load_csv_data(self.data_ingestion_artifact.feature_store_anime_file_path)
recommender = PopularityBasedFiltering(df)
if filter_type == 'popular_animes':
popular_animes = recommender.popular_animes(n=10)
elif filter_type == 'top_ranked_animes':
top_ranked_animes = recommender.top_ranked_animes(n=10)
elif filter_type == 'overall_top_rated_animes':
overall_top_rated_animes = recommender.overall_top_rated_animes(n=10)
elif filter_type == 'favorite_animes':
favorite_animes = recommender.favorite_animes(n=10)
elif filter_type == 'top_animes_members':
top_animes_members = recommender.top_animes_members(n=10)
elif filter_type == 'popular_anime_among_members':
popular_anime_among_members = recommender.popular_anime_among_members(n=10)
elif filter_type == 'top_avg_rated':
top_avg_rated = recommender.top_avg_rated(n=10)
訓練管道
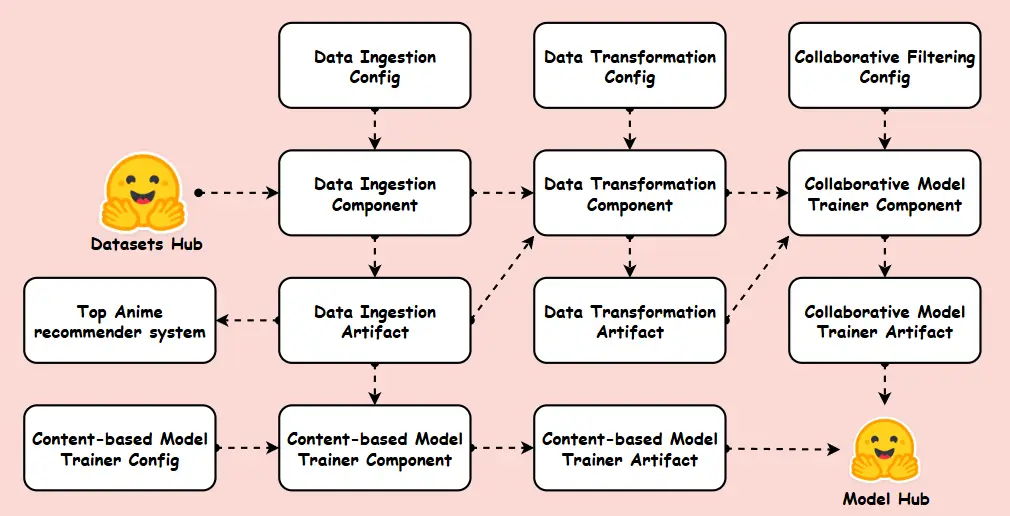
這個機器學習訓練管道旨在自動化和簡化推薦模型的構建過程。該管道遵循結構化工作流程,從 Hugging Face 獲取數據開始,然後進行數據轉換以預處理和準備數據進行模型訓練。它包含不同的建模技術,如協同過濾、基於內容的方法和基於人氣的過濾,確保最佳性能。最終訓練好的模型存儲在模型中心,實現無縫部署和持續改進。這種結構化方法確保了機器學習工作流程的可擴展性、效率和可重複性。
class TrainingPipeline:
def __init__(self):
self.training_pipeline_config = TrainingPipelineConfig()
def start_data_ingestion(self) -> DataIngestionArtifact:
data_ingestion_config = DataIngestionConfig(self.training_pipeline_config)
data_ingestion = DataIngestion(data_ingestion_config=data_ingestion_config)
data_ingestion_artifact = data_ingestion.ingest_data()
return data_ingestion_artifact
def start_data_transformation(self, data_ingestion_artifact: DataIngestionArtifact) -> DataTransformationArtifact:
data_transformation_config = DataTransformationConfig(self.training_pipeline_config)
data_transformation = DataTransformation(
data_ingestion_artifact=data_ingestion_artifact,
data_transformation_config=data_transformation_config
)
data_transformation_artifact = data_transformation.initiate_data_transformation()
return data_transformation_artifact
def start_collaborative_model_training(self, data_transformation_artifact: DataTransformationArtifact) -> CollaborativeModelArtifact:
collaborative_model_config = CollaborativeModelConfig(self.training_pipeline_config)
collaborative_model_trainer = CollaborativeModelTrainer(
collaborative_model_trainer_config=collaborative_model_config,
data_transformation_artifact=data_transformation_artifact )
collaborative_model_trainer_artifact = collaborative_model_trainer.initiate_model_trainer()
return collaborative_model_trainer_artifact
def start_content_based_model_training(self, data_ingestion_artifact: DataIngestionArtifact) -> ContentBasedModelArtifact:
content_based_model_config = ContentBasedModelConfig(self.training_pipeline_config)
content_based_model_trainer = ContentBasedModelTrainer(
content_based_model_trainer_config=content_based_model_config,
data_ingestion_artifact=data_ingestion_artifact )
content_based_model_trainer_artifact = content_based_model_trainer.initiate_model_trainer()
return content_based_model_trainer_artifact
def start_popularity_based_filtering(self, data_ingestion_artifact: DataIngestionArtifact):
filtering = PopularityBasedRecommendor(data_ingestion_artifact=data_ingestion_artifact)
recommendations = filtering.initiate_model_trainer(filter_type="popular_animes")
return recommendations
def run_pipeline(self):
# 數據獲取
data_ingestion_artifact = self.start_data_ingestion()
# 基於內容的模型訓練
content_based_model_trainer_artifact = self.start_content_based_model_training(data_ingestion_artifact)
# 基於人氣的過濾
popularity_recommendations = self.start_popularity_based_filtering(data_ingestion_artifact)
# 數據轉換
data_transformation_artifact = self.start_data_transformation(data_ingestion_artifact)
# 協同模型訓練
collaborative_model_trainer_artifact = self.start_collaborative_model_training(data_transformation_artifact)
現在我們已經完成了創建管道,使用以下代碼運行 training_pipeline.py 文件,以查看在之前步驟中生成的工件。
python training_pipeline.pyStreamlit 應用
這個推薦應用是使用 Streamlit 構建的,Streamlit 是一個輕量級的互動框架,用於創建數據驅動的網頁應用。它部署在 Hugging Face Spaces 上,讓用戶能夠無縫地探索和互動動漫推薦系統。這種設置提供了一個直觀的用戶界面,讓用戶能夠實時發現動漫推薦。每次你推送新更改時,Hugging Face 會自動重新部署你的應用。
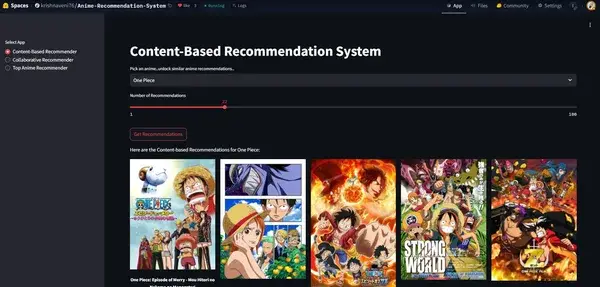
Docker 集成以進行部署
Dockerfile 設置了一個輕量級的 Python 環境,使用官方的 Python 3.10 slim-buster 映像。它配置工作目錄,複製應用文件,並從 requirements.txt 安裝依賴項。最後,它暴露 8501 端口並運行 Streamlit 應用,使其在容器化環境中可訪問。
# 使用官方 Python 映像作為基礎
FROM python:3.10-slim-buster
# 在容器中設置工作目錄
WORKDIR /app
# 將應用文件複製到容器中
COPY . .
# 安裝所需的包
RUN pip install -r requirements.txt
# 暴露 Streamlit 使用的端口
EXPOSE 8501
# 運行 Streamlit 應用
CMD ["streamlit", "run", "app.py", "--server.port=8501", "--server.address=0.0.0.0"]
關鍵要點
- 我們設計了一個高效的端到端管道,確保從獲取到推薦的數據流暢,使系統可擴展、穩健且準備好投入生產。
- 新用戶通過基於人氣的引擎獲得熱門動漫建議,而回歸用戶則通過協同過濾模型獲得超個性化的推薦。
- 通過在 Hugging Face Spaces 上進行部署,並使用模型版本控制,你可以在不支付任何 AWS/GCP 費用的情況下實現無成本的生產化,同時保持可擴展性!
- 該系統利用 Docker 進行容器化,確保在不同部署中保持一致的環境。
- 使用 Streamlit 構建的應用提供了乾淨、動態和引人入勝的用戶體驗,使動漫發現變得有趣和直觀。
這篇文章中顯示的媒體不屬於 Analytics Vidhya,並由作者自行決定使用。
結論
恭喜你!你已經在短時間內完成了推薦應用的構建。從獲取數據和預處理到模型訓練和部署,這個項目展示了將事物帶入世界的力量!但等等……我們還沒完成呢!💥 還有更多有趣的事情等著你!你現在已經準備好構建更酷的東西,比如電影推薦應用!
這只是我們共同冒險的開始,所以系好安全帶——還有許多更令人興奮的項目在前面等著我們!讓我們繼續學習和建設!
常見問題
答:當然可以!更換數據集,調整 constants.py 中的類型權重,瞧——你就能在短時間內擁有《魷魚遊戲》或 Marvel 推薦器!
答:可以!可以使用 random.choice() 輕鬆添加“驚喜我”按鈕,幫助用戶隨機發現隱藏的動漫寶石!
答:他們的免費層處理約 10K 的每月訪問量。如果你達到《鬼滅之刃》的流行程度,升級到 PRO(每月 9 美元)以獲得優先服務器。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!



")




{kind=link}