


在這篇文章中,我們將討論什麼是嵌入(embeddings),展示如何實際使用語言嵌入,並探索如何利用它們來增加功能,例如零樣本分類(zero-shot classification)和語義搜尋(semantic search)。接著,我們將使用亞馬遜基岩(Amazon Bedrock)和語言嵌入,將這些功能添加到一個非常簡單的RSS聚合器應用程式中。
亞馬遜基岩(Amazon Bedrock)是一個完全管理的服務,通過API提供來自領先AI初創公司的基礎模型(FMs)和亞馬遜的模型,讓你可以從各種模型中選擇,找到最適合你需求的模型。亞馬遜基岩提供無伺服器體驗,讓你可以快速開始,私下自訂FMs,並使用亞馬遜網路服務(AWS)將它們整合和部署到你的應用程式中,而無需管理基礎設施。在這篇文章中,我們使用亞馬遜基岩上的Cohere v3 Embed模型來創建我們的語言嵌入。
使用案例:RSS聚合器
為了展示這些語言嵌入的一些可能用途,我們開發了一個RSS聚合器網站。RSS是一種網路供應,允許出版物以標準化、計算機可讀的方式發布更新。在我們的網站上,使用者可以訂閱RSS供應,並獲得新文章的聚合和分類列表。我們使用嵌入來增加以下功能:
零樣本分類 – 文章根據不同主題進行分類。有一些預設主題,例如科技、政治和健康與福祉,如下圖所示。使用者也可以創建自己的主題。
語義搜尋 – 使用者可以使用語義搜尋來搜尋文章,如下圖所示。使用者不僅可以搜尋特定主題,還可以根據語氣或風格等因素縮小搜尋範圍。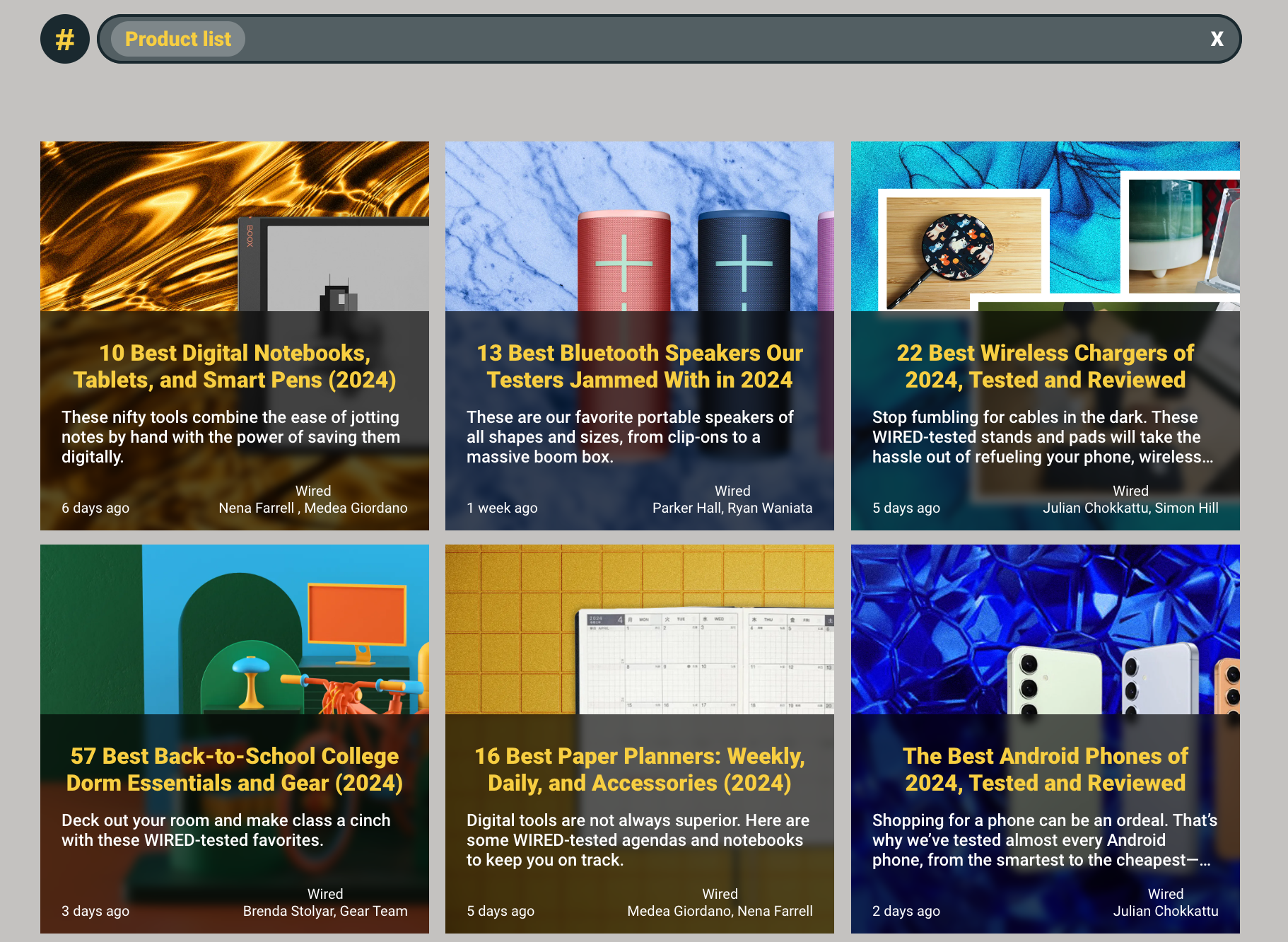
這篇文章使用這個應用程式作為參考點,討論語義搜尋和零樣本分類功能的技術實現。
解決方案概述
這個解決方案使用以下服務:
亞馬遜API閘道(Amazon API Gateway) – API可以通過亞馬遜API閘道訪問。對某些主題進行緩存,以減輕數據庫負擔。
亞馬遜基岩(Amazon Bedrock)與Cohere v3 Embed – 文章和主題通過亞馬遜基岩和Cohere v3 Embed轉換為嵌入。
亞馬遜CloudFront和亞馬遜簡單存儲服務(Amazon S3) – 單頁React應用程式使用亞馬遜S3和亞馬遜CloudFront進行託管。
亞馬遜Cognito – 使用亞馬遜Cognito用戶池進行身份驗證。
亞馬遜EventBridge – 使用亞馬遜EventBridge和EventBridge計劃來協調新更新。
AWS Lambda – API是一個用TypeScript編寫的Fastify應用程式,託管在AWS Lambda上。
亞馬遜Aurora PostgreSQL相容版本和pgvector – 亞馬遜Aurora PostgreSQL相容版本用作數據庫,既用於應用程式本身的功能,也用作使用pgvector的向量存儲。
亞馬遜RDS代理(Amazon RDS Proxy) – 用於連接池。
亞馬遜簡單佇列服務(Amazon SQS) – 用於佇列事件。它一次消耗一個事件,以避免觸及亞馬遜基岩中Cohere的速率限制。
以下圖示說明了解決方案架構。

什麼是嵌入?
這一部分提供了關於嵌入的簡單介紹,以及它們如何使用。
嵌入是概念或物體的數字表示,例如語言或圖像。在這篇文章中,我們討論語言嵌入。通過將這些概念簡化為數字表示,我們可以以計算機能理解和操作的方式使用它們。
讓我們以柏林(Berlin)和巴黎(Paris)為例。作為人類,我們理解這兩個詞之間的概念聯繫。柏林和巴黎都是城市,它們是各自國家的首都,並且都位於歐洲。我們幾乎本能地理解它們的概念相似性,因為我們可以在腦中創建一個世界模型。然而,計算機並沒有內建的方式來表示這些概念。
為了以計算機能理解的方式表示這些概念,我們將它們轉換為語言嵌入。語言嵌入是高維向量,通過神經網絡的訓練學習彼此之間的關係。在訓練過程中,神經網絡接觸到大量文本,並根據單詞在不同上下文中的共現和相互關係學習模式。
嵌入向量使計算機能夠從語言中建模世界。例如,如果我們嵌入“柏林”和“巴黎”,我們現在可以對這些嵌入進行數學運算。我們可以觀察到一些相當有趣的關係。例如,我們可以這樣做:巴黎 – 法國 + 德國 ≈ 柏林。這是因為這些嵌入捕捉了“巴黎”和“法國”之間的關係,以及“德國”和“柏林”之間的關係——具體來說,巴黎和柏林都是各自國家的首都。
以下圖表顯示了國家及其首都之間的詞向量距離。

從“法國”中減去“巴黎”去除了國家的語義,留下了一個代表首都城市概念的向量。將“德國”加到這個向量上,我們就得到了與“柏林”非常相似的東西,柏林是德國的首都。這一關係的向量在以下圖表中顯示。

對於我們的使用案例,我們使用亞馬遜基岩中的預訓練Cohere嵌入模型,該模型嵌入整個文本,而不是單個單詞。這些嵌入代表文本的意義,並可以通過數學運算進行操作。這一特性對於映射文本之間的相似性關係非常有用。
零樣本分類
我們使用語言嵌入的一種方式是利用它們的特性來計算一篇文章與某個主題的相似度。
為此,我們將一個主題分解為一系列不同且相關的嵌入。例如,對於文化,我們有一組關於運動、電視節目、音樂、書籍等的嵌入。然後,我們將RSS文章的標題和描述嵌入,並計算與主題嵌入的相似度。由此,我們可以為文章分配主題標籤。
以下圖示說明了這是如何運作的。Cohere生成的嵌入是高維的,包含1,024個值(或維度)。然而,為了演示這個系統的運作,我們使用一種旨在降低嵌入維度的算法,t-分佈隨機鄰居嵌入(t-SNE),以便我們可以在兩個維度中查看它們。以下圖像使用這些嵌入來可視化主題是如何根據相似性和意義聚類的。

你可以使用一篇文章的嵌入,檢查該文章與先前嵌入的相似性。然後,你可以說,如果一篇文章與這些嵌入聚類得很近,那麼它可以被標記為相關主題。
這是k最近鄰(k-NN)算法。這個算法用於執行分類和回歸任務。在k-NN中,你可以根據數據點與其他數據點的接近程度來做出假設。例如,你可以說,與前面圖中音樂主題接近的文章可以標記為文化主題。
以下圖示展示了這一點,使用了一篇來自ArsTechnica的文章。我們將文章的標題和描述的嵌入繪製出來:(氣候變化如此之快,以至於我們還沒有看到極端天氣可能有多糟糕:數十年的統計數據不再代表當今可能發生的情況)。

這種方法的優勢在於你可以添加自定義的用戶生成主題。你可以通過首先創建一系列概念相關項目的嵌入來創建一個主題。例如,一個AI主題將與AI、生成式AI、LLM和Anthropic的嵌入相似,如下圖所示。

在傳統的分類系統中,我們需要訓練一個分類器——這是一個監督學習任務,我們需要提供一系列示例來確定一篇文章是否屬於其相應的主題。這樣做可能是一個相當繁重的任務,需要標記數據和訓練模型。對於我們的使用案例,我們可以提供示例,創建聚類,並標記文章,而無需提供標記示例或訓練額外的模型。這在我們網站的結果頁面截圖中顯示。
在我們的應用程式中,我們定期獲取新文章。我們使用EventBridge計劃定期調用Lambda函數,檢查是否有新文章。如果有,它會使用亞馬遜基岩和Cohere創建嵌入。
我們計算文章與不同主題嵌入的距離,然後可以確定文章是否屬於該類別。這是通過Aurora PostgreSQL和pgvector來完成的。我們存儲主題的嵌入,然後使用以下SQL查詢計算它們的距離:
前面代碼中的<->運算符計算文章與主題嵌入之間的歐幾里得距離。這個數字讓我們了解一篇文章與某個主題的接近程度。然後,我們可以根據這個排名來確定主題的適當性。
然後,我們將文章標記為該主題。我們這樣做是為了讓後續對主題的請求在計算上儘可能輕便;我們進行簡單的聯接,而不是計算歐幾里得距離。
我們還緩存特定的主題/供應組合,因為這些是每小時計算一次,並且在此期間不預期會改變。
語義搜尋
如前所述,Cohere生成的嵌入包含多種特徵;它們嵌入了單詞或短語的意義和語義。我們還發現,我們可以對這些嵌入進行數學運算,以計算兩個短語或單詞之間的相似性。
我們可以使用這些嵌入,並使用k-NN算法計算搜尋詞與文章嵌入之間的相似性,以找到與我們提供的搜尋詞具有相似語義和意義的文章。
例如,在我們的一個RSS供應中,我們有很多不同的文章來評價產品。在傳統的搜尋系統中,我們會依賴關鍵字匹配來提供相關結果。雖然找到特定文章可能很簡單(例如,搜尋“最佳數位筆記本”),但我們需要另一種方法來捕捉多個產品列表文章。
在語義搜尋系統中,我們首先將“產品列表”這個詞轉換為嵌入。然後,我們可以利用這個嵌入的特性在我們的嵌入空間中進行搜尋。使用k-NN算法,我們可以找到語義相似的文章。如以下截圖所示,儘管在標題或描述中都沒有包含“產品列表”這個文本,我們仍然能找到包含產品列表的文章。這是因為我們能夠捕捉查詢的語義,並將其與我們為每篇文章擁有的現有嵌入進行匹配。
在我們的應用程式中,我們使用pgvector在Aurora PostgreSQL上存儲這些嵌入。pgvector是一個開源擴展,允許在PostgreSQL中進行向量相似性搜尋。我們使用亞馬遜基岩和Cohere v3 Embed將搜尋詞轉換為嵌入。
在我們將搜尋詞轉換為嵌入後,我們可以將其與在攝取過程中保存的文章嵌入進行比較。然後,我們可以使用pgvector找到聚類在一起的文章。相應的SQL代碼如下:
這段代碼計算主題與這篇文章的嵌入之間的距離,並將其視為“相似性”。如果這個距離接近,那麼我們可以假設這篇文章的主題是相關的,因此我們將主題附加到文章上。
前提條件
要在自己的帳戶中部署這個應用程式,你需要以下前提條件:
一個有效的AWS帳戶。
Cohere Embed English的模型訪問權限。在亞馬遜基岩控制台中,選擇導航窗格中的模型訪問,然後選擇管理模型訪問。選擇你選擇的FMs並請求訪問。

部署AWS CDK堆疊
當前提條件步驟完成後,你就可以設置解決方案:
克隆包含解決方案文件的GitHub庫:git clone https://github.com/aws-samples/rss-aggregator-using-cohere-embeddings-bedrock
進入解決方案目錄:cd infrastructure
在你的終端中,導出你的AWS憑證,對於ACCOUNT_ID中的角色或用戶。該角色需要擁有所有必要的AWS CDK部署權限:
export AWS_REGION=”<region>”– 你想要部署應用程式的AWS區域
export AWS_ACCESS_KEY_ID=”<access-key>”– 你的角色或用戶的訪問密鑰
export AWS_SECRET_ACCESS_KEY=”<secret-key>”– 你的角色或用戶的秘密密鑰
如果你是第一次部署AWS CDK,請運行以下命令:cdk bootstrap
要合成AWS CloudFormation模板,運行以下命令:cdk synth -c vpc_id=<你的VPC ID>
要部署,使用以下命令:cdk deploy -c vpc_id=<你的VPC ID>
當部署完成後,你可以通過訪問AWS CloudFormation控制台來檢查這些已部署的堆疊,如下圖所示。

清理
在終端中運行以下命令以刪除使用AWS CDK配置的CloudFormation堆疊:
cdk destroy –all
結論
在這篇文章中,我們探討了語言嵌入是什麼以及它們如何用來增強你的應用程式。我們學到了如何利用嵌入的特性,實現實時的零樣本分類器,並添加強大的功能,例如語義搜尋。
這個應用程式的代碼可以在附帶的GitHub庫中找到。我們鼓勵你嘗試語言嵌入,看看它們能為你的應用程式啟用哪些強大功能!
關於作者
 Thomas Rogers是一位位於荷蘭阿姆斯特丹的解決方案架構師。他擁有軟體工程背景。在AWS,Thomas幫助客戶構建雲解決方案,專注於現代化、數據和整合。
Thomas Rogers是一位位於荷蘭阿姆斯特丹的解決方案架構師。他擁有軟體工程背景。在AWS,Thomas幫助客戶構建雲解決方案,專注於現代化、數據和整合。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!



")




{kind=link}