


大型語言模型 (LLMs) 在精確計算、符號操作和算法任務上表現不佳,通常需要結構化的問題解決方法。雖然語言模型在語意理解和常識推理上有優勢,但它們並不具備處理需要高精度的操作的能力,例如數學問題解決或基於邏輯的決策。傳統方法試圖通過整合外部工具來彌補這些不足,但缺乏系統性的方法來判斷何時依賴符號計算與文本推理。
研究人員發現現有大型語言模型 (LLMs) 的一個根本限制:它們無法有效地在文本推理和代碼執行之間切換。這個問題的產生是因為大多數輸入提示並沒有明確指出一個問題是用自然語言還是符號計算來解決更好。雖然一些模型,例如 OpenAI 的 GPT 系列,整合了代碼解釋器等功能來解決這個問題,但它們未能有效引導文本和基於代碼的解決方案之間的轉換。挑戰不僅在於執行代碼,還在於知道何時生成代碼。LLMs 通常在缺乏這種能力的情況下默認使用基於文本的推理,導致在複雜問題解決場景中效率低下和錯誤的解決方案。
一些模型已經整合了外部框架來幫助 LLMs 生成和執行代碼。這些包括 OpenAI 的代碼解釋器和像 AutoGen 這樣的多代理框架,它們使用專門的提示來引導模型朝向適當的回應。然而,這些方法未能有效利用符號計算,因為它們並未系統性地微調 LLMs,以平衡代碼執行與自然語言推理。現有的方法提供的適應性有限,通常需要手動干預或特定領域的調整。因此,模型在需要文本和代碼混合問題解決的任務上仍然表現不佳。
來自麻省理工學院 (MIT)、哈佛大學、伊利諾伊大學香檳分校和 MIT-IBM Watson AI 實驗室的研究人員推出了一個名為 CodeSteer 的新框架,旨在引導 LLMs 有效地在基於文本的推理和符號計算之間切換。CodeSteer 微調語言模型,以優化代碼生成和文本推理。這種方法利用了一個新開發的基準,稱為 SymBench,包含 37 個符號任務,使研究人員能夠測量和改進模型處理結構化問題解決的能力。該框架整合了一個微調版本的 Llama-3-8B 模型,並進行多輪監督微調 (SFT) 和直接偏好優化 (DPO),使其在各種問題領域中具有高度適應性。
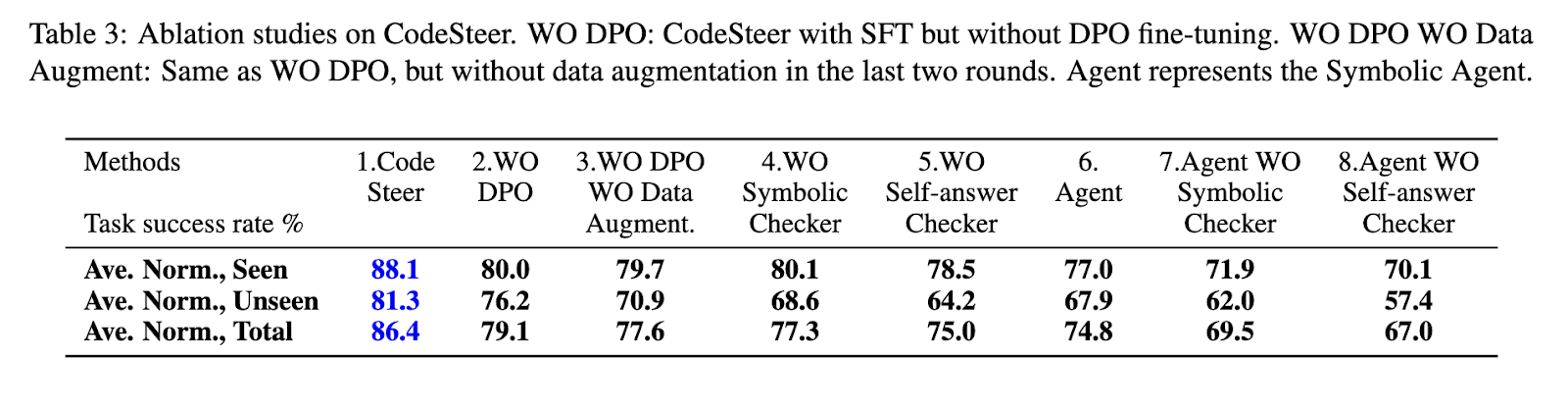
CodeSteer 框架引入了一種多步驟的方法來增強 LLMs 的推理能力。第一步是開發 SymBench,這是一個包含符號推理任務的基準,例如數學問題解決、邏輯推理和優化。CodeSteer 使用這個數據集生成 12,000 條多輪指導/生成軌跡和 5,500 對指導比較對。接下來,研究人員對 Llama-3-8B 模型進行多輪監督微調和直接偏好優化,使其能夠動態調整決策方法。該框架還通過添加符號檢查器和自我回答檢查器進一步增強,這些檢查器驗證生成解決方案的正確性和效率。這些機制確保模型在代碼執行更有效的情況下不僅依賴於基於文本的推理。
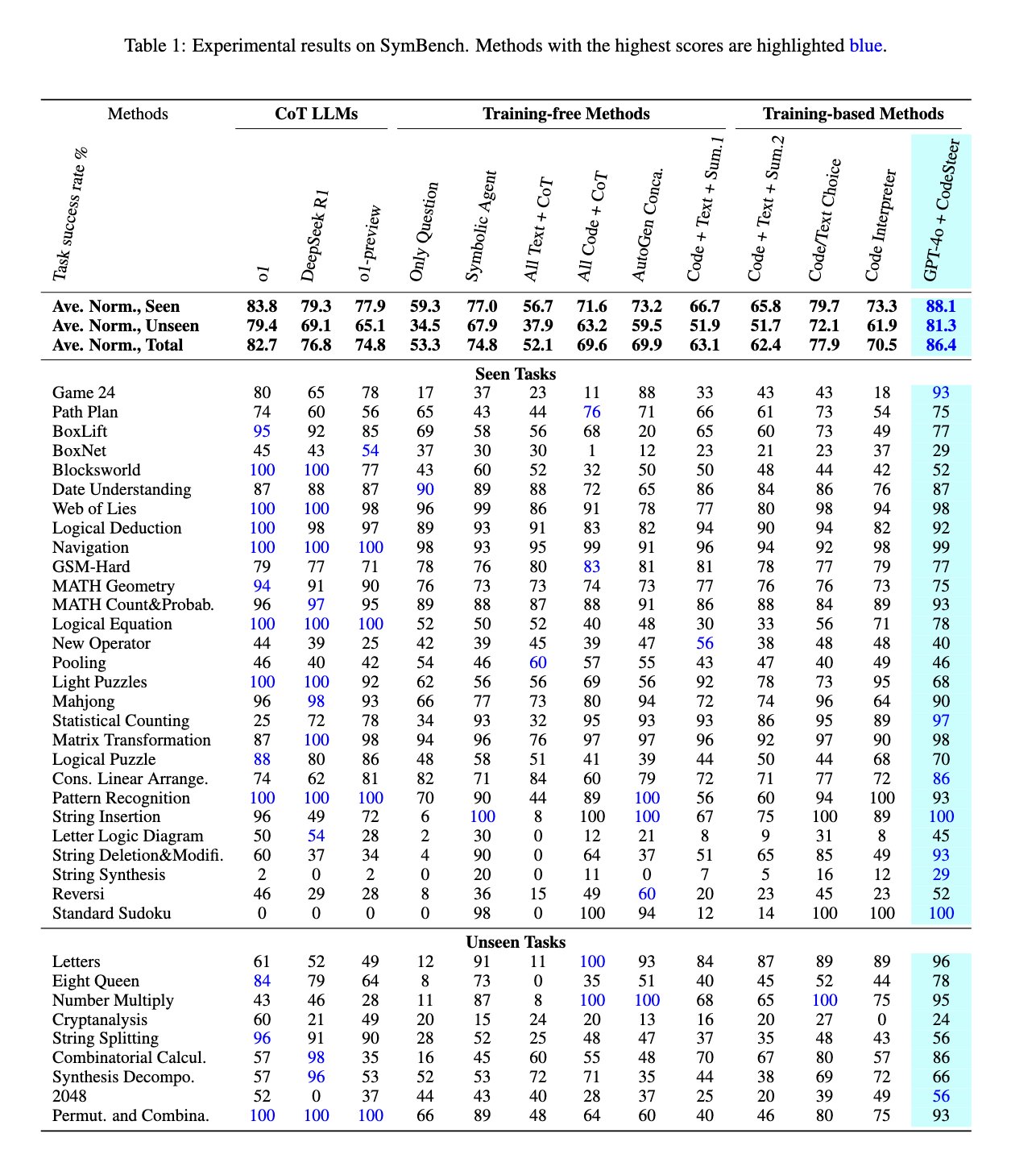
CodeSteer 的性能評估顯示出相較於現有 LLMs 的顯著改進。當與 GPT-4o 整合時,該框架將模型在 37 個符號任務上的平均性能分數從 53.3 提高到 86.4。它的表現也超過了 OpenAI 的 o1 模型(得分 82.7)和 DeepSeek R1(得分 76.8)。在涉及未見任務的評估中,CodeSteer 一直顯示出 41.8% 的改進,超過了 Claude-3-5-Sonnet、Mistral-Large 和 GPT-3.5 模型。通過利用符號計算,CodeSteer 使 LLMs 即使在高度複雜的問題解決任務中也能保持高性能。基準結果表明,該框架提高了準確性並減少了與基於文本的迭代推理相關的低效率。

這項研究強調了引導 LLMs 判斷何時使用符號計算與自然語言推理的重要性。所提出的框架成功克服了現有模型的限制,通過引入結構化的多輪決策方法。通過 CodeSteer,研究人員開發了一個顯著增強大型語言模型有效性的系統,使其在處理複雜問題解決任務時更可靠。通過更有效地整合符號計算,這項研究標誌著在改善 AI 驅動的推理和計劃方面邁出了重要一步。
查看論文和 GitHub 頁面。所有的研究功勞都歸於這個項目的研究人員。此外,別忘了在 Twitter 上關注我們,加入我們的 Telegram 頻道和 LinkedIn 群組。還有,別忘了加入我們的 75k+ 機器學習 SubReddit。
🚨 推薦的開源 AI 平台:‘IntellAgent 是一個開源的多代理框架,用於評估複雜的對話 AI 系統’(推廣)
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!



")




{kind=link}