


免責聲明:使用人工智慧(AI)來撰寫求職信或履歷的想法並不是我首創的。許多人在這方面已經成功地做過,並且從這個想法建立了網站甚至公司。這只是一個教學,教你如何使用 Python 和幾行程式碼來建立自己的求職信 AI 生成應用程式。你在這篇文章中看到的所有程式碼都可以在我的公開 GitHub 資料夾中找到。享受吧。🙂
佩普·瓜迪奧拉 (Pep Guardiola) 是一位非常成功的曼城 (Manchester City) 足球教練。在巴塞羅那 (Barcelona) 的梅西 (Leo Messi) 年代,他發明了一種被稱為「Tiki-Taka」的足球打法。這意味著當你接到球後,你立即傳球,甚至不需要控制球。你可以在進球之前傳球 30 到 40 次。
十多年後,我們可以看到瓜迪奧拉和他的巴塞羅那所創造的足球風格已經不再。如果你看曼城的比賽,他們會立即尋找前鋒或邊鋒。你只需要幾次垂直的傳球,馬上尋找機會。這樣的打法更可預測,但因為你這樣做很多次,最終會找到進攻的空間。
我認為,求職市場在某種程度上也朝著同樣的方向發展。
以前,你有機會親自到公司遞交履歷,與他們交談,與他們在一起,安排面試,主動與人交流。你會花幾週的時間準備這次出行,潤飾你的履歷,並複習問題和答案。
對於許多人來說,這種老式的策略仍然有效,我相信這一點。如果你有良好的社交機會,或者在合適的時間和地點,遞交履歷的方式非常有效。我們喜歡人與人之間的連結,實際上認識某個人是非常有效的。
不過,還有另一種方法值得考慮。像 LinkedIn、Indeed 這樣的公司,甚至整體互聯網完全改變了這個遊戲。你可以向許多公司發送大量的履歷,並根據統計數據找到工作。AI 進一步改變了這個遊戲。現在有很多 AI 工具可以根據特定公司來調整你的履歷,使你的履歷更具吸引力,或建立針對特定工作的求職信。確實有許多公司向尋找工作的人提供這類服務。
現在,相信我,我對這些公司沒有任何意見,但他們使用的 AI 實際上並不是「他們的 AI」。我的意思是,如果你使用 ChatGPT、Gemini 或最新的 DeepSeek 來完成相同的任務,你很可能不會得到比你在他們網站上使用的(付費)工具更差的回應。你實際上是在為擁有一個後端 API 付費,而這個 API 完成的工作本來我們可以通過 ChatGPT 來做。這是公平的。
儘管如此,我想告訴你,使用大型語言模型(LLM)來製作自己的「履歷助手」其實是非常簡單和便宜的。特別是,我想專注於求職信。你給我你的履歷和工作描述,我就會給你一份可以複製並粘貼到 LinkedIn、Indeed 或你的電子郵件中的求職信。
在一張圖片中,它看起來會是這樣:
現在,大型語言模型(LLMs)是專門生成文本的 AI 模型。更具體地說,它們是非常大的機器學習模型(即使是小型的也非常大)。
這意味著從頭開始建立自己的 LLM 或訓練一個是非常昂貴的。我們不會這樣做。我們將使用一個運行良好的 LLM,並聰明地指導它執行我們的任務。更具體地說,我們將在 Python 中使用一些 API。正式來說,這是一個付費 API。儘管如此,自從我開始整個項目(經過所有的試驗和錯誤過程)以來,我花費的金額不到 30 美分。你可能只需花 4 或 5 美分。
此外,我們將製作一個運行的網頁應用程式,讓你只需幾次點擊就能獲得求職信。這將是一個幾百行程式碼的工作(包括空格 🙂)。
為了激勵你,這裡是最終應用程式的截圖:

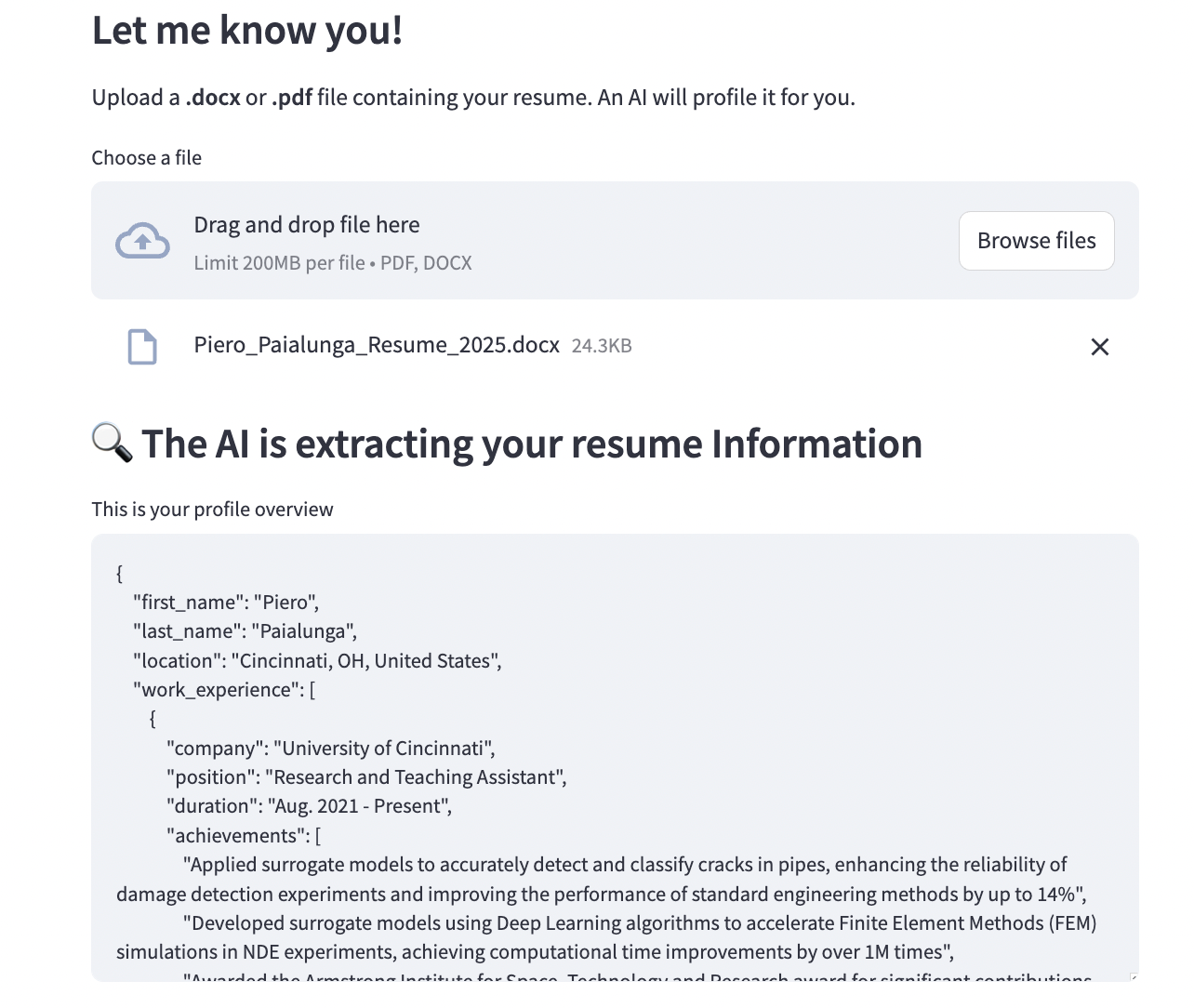
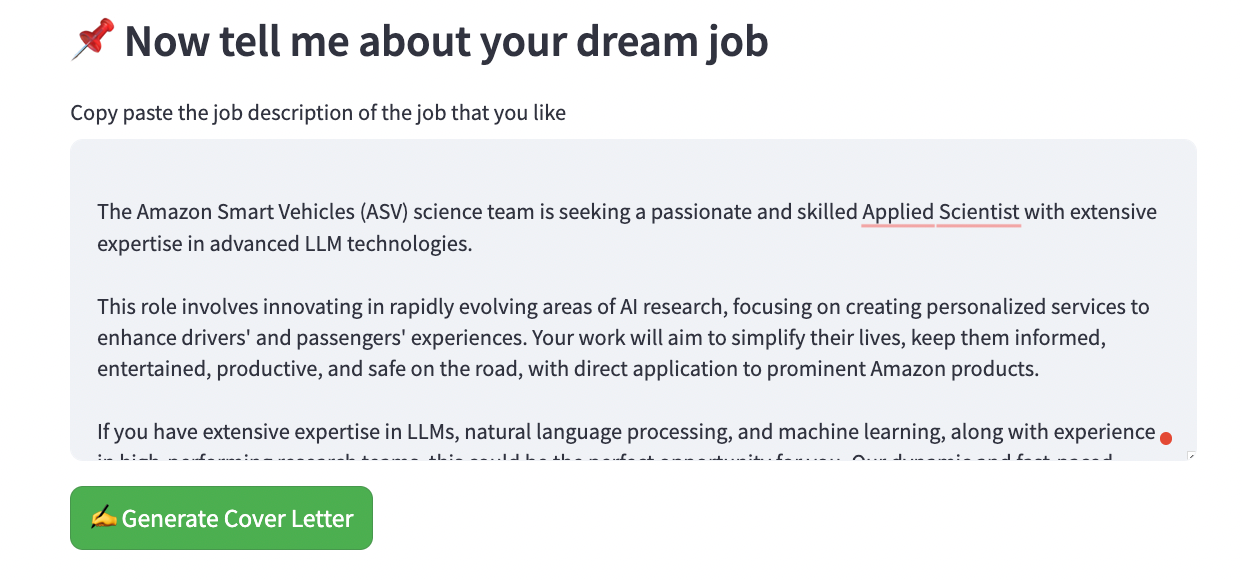
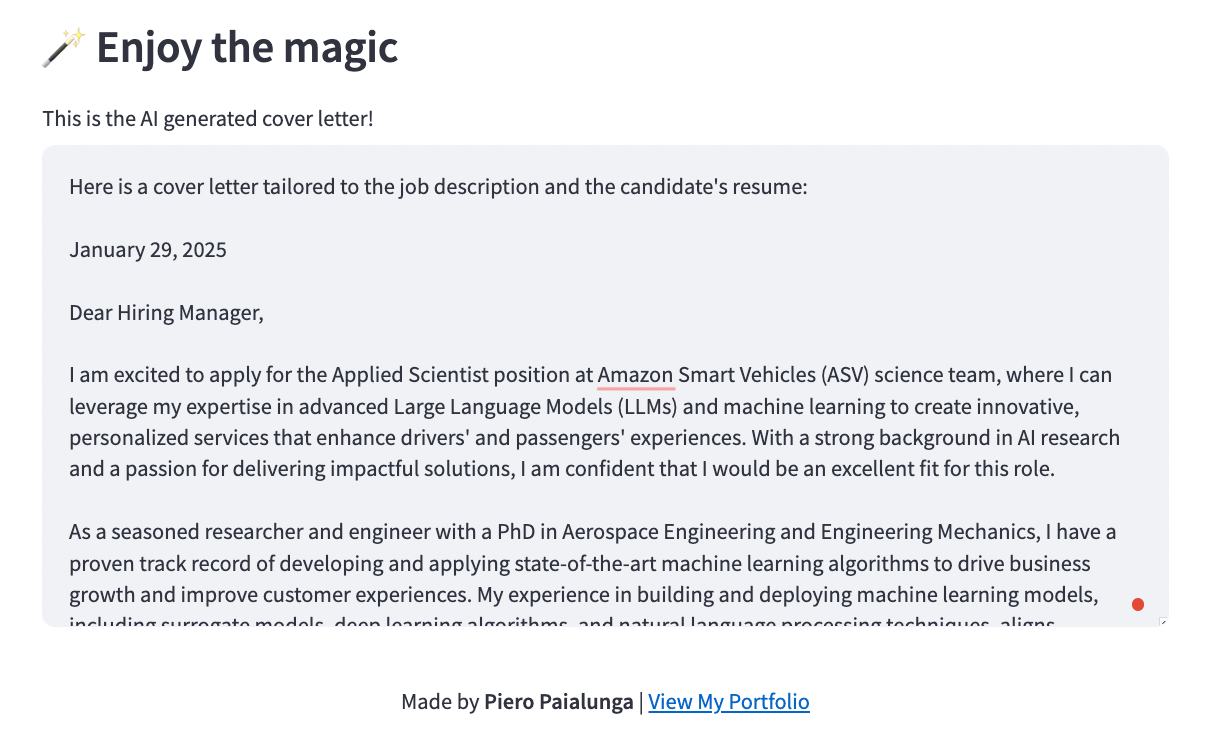
很酷吧?我花了不到 5 小時就從零開始建立整個東西。相信我:這麼簡單。在這篇文章中,我們將按順序描述:
1. LLM API 策略
這是本項目的機器學習系統設計部分,我保持得非常簡單,因為我希望最大化整個方法的可讀性(而且老實說,這不需要比這更複雜)。
我們將使用兩個 API:
- 一個文檔解析 LLM API 將讀取履歷並提取所有有意義的信息。這些信息將放入一個 .json 文件中,以便在生產中,我們將已經處理並存儲的履歷保存在我們的記憶中。
- 一個求職信 LLM API。這個 API 將讀取解析後的履歷(前一個 API 的輸出)和工作描述,並輸出求職信。
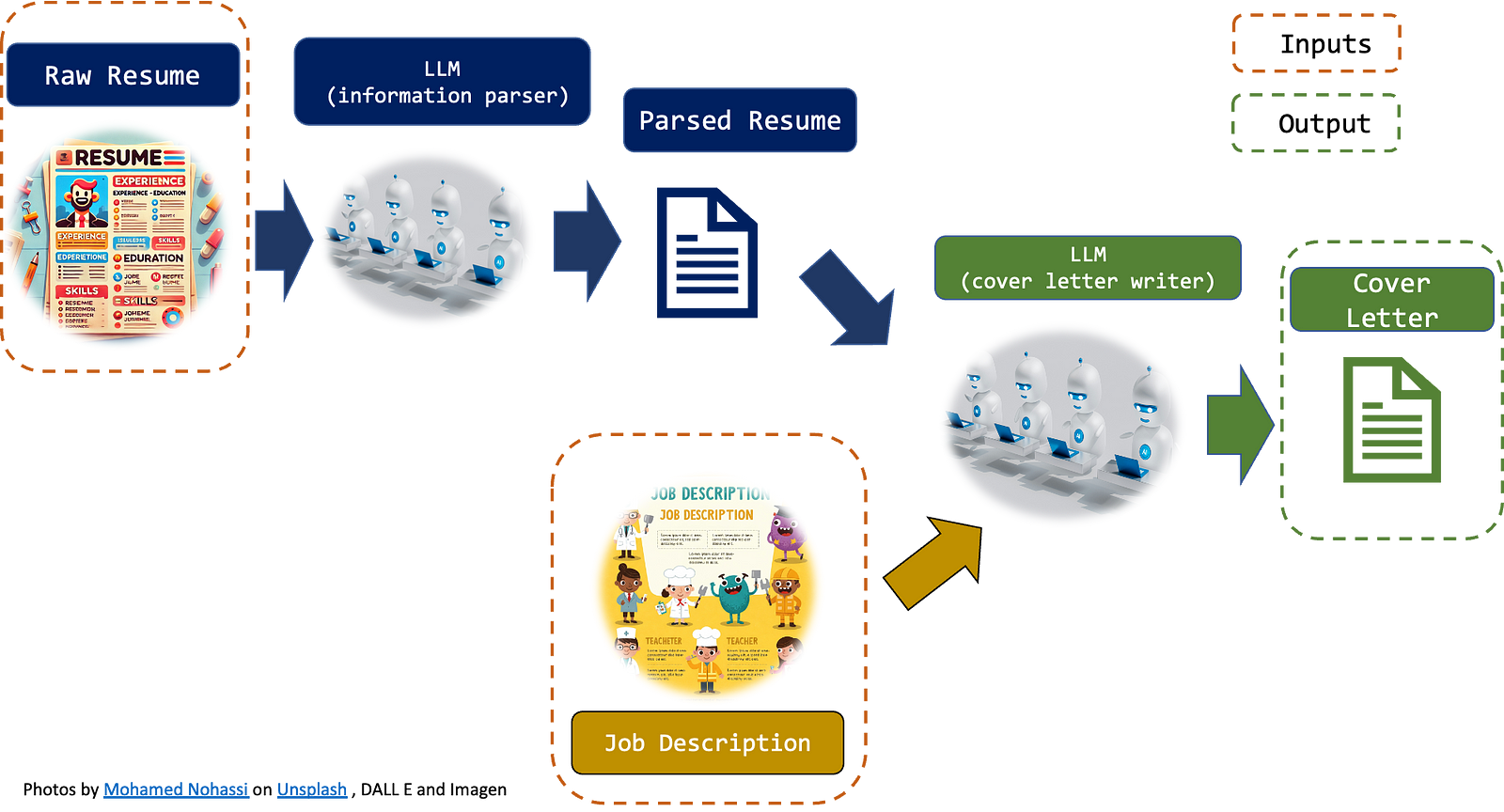
兩個主要要點:
- 這個任務最好的 LLM 是什麼?對於文本提取和總結,LLama 或 Gemma 被認為是相對便宜且高效的 LLM。由於我們將使用 LLama 進行總結任務,為了保持一致性,我們也可以將其用於其他 API。如果你想使用其他模型,隨意使用。
- 我們如何連接 API?有多種方法可以做到這一點。我決定嘗試 Llama API。文檔並不是特別詳細,但它運作良好,並允許你使用多種模型。你需要登錄,購買一些信用(1 美元對於這個任務來說足夠了),並保存你的 API 密鑰。如果你想切換到其他解決方案(如 Hugging Face 或 Langchain),也可以。
好了,現在我們知道該怎麼做,我們只需要在 Python 中實現它。
2. LLM 物件
我們需要的第一件事是實際的 LLM 提示。在 API 中,提示通常使用字典傳遞。由於它們可能相當長,且結構始終相似,因此將它們存儲在 .json 文件中是有意義的。我們將讀取 JSON 文件並將其用作 API 調用的輸入。
2.1 LLM 提示
在這個 .json 文件中,你將有模型(你可以隨意命名模型)和內容,這是 LLM 的指令。當然,內容鍵有一個靜態部分,即「指令」,還有一個動態部分,即 API 調用的具體輸入。例如:這是第一個 API 的 .json 文件,我稱之為 resume_parser_api.json:
「你是一個履歷解析器。你將從這份履歷中提取信息,並將其放入一個 .json 文件中。你的字典鍵將是 first_name、last_name、location、work_experience、school_experience、skills。在選擇信息時,請注意最具洞察力的內容。」
我想從我的 .json 文件中提取的鍵是:
[first_name, last_name, location, work_experience, school_experience, skills]
隨意添加你希望從履歷中「提取」的任何其他信息,但請記住,這些信息應該只對你的求職信有意義。具體的履歷將在這段文字後添加,以形成完整的調用/指令。稍後會詳細說明。
順序指令是 cover_letter_api.json:
「你是一位求職專家和求職信撰寫者。根據一個履歷的 json 文件、工作描述和日期,為這位候選人撰寫一封求職信。要有說服力和專業性。履歷 JSON: {resume_json};工作描述: {job_description},日期: {date}」
如你所見,有三個佔位符:「Resume_json」、「job_description」和「date」。與之前一樣,這些佔位符將被正確的信息替換,以形成完整的提示。
2.2 constants.py
我製作了一個非常小的 constants.py 文件,裡面包含兩個 .json 提示文件的路徑和你必須從 LLamaApi 生成的 API。如果你想在本地運行該文件,可以修改這個。
2.3 file_loader.py
這個文件是一個「加載器」集合,用於你的履歷。雖然這部分有點無聊,但卻很重要。
2.4 cover_letter.py
LLM 策略的整個實現可以在我稱之為 CoverLetterAI 的物件中找到。這裡是:
我花了一些時間試圖讓一切模組化且易於閱讀。我還對所有函數做了很多註解,這樣你就可以清楚地看到每個函數的功能。我們如何使用這個工具呢?
整個程式碼只需 5 行簡單的程式碼就能運行。像這樣:
from cover_letter import CoverLetterAI
cover_letter_AI = CoverLetterAI()
cover_letter_AI.read_candidate_data('path_to_your_resume_file')
cover_letter_AI.profile_candidate()
cover_letter_AI.add_job_description('Insert job description')
cover_letter_AI.write_cover_letter()
所以步驟如下:
- 你調用 CoverLetterAI 物件。它將是整個過程的明星。
- 你給我你的履歷路徑。它可以是 PDF 或 Word,我會讀取你的信息並將其存儲在變量中。
- 你調用 profile_candidate(),我運行我的第一個 LLM。這個過程會處理候選人的文字信息,並創建我們將用於第二個 LLM 的 .json 文件。
- 你給我工作描述,並將其添加到系統中。已存儲。
- 你調用 write_cover_letter(),我運行我的第二個 LLM,根據工作描述和履歷 .json 文件生成求職信。
3. 網頁應用程式和結果
所以這就是全部。你在前面的段落中看到了這篇文章的所有技術細節。
為了顯示它的運作,我還製作了一個網頁應用程式,你可以上傳你的履歷,添加工作描述,然後點擊生成求職信。這是鏈接,這是程式碼。
現在,生成的求職信非常出色。
這是一封隨機的求職信:
2025年2月1日
招聘經理,[公司名稱我故意模糊]
我很高興申請 [公司名稱我故意模糊] 的傑出 AI 工程師職位,在這裡我可以利用我對構建負責任和可擴展的 AI 系統的熱情,來徹底改變銀行業。作為一名經驗豐富的機器學習工程師和研究人員,擁有物理和工程的堅實背景,我相信我的技能和經驗符合這個角色的要求。
我擁有辛辛那提大學 (University of Cincinnati) 航空航天工程和工程力學的博士學位,以及羅馬托爾維爾大學 (University of Rome Tor Vergata) 複雜系統和大數據物理的碩士學位,擁有理論和實踐知識的獨特結合。我的經驗包括開發和部署 AI 模型、設計和實施機器學習算法,以及處理大型數據集,這使我具備推動 AI 工程創新的能力。
作為辛辛那提大學的研究和教學助理,我應用代理模型來檢測和分類管道中的裂縫,實現了 14% 的損傷檢測實驗改進。我還使用深度學習算法開發了代理模型,以加速有限元方法 (FEM) 模擬,實現了 100 萬倍的計算時間縮短。我在教學和為對 AI 感興趣的青少年創建信號處理和圖像處理課程的經驗,磨練了我有效傳達複雜概念的能力。
在我之前的職位中,作為 Gen Nine, Inc.、Apex Microdevices 和 Accenture 的機器學習工程師,我成功設計、開發和部署了 AI 驅動的解決方案,包括配置 mmWave 雷達和 Jetson 設備以進行數據收集、實施最先進的點雲算法,以及領導 FastMRI 項目以加速 MRI 掃描時間。我在 Python、TensorFlow、PyTorch 和 MATLAB 等編程語言方面的專業知識,以及在 AWS、Docker 和 Kubernetes 等雲平台上的經驗,使我能夠開發和部署可擴展的 AI 解決方案。
我特別被 [公司名稱我故意模糊] 對創建負責任和可靠的 AI 系統的承諾所吸引,這些系統優先考慮客戶體驗和簡單性。我對保持對最新 AI 研究的了解的熱情,以及我在生產中明智地應用新技術的能力,與公司的願景相符。我對有機會與跨職能的工程師、研究科學家和產品經理團隊合作,交付 AI 驅動的產品,徹底改變 [公司名稱我故意模糊] 服務客戶的方式感到興奮。
除了我的技術技能和經驗外,我還擁有出色的溝通和演講能力,這在我在 Towards Data Science 的技術寫作經驗中得到了證明,我在那裡撰寫了有關機器學習和數據科學的綜合文章,每月吸引了超過 5 萬的觀眾。
感謝您考慮我的申請。我期待著討論我的技能和經驗如何為 [公司名稱我故意模糊] 的成功做出貢獻,以及 [公司名稱我故意模糊] 的使命,即通過 AI 為銀行業帶來人性化和簡單化。我相信我對 AI 的熱情、我的技術專業知識以及我合作工作的能力將使我成為你們團隊的寶貴資產。
誠摯的,
皮耶羅·帕亞倫加 (Piero Paialunga)
它們看起來就像我為特定工作描述撰寫的求職信。不過,到了 2025 年,你需要小心,因為招聘經理確實知道你在使用 AI 來撰寫求職信,而「電腦語氣」非常容易被識別(例如,「渴望」這樣的詞聽起來非常像 ChatGPT 的風格,哈哈)。因此,我想說的是,明智地使用這些工具。當然,你可以用它們來建立你的「模板」,但一定要加入你的個人風格,否則你的求職信將與其他成千上萬的求職信一模一樣。
這是建立網頁應用程式的程式碼。
4. 結論
在這篇文章中,我們發現如何使用 LLM 將你的履歷和工作描述轉換為特定的求職信。這些是我們討論的要點:
- AI 在求職中的應用。在第一章中,我們討論了 AI 如何徹底改變求職的方式。
- 大型語言模型的概念。設計 LLM API 時非常重要。我們在第二段中做到了這一點。
- LLM API 的實現。我們使用 Python 有機且高效地實現了 LLM API。
- 網頁應用程式。我們使用 Streamlit 建立了一個網頁應用程式 API,以展示這種方法的威力。
- 這種方法的限制。我認為 AI 生成的求職信確實非常好。它們準確、專業且精心製作。然而,如果每個人都開始使用 AI 來撰寫求職信,它們都會看起來一樣,或者至少具有相同的語氣,這並不好。這是值得思考的事情。
5. 參考文獻和其他優秀實現
我覺得有必要提到許多在我之前就有這個想法並讓它公開可用的優秀人士。這只是我在網上找到的一些。
Balaji Kesavan 的 Cover Letter Craft 是一個 Streamlit 應用程式,實現了非常類似的使用 AI 撰寫求職信的想法。我們與那個應用程式的不同之處在於,我們直接從 Word 或 PDF 中提取履歷,而他的應用程式需要複製粘貼。儘管如此,我認為這位先生非常有才華且富有創意,我建議你看看他的作品。
Randy Pettus 也有類似的想法。與本教程提出的方法不同的是,他對信息非常具體,詢問像「當前招聘經理」和模型的溫度等問題。這非常有趣(而且聰明),你可以清楚地看到他如何思考求職信,以引導 AI 以他喜歡的方式來撰寫。強烈推薦。
Juan Esteban Cepeda 的應用程式也做得很好。你也可以看出他正在努力讓它超越一個簡單的 Streamlit 應用,因為他添加了公司鏈接和一堆用戶評價。做得好,努力不懈。🙂
6. 關於我!
再次感謝你的時間。這對我來說意義重大 ❤
我叫皮耶羅·帕亞倫加 (Piero Paialunga),這是我的照片:

我是一名辛辛那提大學 (University of Cincinnati) 航空航天工程系的博士生,也是 Gen Nine 的機器學習工程師。我在我的博客文章和 LinkedIn 上談論 AI 和機器學習。如果你喜歡這篇文章並想了解更多關於機器學習的內容,並跟隨我的研究,你可以:
- A. 在 LinkedIn 上關注我,我會發布我的所有故事。
- B. 訂閱我的電子報。這將讓你了解新故事,並給你機會發訊息給我,獲得所有的修正或疑問。
- C. 成為推薦會員,這樣你就不會有「每月故事的最大數量」,可以閱讀我(和成千上萬其他機器學習和數據科學頂尖作家)關於最新技術的所有文章。
- D. 想和我合作嗎?查看我在 Upwork 上的費用和項目!
如果你想問我問題或開始合作,請在這裡或在 LinkedIn 上留言:
[email protected]
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!



")




{kind=link}