


大型語言模型(LLMs)已經成為各種自然語言處理應用中不可或缺的工具,包括機器翻譯、文本摘要和對話式人工智慧。然而,這些模型日益增長的複雜性和規模也帶來了計算效率和記憶體消耗的挑戰。隨著模型的擴大,對資源的需求使得它們在計算能力有限的環境中難以部署。
大型語言模型的主要障礙在於它們龐大的計算需求。訓練和微調這些模型需要數十億個參數,這使得它們非常耗資源,限制了其可及性。現有的提高效率的方法,如參數高效微調(PEFT),雖然能提供一些幫助,但往往會影響性能。挑戰在於找到一種方法,可以顯著減少計算需求,同時保持模型在現實場景中的準確性和有效性。研究人員一直在探索能夠在不需要大量計算資源的情況下進行高效模型調整的方法。
英特爾實驗室(Intel Labs)和英特爾公司(Intel Corporation)的研究人員提出了一種將低秩適應(LoRA)與神經架構搜索(NAS)技術結合的方法。這種方法旨在解決傳統微調方法的局限性,同時提高效率和性能。研究團隊開發了一個框架,通過利用結構化的低秩表示來優化記憶體消耗和計算速度。這項技術涉及一個權重共享的超網絡,能夠動態調整子結構以提高訓練效率。這種整合使得模型能夠有效地進行微調,同時保持最小的計算負擔。
英特爾實驗室提出的方法以LoNAS(低秩神經架構搜索)為中心,使用彈性LoRA適配器進行模型微調。與傳統方法需要對大型語言模型進行全面微調不同,LoNAS允許選擇性地啟用模型子結構,減少冗餘。關鍵創新在於彈性適配器的靈活性,根據模型需求動態調整。這種方法得到了啟發式子網絡搜索的支持,進一步簡化了微調過程。通過僅關注相關的模型參數,這項技術在計算效率和性能之間取得了平衡。該過程結構化以允許選擇性地啟用低秩結構,同時保持高推理速度。
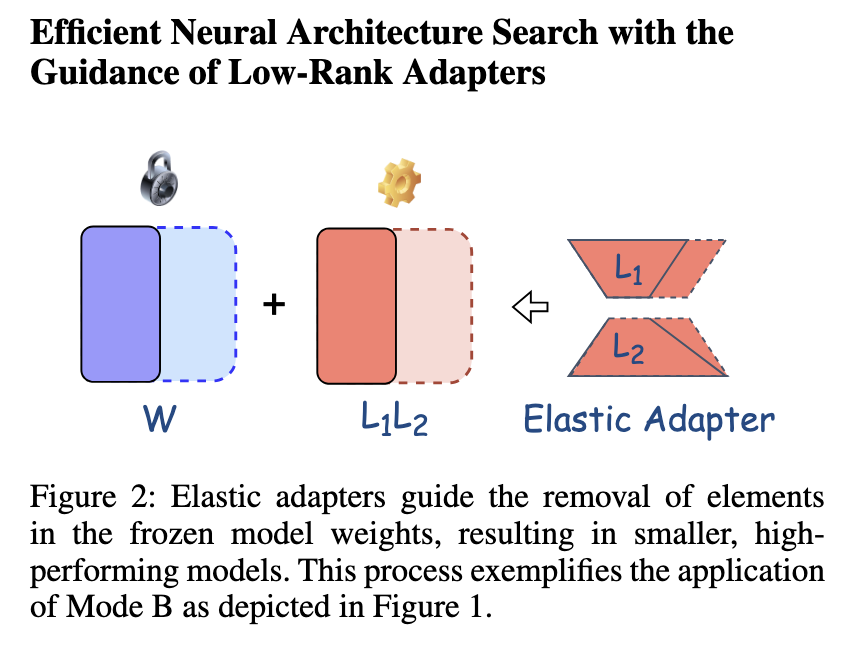
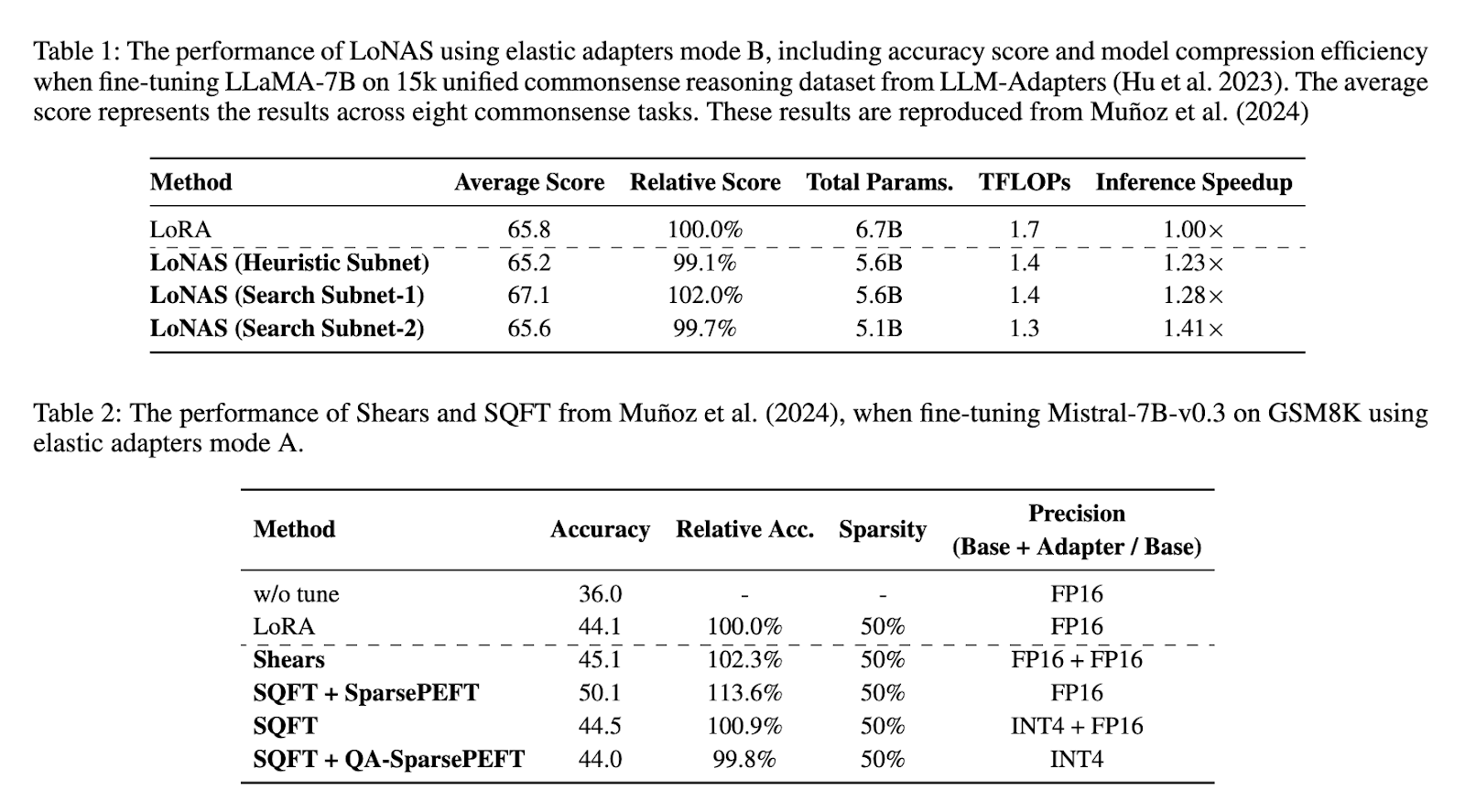
對該方法的性能評估顯示出其相較於傳統技術的顯著改進。實驗結果表明,LoNAS的推理速度提高了最多1.4倍,同時模型參數減少了約80%。在對LLaMA-7B進行微調時,使用了15k的統一常識推理數據集,LoNAS的平均準確率達到65.8%。不同LoNAS配置的比較分析顯示,啟發式子網絡優化實現了1.23倍的推理加速,而搜索子網絡配置則分別達到了1.28倍和1.41倍的加速。此外,將LoNAS應用於Mistral-7B-v0.3的GSM8K任務中,準確率從44.1%提高到50.1%,在不同模型大小中保持了效率。這些發現證實了所提出的方法顯著提高了大型語言模型的性能,同時減少了計算需求。
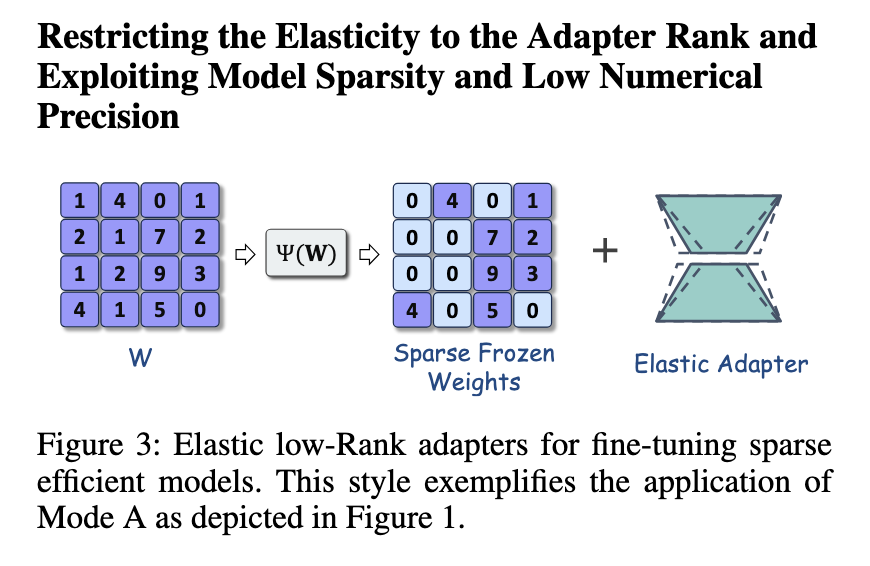
對該框架的進一步改進包括引入Shears,一種基於LoNAS的先進微調策略。Shears利用神經低秩適配器搜索(NLS)將彈性限制在適配器的秩上,減少不必要的計算。這種方法使用預定義的指標對基礎模型施加稀疏性,確保微調保持高效。這一策略在保持模型準確性的同時,減少了活動參數的數量。另一個擴展是SQFT,結合了稀疏性和低數值精度以增強微調。使用量化感知技術,SQFT確保稀疏模型能夠在不損失效率的情況下進行微調。這些改進突顯了LoNAS的適應性及其進一步優化的潛力。
整合LoRA和NAS提供了一種變革性的方式來優化大型語言模型。通過利用結構化的低秩表示,研究表明計算效率可以在不妥協性能的情況下顯著提高。英特爾實驗室的研究確認,結合這些技術可以減輕微調的負擔,同時確保模型的完整性。未來的研究可以探索進一步的優化,包括增強的子網絡選擇和更有效的啟發式策略。這種方法為使大型語言模型在多樣化環境中更易於訪問和部署奠定了基礎,為更高效的人工智慧模型鋪平了道路。
查看論文和GitHub頁面。所有的研究成果都歸功於這個項目的研究人員。此外,別忘了在Twitter上關注我們,並加入我們的Telegram頻道和LinkedIn小組。還有,記得加入我們的70k+ ML SubReddit。
🚨 介紹IntellAgent:一個開源的多代理框架,用於評估複雜的對話式人工智慧系統(推廣)
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!



")




{kind=link}