


對比特幣 (Bitcoin) 或其價格波動不太了解,但想做出投資決策以獲利嗎?這個機器學習模型可以幫助你。它能比占星師更準確地預測價格。在這篇文章中,我們將使用 ZenML 和 MLflow 建立一個機器學習模型來預測比特幣的價格。所以讓我們開始這段旅程,了解任何人如何使用機器學習和 MLOps 工具來預測未來。
學習目標
- 學會如何有效地使用 API 獲取即時數據。
- 了解 ZenML 是什麼,為什麼我們使用 MLflow,以及如何將其與 ZenML 整合。
- 探索機器學習模型的部署過程,從想法到生產。
- 發現如何創建一個用戶友好的 Streamlit 應用程序,以進行互動式機器學習模型預測。
這篇文章是數據科學部落格馬拉松的一部分。
問題陳述
比特幣的價格非常不穩定,做出預測幾乎是不可能的。在我們的項目中,我們使用 MLOps 的最佳實踐來建立一個 LSTM 模型,以預測比特幣的價格和趨勢。
在實施項目之前,讓我們看看項目的架構。
項目實施
讓我們開始訪問 API。
為什麼要這樣做?你可以從不同的數據集中獲取歷史比特幣價格數據,但通過 API,我們可以獲得即時市場數據。
步驟 1:訪問 API
“`python
import requests
import pandas as pd
from dotenv import load_dotenv
import os
# 加載 .env 文件
load_dotenv()
def fetch_crypto_data(api_uri):
response = requests.get(
api_uri,
params={
“market”: “cadli”,
“instrument”: “BTC-USD”,
“limit”: 5000,
“aggregate”: 1,
“fill”: “true”,
“apply_mapping”: “true”,
“response_format”: “JSON”
},
headers={“Content-type”: “application/json; charset=UTF-8”}
)
if response.status_code == 200:
print(‘API 連接成功!\n正在獲取數據…’)
data = response.json()
data_list = data.get(‘Data’, [])
df = pd.DataFrame(data_list)
df[‘DATE’] = pd.to_datetime(df[‘TIMESTAMP’], unit=”s”)
return df # 返回 DataFrame
else:
raise Exception(f”API 錯誤: response.status_code – response.text”)
“`
步驟 2:使用 MongoDB 連接數據庫
MongoDB 是一種 NoSQL 數據庫,以其適應性、可擴展性和能夠以類似 JSON 的格式存儲非結構化數據而聞名。
“`python
import os
from pymongo import MongoClient
from dotenv import load_dotenv
from data.management.api import fetch_crypto_data # 導入 API 函數
import pandas as pd
load_dotenv()
MONGO_URI = os.getenv(“MONGO_URI”)
API_URI = os.getenv(“API_URI”)
client = MongoClient(MONGO_URI, ssl=True, ssl_certfile=None, ssl_ca_certs=None)
db = client[‘crypto_data’]
collection = db[‘historical_data’]
try:
latest_entry = collection.find_one(sort=[(“DATE”, -1)]) # 查找最新日期
if latest_entry:
last_date = pd.to_datetime(latest_entry[‘DATE’]).strftime(‘%Y-%m-%d’)
else:
last_date=”2011-03-27″ # 如果 MongoDB 為空,則默認開始日期
print(f”從 last_date 開始獲取數據…”)
new_data_df = fetch_crypto_data(API_URI)
if latest_entry:
new_data_df = new_data_df[new_data_df[‘DATE’] > last_date]
if not new_data_df.empty:
data_to_insert = new_data_df.to_dict(orient=”records”)
result = collection.insert_many(data_to_insert)
print(f”插入了 {len(result.inserted_ids)} 條新記錄到 MongoDB。”)
else:
print(“沒有新數據可插入。”)
except Exception as e:
print(f”發生錯誤: {e}”)
“`
這段代碼連接到 MongoDB,通過 API 獲取比特幣價格數據,並在最新登錄日期之後更新數據庫中的所有新條目。
介紹 ZenML
ZenML 是一個開源平台,專為機器學習操作而設計,支持創建靈活且可生產的管道。此外,ZenML 與多個機器學習工具(如 MLflow、BentoML 等)集成,以創建無縫的機器學習管道。
⚠️ 如果你是 Windows 用戶,請嘗試在系統上安裝 wsl。ZenML 不支持 Windows。
在這個項目中,我們將實施一個傳統的管道,使用 ZenML,並將 MLflow 與 ZenML 整合,用於實驗跟踪。
前置條件和基本 ZenML 命令
“`bash
# 創建虛擬環境
python3 -m venv venv
# 在你的項目文件夾中啟動虛擬環境
source venv/bin/activate
“`
ZenML 命令:
以下是所有核心 ZenML 命令及其功能:
“`bash
# 安裝 zenml
pip install zenml
# 在本地啟動 zenml 伺服器和儀表板
pip install “zenml[server]”
# 檢查 zenml 版本:
zenml version
# 初始化新存儲庫
zenml init
# 在本地運行儀表板:
zenml login –local
# 知道我們的 zenml 管道狀態
zenml show
# 關閉 zenml 伺服器
zenml clean
“`
步驟 3:將 MLflow 與 ZenML 整合
我們使用 MLflow 進行實驗跟踪,以跟踪我們的模型、工件、指標和超參數值。這裡我們註冊 MLflow 以進行實驗跟踪和模型部署:
“`bash
# 將 mlflow 與 ZenML 整合
zenml integration install mlflow -y
# 註冊實驗跟踪器
zenml experiment-tracker register mlflow_tracker –flavor=mlflow
# 註冊模型部署器
zenml model-deployer register mlflow –flavor=mlflow
# 註冊堆棧
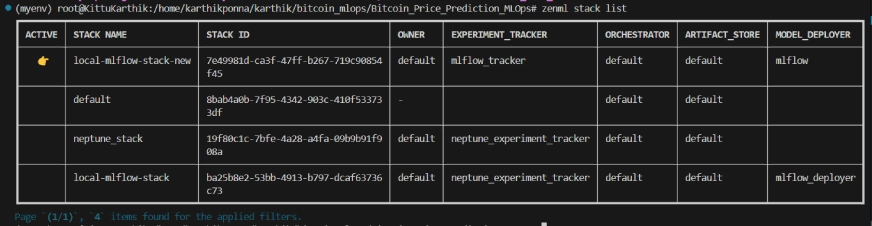
zenml stack register local-mlflow-stack-new -a default -o default -d mlflow -e mlflow_tracker –set
# 查看堆棧列表
zenml stack –list
“`
ZenML 堆棧列表
項目結構
在這裡,你可以看到項目的佈局。現在讓我們逐一詳細討論。
“`
bitcoin_price_prediction_mlops/ # 項目目錄
├── data/
│ └── management/
│ ├── api_to_mongodb.py # 獲取數據並將其保存到 MongoDB 的代碼
│ └── api.py # 與 API 相關的實用程序函數
│
├── pipelines/
│ ├── deployment_pipeline.py # 部署管道
│ └── training_pipeline.py # 訓練管道
│
├── saved_models/ # 存儲訓練模型的目錄
├── saved_scalers/ # 存儲用於數據預處理的縮放器的目錄
│
├── src/ # 源代碼
│ ├── data_cleaning.py # 數據清理和預處理
│ ├── data_ingestion.py # 數據攝取
│ ├── data_splitter.py # 數據拆分
│ ├── feature_engineering.py # 特徵工程
│ ├── model_evaluation.py # 模型評估
│ └── model_training.py # 模型訓練
│
├── steps/ # ZenML 步驟
│ ├── clean_data.py # ZenML 步驟,用於清理數據
│ ├── data_splitter.py # ZenML 步驟,用於數據拆分
│ ├── dynamic_importer.py # ZenML 步驟,用於導入動態數據
│ ├── feature_engineering.py # ZenML 步驟,用於特徵工程
│ ├── ingest_data.py # ZenML 步驟,用於數據攝取
│ ├── model_evaluation.py # ZenML 步驟,用於模型評估
│ ├── model_training.py # ZenML 步驟,用於訓練模型
│ ├── prediction_service_loader.py # ZenML 步驟,用於加載預測服務
│ ├── predictor.py # ZenML 步驟,用於預測
│ └── utils.py # 步驟的實用函數
│
├── .env # 環境變數文件
├── .gitignore # Git 忽略文件
│
├── app.py # Streamlit 用戶界面應用
│
├── README.md # 項目文檔
├── requirements.txt # 所需包的列表
├── run_deployment.py # 運行部署和預測管道的代碼
├── run_pipeline.py # 運行訓練管道的代碼
└── .zen/ # ZenML 目錄(在 ZenML 初始化後自動創建)
“`
步驟 4:數據攝取
我們首先從 API 攝取數據到 MongoDB,並將其轉換為 pandas DataFrame。
“`python
import os
import logging
from pymongo import MongoClient
from dotenv import load_dotenv
from zenml import step
import pandas as pd
# 加載 .env 文件
load_dotenv()
# 獲取 MongoDB URI
MONGO_URI = os.getenv(“MONGO_URI”)
def fetch_data_from_mongodb(collection_name:str, database_name:str):
“””
從 MongoDB 獲取數據並轉換為 pandas DataFrame。
collection_name:
要獲取數據的 MongoDB 集合名稱。
database_name:
MongoDB 數據庫名稱。
return:
包含數據的 pandas DataFrame
“””
# 連接到 MongoDB 客戶端
client = MongoClient(MONGO_URI)
db = client[database_name] # 選擇數據庫
collection = db[collection_name] # 選擇集合
# 獲取集合中的所有文檔
try:
logging.info(f”從 MongoDB 集合中獲取數據: {collection_name}…”)
data = list(collection.find()) # 將游標轉換為字典列表
if not data:
logging.info(“在 MongoDB 集合中未找到數據。”)
# 將字典列表轉換為 pandas DataFrame
df = pd.DataFrame(data)
# 如果存在,刪除 MongoDB ObjectId 字段(可選)
if ‘_id’ in df.columns:
df = df.drop(columns=[‘_id’])
logging.info(“數據成功獲取並轉換為 DataFrame!”)
return df
except Exception as e:
logging.error(f”獲取數據時發生錯誤: {e}”)
raise e
@step(enable_cache=False)
def ingest_data(collection_name: str = “historical_data”, database_name: str = “crypto_data”) -> pd.DataFrame:
logging.info(“開始從 MongoDB 的數據攝取過程。”)
try:
# 使用 fetch_data_from_mongodb 函數獲取數據
df = fetch_data_from_mongodb(collection_name=collection_name, database_name=database_name)
if df.empty:
logging.warning(“未加載任何數據。請檢查集合名稱或數據庫內容。”)
else:
logging.info(f”數據攝取完成。加載的記錄數量: {len(df)}。”)
return df
except Exception as e:
logging.error(f”從 {collection_name} 中讀取數據時發生錯誤: {e}”)
raise e
“`
我們為 ingest_data() 函數添加 @step 裝飾器,以將其聲明為我們訓練管道的一步。以同樣的方式,我們將為項目架構中的每一步編寫代碼並創建管道。
要查看我如何使用 @step 裝飾器,請查看下面的 GitHub 連結(步驟文件夾),以查看管道的其他步驟的代碼,例如數據清理、特徵工程、數據拆分、模型訓練和模型評估。
步驟 5:數據清理
在這一步中,我們將創建不同的策略來清理攝取的數據。我們將刪除不需要的列和數據中的缺失值。
“`python
class DataPreprocessor:
def __init__(self, data: pd.DataFrame):
self.data = data
logging.info(“DataPreprocessor 初始化,數據形狀: %s”, data.shape)
def clean_data(self) -> pd.DataFrame:
“””
通過刪除不必要的列、刪除缺失值的列來執行數據清理,
並返回清理後的 DataFrame。
返回:
pd.DataFrame: 清理後的 DataFrame,已刪除不必要和缺失值的列。
“””
logging.info(“開始數據清理過程。”)
# 刪除不必要的列,包括 ‘_id’(如果存在)
columns_to_drop = [
‘UNIT’, ‘TYPE’, ‘MARKET’, ‘INSTRUMENT’,
‘FIRST_MESSAGE_TIMESTAMP’, ‘LAST_MESSAGE_TIMESTAMP’,
‘FIRST_MESSAGE_VALUE’, ‘HIGH_MESSAGE_VALUE’, ‘HIGH_MESSAGE_TIMESTAMP’,
‘LOW_MESSAGE_VALUE’, ‘LOW_MESSAGE_TIMESTAMP’, ‘LAST_MESSAGE_VALUE’,
‘TOTAL_INDEX_UPDATES’, ‘VOLUME_TOP_TIER’, ‘QUOTE_VOLUME_TOP_TIER’,
‘VOLUME_DIRECT’, ‘QUOTE_VOLUME_DIRECT’, ‘VOLUME_TOP_TIER_DIRECT’,
‘QUOTE_VOLUME_TOP_TIER_DIRECT’, ‘_id’ # 將 ‘_id’ 添加到列表中
]
logging.info(“刪除列: %s”, columns_to_drop)
self.data = self.drop_columns(self.data, columns_to_drop)
# 刪除缺失值大於 0 的列
logging.info(“刪除缺失值的列。”)
self.data = self.drop_columns_with_missing_values(self.data)
logging.info(“數據清理完成。清理後的數據形狀: %s”, self.data.shape)
return self.data
def drop_columns(self, data: pd.DataFrame, columns: list) -> pd.DataFrame:
“””
從 DataFrame 中刪除指定的列。
返回:
pd.DataFrame: 刪除指定列的 DataFrame。
“””
logging.info(“刪除列: %s”, columns)
return data.drop(columns=columns, errors=”ignore”)
def drop_columns_with_missing_values(self, data: pd.DataFrame) -> pd.DataFrame:
“””
從 DataFrame 中刪除任何缺失值的列。
參數:
data: pd.DataFrame
將刪除缺失值列的 DataFrame。
返回:
pd.DataFrame: 刪除包含缺失值的列的 DataFrame。
“””
missing_columns = data.columns[data.isnull().sum() > 0]
if not missing_columns.empty:
logging.info(“缺失值的列: %s”, missing_columns.tolist())
else:
logging.info(“未找到缺失值的列。”)
return data.loc[:, data.isnull().sum() == 0]
“`
步驟 6:特徵工程
這一步從之前的數據清理步驟中獲取清理後的數據。我們創建新的特徵,如簡單移動平均 (SMA)、指數移動平均 (EMA) 和滯後及滾動統計,以捕捉趨勢、減少噪音,並從時間序列數據中做出更可靠的預測。此外,我們使用 Minmax 縮放來縮放特徵和目標變量。
“`python
import joblib
import pandas as pd
from abc import ABC, abstractmethod
from sklearn.preprocessing import MinMaxScaler
# 特徵工程策略的抽象類
class FeatureEngineeringStrategy(ABC):
@abstractmethod
def generate_features(self, df: pd.DataFrame) -> pd.DataFrame:
pass
# 計算 SMA、EMA、RSI 和其他特徵的具體類
class TechnicalIndicators(FeatureEngineeringStrategy):
def generate_features(self, df: pd.DataFrame) -> pd.DataFrame:
# 計算 SMA、EMA 和 RSI
df[‘SMA_20’] = df[‘CLOSE’].rolling(window=20).mean()
df[‘SMA_50’] = df[‘CLOSE’].rolling(window=50).mean()
df[‘EMA_20’] = df[‘CLOSE’].ewm(span=20, adjust=False).mean()
# 價格差異特徵
df[‘OPEN_CLOSE_diff’] = df[‘OPEN’] – df[‘CLOSE’]
df[‘HIGH_LOW_diff’] = df[‘HIGH’] – df[‘LOW’]
df[‘HIGH_OPEN_diff’] = df[‘HIGH’] – df[‘OPEN’]
df[‘CLOSE_LOW_diff’] = df[‘CLOSE’] – df[‘LOW’]
# 滯後特徵
df[‘OPEN_lag1’] = df[‘OPEN’].shift(1)
df[‘CLOSE_lag1’] = df[‘CLOSE’].shift(1)
df[‘HIGH_lag1’] = df[‘HIGH’].shift(1)
df[‘LOW_lag1’] = df[‘LOW’].shift(1)
# 滾動統計
df[‘CLOSE_roll_mean_14’] = df[‘CLOSE’].rolling(window=14).mean()
df[‘CLOSE_roll_std_14’] = df[‘CLOSE’].rolling(window=14).std()
# 刪除缺失值的行(由於滾動窗口、滯後)
df.dropna(inplace=True)
return df
# 縮放策略的抽象類
class ScalingStrategy(ABC):
@abstractmethod
def scale(self, df: pd.DataFrame, features: list, target: str):
pass
# MinMax 縮放的具體類
class MinMaxScaling(ScalingStrategy):
def scale(self, df: pd.DataFrame, features: list, target: str):
“””
使用 MinMaxScaler 縮放特徵和目標。
參數:
df: pd.DataFrame
包含特徵和目標的 DataFrame。
features: list
特徵列名稱的列表。
target: str
目標列名稱。
返回:
pd.DataFrame, pd.DataFrame: 縮放的特徵和目標
“””
scaler_X = MinMaxScaler(feature_range=(0, 1))
scaler_y = MinMaxScaler(feature_range=(0, 1))
X_scaled = scaler_X.fit_transform(df[features].values)
y_scaled = scaler_y.fit_transform(df[[target]].values)
joblib.dump(scaler_X, ‘saved_scalers/scaler_X.pkl’)
joblib.dump(scaler_y, ‘saved_scalers/scaler_y.pkl’)
return X_scaled, y_scaled, scaler_y
# 特徵工程上下文:這將使用策略模式
class FeatureEngineering:
def __init__(self, feature_strategy: FeatureEngineeringStrategy, scaling_strategy: ScalingStrategy):
self.feature_strategy = feature_strategy
self.scaling_strategy = scaling_strategy
def process_features(self, df: pd.DataFrame, features: list, target: str):
# 使用提供的策略生成特徵
df_with_features = self.feature_strategy.generate_features(df)
# 使用提供的策略縮放特徵和目標
X_scaled, y_scaled, scaler_y = self.scaling_strategy.scale(df_with_features, features, target)
return df_with_features, X_scaled, y_scaled, scaler_y
“`
步驟 7:數據拆分
現在,我們將處理過的數據按 80:20 的比例拆分為訓練和測試數據集。
“`python
import logging
from abc import ABC, abstractmethod
import numpy as np
from sklearn.model_selection import train_test_split
# 設置日誌配置
logging.basicConfig(level=logging.INFO, format=”%(asctime)s – %(levelname)s – %(message)s”)
# 數據拆分策略的抽象基類
class DataSplittingStrategy(ABC):
@abstractmethod
def split_data(self, X: np.ndarray, y: np.ndarray):
pass
# 簡單訓練-測試拆分的具體策略
class SimpleTrainTestSplitStrategy(DataSplittingStrategy):
def __init__(self, test_size=0.2, random_state=42):
self.test_size = test_size
self.random_state = random_state
def split_data(self, X: np.ndarray, y: np.ndarray):
logging.info(“執行簡單的訓練-測試拆分。”)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=self.test_size, random_state=self.random_state
)
logging.info(“訓練-測試拆分完成。”)
return X_train, X_test, y_train, y_test
# 數據拆分的上下文類
class DataSplitter:
def __init__(self, strategy: DataSplittingStrategy):
self._strategy = strategy
def set_strategy(self, strategy: DataSplittingStrategy):
logging.info(“切換數據拆分策略。”)
self._strategy = strategy
def split(self, X: np.ndarray, y: np.ndarray):
logging.info(“使用選定的策略拆分數據。”)
return self._strategy.split_data(X, y)
“`
步驟 8:模型訓練
在這一步中,我們訓練 LSTM 模型,並使用早期停止來防止過擬合,並通過 MLflow 的自動日誌記錄來跟踪我們的模型和實驗,並將訓練後的模型保存為 lstm_model.keras。
“`python
import numpy as np
import logging
import mlflow
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Input, LSTM, Dropout, Dense
from tensorflow.keras.regularizers import l2
from tensorflow.keras.callbacks import EarlyStopping
from typing import Any
# 模型構建策略的抽象基類
class ModelBuildingStrategy:
def build_and_train_model(self, X_train: np.ndarray, y_train: np.ndarray, fine_tuning: bool = False) -> Any:
pass
# LSTM 模型的具體策略
class LSTMModelStrategy(ModelBuildingStrategy):
def build_and_train_model(self, X_train: np.ndarray, y_train: np.ndarray, fine_tuning: bool = False) -> Any:
“””
在提供的訓練數據上訓練 LSTM 模型。
參數:
X_train (np.ndarray): 訓練數據特徵。
y_train (np.ndarray): 訓練數據標籤/目標。
fine_tuning (bool): 對於 LSTM 不適用,默認為 False。
返回:
tf.keras.Model: 訓練後的 LSTM 模型。
“””
logging.info(“構建並訓練 LSTM 模型。”)
# MLflow 自動日誌記錄
mlflow.tensorflow.autolog()
logging.info(f”X_train 的形狀: {X_train.shape}”)
# LSTM 模型定義
model = Sequential()
model.add(Input(shape=(X_train.shape[1], X_train.shape[2])))
model.add(LSTM(units=50, return_sequences=True, kernel_regularizer=l2(0.01)))
model.add(Dropout(0.3))
model.add(LSTM(units=50, return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(units=1)) # 根據你的輸出調整單元數(例如,回歸或分類)
# 編譯模型
model.compile(optimizer=”adam”, loss=”mean_squared_error”)
# 早期停止以避免過擬合
early_stopping = EarlyStopping(monitor=”val_loss”, patience=10, restore_best_weights=True)
# 擬合模型
history = model.fit(
X_train,
y_train,
epochs=50,
batch_size=32,
validation_split=0.1,
callbacks=[early_stopping],
verbose=1
)
mlflow.log_metric(“final_loss”, history.history[“loss”][-1])
# 保存訓練後的模型
model.save(“saved_models/lstm_model.keras”)
logging.info(“LSTM 模型已訓練並保存。”)
return model
“`
步驟 9:模型評估
由於這是一個回歸問題,我們使用均方誤差 (MSE)、均方根誤差 (RMSE)、平均絕對誤差 (MAE) 和 R 平方等評估指標。
“`python
import logging
import numpy as np
from abc import ABC, abstractmethod
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from typing import Dict
# 設置日誌配置
logging.basicConfig(level=logging.INFO, format=”%(asctime)s – %(levelname)s – %(message)s”)
# 模型評估策略的抽象基類
class ModelEvaluationStrategy(ABC):
@abstractmethod
def evaluate_model(self, model, X_test, y_test, scaler_y) -> Dict[str, float]:
pass
# 回歸模型評估的具體策略
class RegressionModelEvaluationStrategy(ModelEvaluationStrategy):
def evaluate_model(self, model, X_test, y_test, scaler_y) -> Dict[str, float]:
# 預測數據
y_pred = model.predict(X_test)
# 確保 y_test 和 y_pred 被重塑為 2D 陣列以進行逆轉換
y_test_reshaped = y_test.reshape(-1, 1)
y_pred_reshaped = y_pred.reshape(-1, 1)
# 逆轉換縮放的預測和真實值
y_pred_rescaled = scaler_y.inverse_transform(y_pred_reshaped)
y_test_rescaled = scaler_y.inverse_transform(y_test_reshaped)
# 扁平化數組以確保它們是 1D
y_pred_rescaled = y_pred_rescaled.flatten()
y_test_rescaled = y_test_rescaled.flatten()
# 計算評估指標
mse = mean_squared_error(y_test_rescaled, y_pred_rescaled)
rmse = np.sqrt(mse)
mae = mean_absolute_error(y_test_rescaled, y_pred_rescaled)
r2 = r2_score(y_test_rescaled, y_pred_rescaled)
# 記錄指標
logging.info(“計算評估指標。”)
metrics = {
“均方誤差 – MSE”: mse,
“均方根誤差 – RMSE”: rmse,
“平均絕對誤差 – MAE”: mae,
“R 平方 – R²”: r2
}
logging.info(f”模型評估指標: {metrics}”)
return metrics
“`
現在我們將所有上述步驟組織成一個管道。讓我們創建一個新的文件 training_pipeline.py。
“`python
from zenml import Model, pipeline
@pipeline(
model=Model(
# 名稱唯一標識此模型
name=”bitcoin_price_predictor”
),
)
def ml_pipeline():
# 數據攝取步驟
raw_data = ingest_data()
# 數據清理步驟
cleaned_data = clean_data(raw_data)
# 特徵工程步驟
transformed_data, X_scaled, y_scaled, scaler_y = feature_engineering_step(
cleaned_data
)
# 數據拆分
X_train, X_test, y_train, y_test = data_splitter_step(X_scaled=X_scaled, y_scaled=y_scaled)
# 模型訓練
model = model_training_step(X_train, y_train)
# 模型評估
evaluator = model_evaluation_step(model, X_test=X_test, y_test=y_test, scaler_y=scaler_y)
return evaluator
“`
在這裡,@pipeline 裝飾器用於將函數 ml_pipeline() 定義為 ZenML 中的管道。
要查看訓練管道的儀表板,只需運行 run_pipeline.py 腳本。讓我們創建一個 run_pipeline.py 文件。
“`python
import click
from pipelines.training_pipeline import ml_pipeline
@click.command()
def main():
run = ml_pipeline()
if __name__==”__main__”:
main()
“`
現在我們已經完成了管道的創建。運行下面的命令以查看管道儀表板。
“`bash
python run_pipeline.py
“`
運行上述命令後,它將返回跟踪儀表板的 URL,類似於這樣。
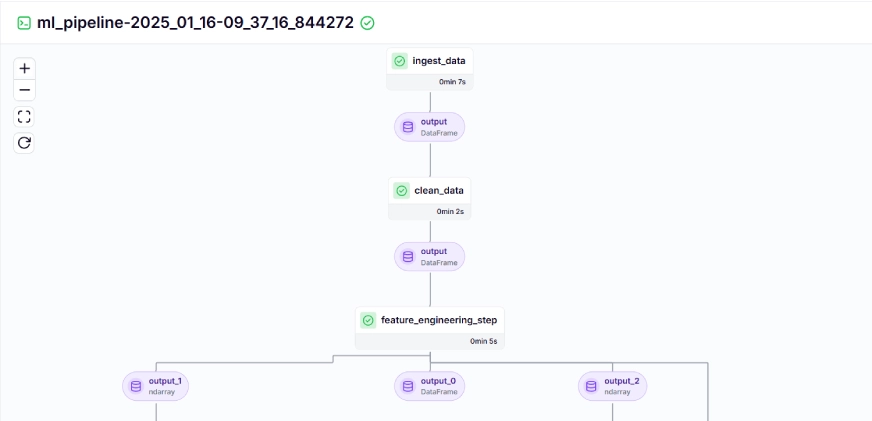
步驟 10:模型部署
到目前為止,我們已經建立了模型和管道。現在讓我們將管道推入生產,讓用戶可以進行預測。
持續部署管道
“`python
from zenml.integrations.mlflow.steps import mlflow_model_deployer_step
@pipeline
def continuous_deployment_pipeline():
trained_model = ml_pipeline()
mlflow_model_deployer_step(workers=3, deploy_decision=True, model=trained_model)
“`
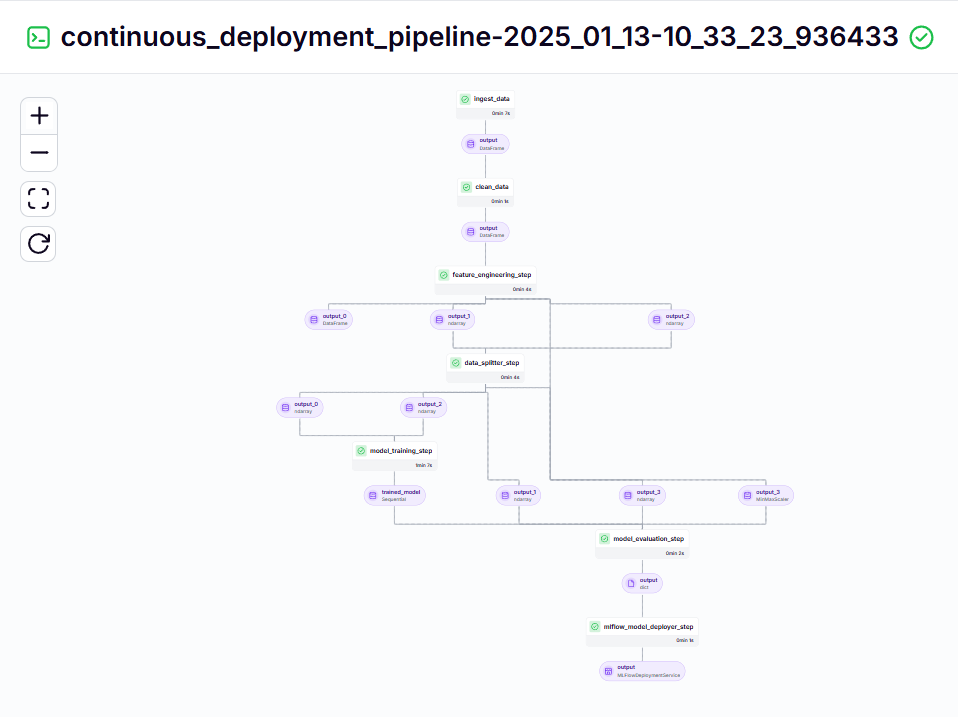
這個管道負責持續部署訓練好的模型。它首先運行 training_pipeline.py 文件中的 ml_pipeline() 來訓練模型,然後使用 MLflow 模型部署器來部署訓練好的模型。
推斷管道
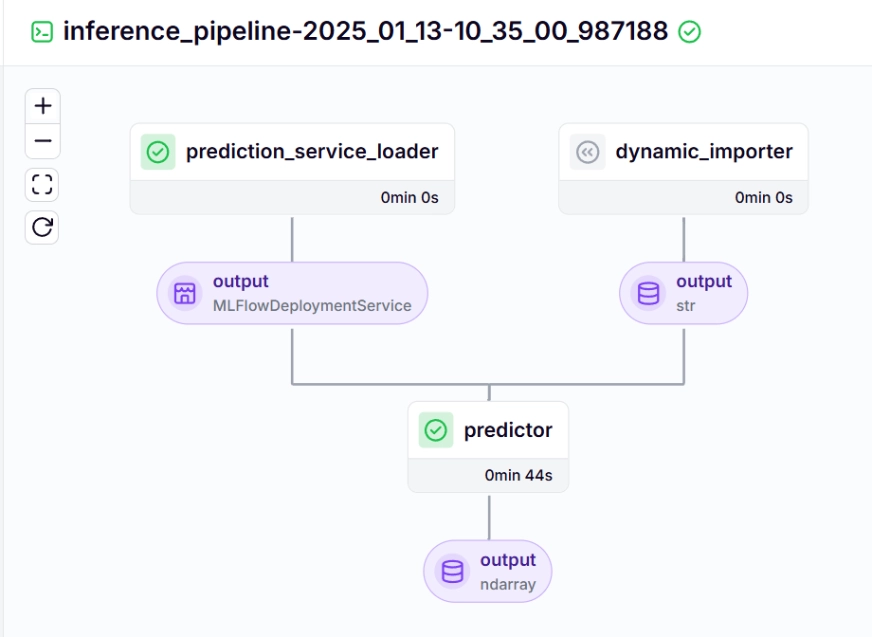
我們使用推斷管道對新數據進行預測,使用已部署的模型。讓我們看看我們如何在項目中實現這個管道。
“`python
@pipeline
def inference_pipeline(enable_cache=True):
“””運行批量推斷作業,數據從 API 加載。”””
batch_data = dynamic_importer()
model_deployment_service = prediction_service_loader(
pipeline_name=”continuous_deployment_pipeline”,
step_name=”mlflow_model_deployer_step”,
)
predictor(service=model_deployment_service, input_data=batch_data)
“`
讓我們看看推斷管道中調用的每個函數:
dynamic_importer()
這個函數加載新數據,執行數據處理,並返回數據。
“`python
@step
def dynamic_importer() -> str:
“””動態導入數據以測試模型,並帶有預期的列。”””
try:
data = {
‘OPEN’: [0.98712925, 1.],’HIGH’: [0.57191823, 0.55107652],’LOW’: [1., 0.94728144],’VOLUME’: [0.18186191, 0.],’SMA_20′: [0.90819243, 1.],’SMA_50′: [0.90214911, 1.],’EMA_20′: [0.89735654, 1.],’OPEN_CLOSE_diff’: [0.61751032, 0.57706902],’HIGH_LOW_diff’: [0.01406254, 0.02980481],
‘HIGH_OPEN_diff’: [0.13382262, 0.09172282],
‘CLOSE_LOW_diff’: [0.14140073, 0.28523136],’OPEN_lag1′: [0.64467168, 1.],
‘CLOSE_lag1’: [0.98712925, 1.],
‘HIGH_lag1’: [0.77019885, 0.57191823],
‘LOW_lag1’: [0.64465093, 1.],
‘CLOSE_roll_mean_14′: [0.94042809, 1.],’CLOSE_roll_std_14’: [0.22060724, 0.35396897],
}
df = pd.DataFrame(data)
data_array = df.iloc[0].values
reshaped_data = data_array.reshape((1, 1, data_array.shape[0])) # 單個樣本,1 個時間步,17 個特徵
logging.info(f”重塑數據: {reshaped_data.shape}”)
json_data = pd.DataFrame(reshaped_data.reshape((reshaped_data.shape[0], reshaped_data.shape[2]))).to_json(orient=”split”)
return json_data
except Exception as e:
logging.error(f”在導入數據時發生錯誤: {e}”)
raise e
“`
prediction_service_loader()
這個函數用 @step 裝飾。我們根據 pipeline_name 和 step_name 加載與已部署模型相關的部署服務,該模型已準備好處理新數據的預測查詢。
這行 existing_services=mlflow_model_deployer_component.find_model_server() 根據給定的參數(如管道名稱和管道步驟名稱)搜索可用的部署服務。如果沒有服務可用,則表示部署管道要麼未執行,要麼在部署管道中遇到問題,因此會引發 RuntimeError。
“`python
@step(enable_cache=False)
def prediction_service_loader(pipeline_name: str, step_name: str) -> MLFlowDeploymentService:
model_deployer = MLFlowModelDeployer.get_active_model_deployer()
existing_services = model_deployer.find_model_server(
pipeline_name=pipeline_name,
pipeline_step_name=step_name,
)
if not existing_services:
raise RuntimeError(
f”目前沒有由步驟 {step_name} 在管道 {pipeline_name} 中部署的 MLflow 預測服務。”
)
return existing_services[0]
“`
predictor()
這個函數通過 MLFlow 部署的模型和新數據進行預測。數據進一步處理以匹配模型的預期格式,以進行實時推斷。
“`python
@step(enable_cache=False)
def predictor(
service: MLFlowDeploymentService,
input_data: str,
) -> np.ndarray:
service.start(timeout=10)
try:
data = json.loads(input_data)
data.pop(“columns”, None)
data.pop(“index”, None)
if isinstance(data[“data”], list):
data_array = np.array(data[“data”])
else:
raise ValueError(“數據格式不正確,預期在 ‘data’ 下為列表。”)
if data_array.shape != (1, 1, 17):
data_array = data_array.reshape((1, 1, 17)) # 根據需要調整形狀
try:
prediction = service.predict(data_array)
except Exception as e:
raise ValueError(f”預測失敗: {e}”)
return prediction
except json.JSONDecodeError:
raise ValueError(“輸入數據中的 JSON 格式無效。”)
except KeyError as e:
raise ValueError(f”輸入數據中缺少預期的鍵: {e}”)
except Exception as e:
raise ValueError(f”數據處理期間發生錯誤: {e}”)
“`
要可視化持續部署和推斷管道,我們需要運行 run_deployment.py 腳本,其中將定義部署和預測配置。(請檢查下面的 run_deployment.py 代碼中的 GitHub)。
“`python
@click.option(
“–config”,
type=click.Choice([DEPLOY, PREDICT, DEPLOY_AND_PREDICT]),
default=DEPLOY_AND_PREDICT,
help=”你可以選擇僅運行部署 “
“管道以訓練和部署模型(`deploy`),或僅針對已部署模型運行預測 “
“(`predict`)。默認情況下,將運行兩者 “
“(`deploy_and_predict`)。”,
)
“`
現在讓我們運行 run_deployment.py 文件,以查看持續部署管道和推斷管道的儀表板。
“`bash
python run_deployment.py
“`
持續部署管道 – 輸出
推斷管道 – 輸出
運行 run_deployment.py 文件後,你可以看到 MLflow 儀表板鏈接,類似於這樣。
“`bash
mlflow ui –backend-store-uri file:/root/.config/zenml/local_stores/cd1eb06a-179a-4f83-9bae-9b9a5b1bd27f/mlruns
“`
現在你需要在命令行中複製並粘貼上述 MLflow UI 鏈接並運行它。
這是 MLflow 儀表板,在這裡你可以看到評估指標和模型參數:
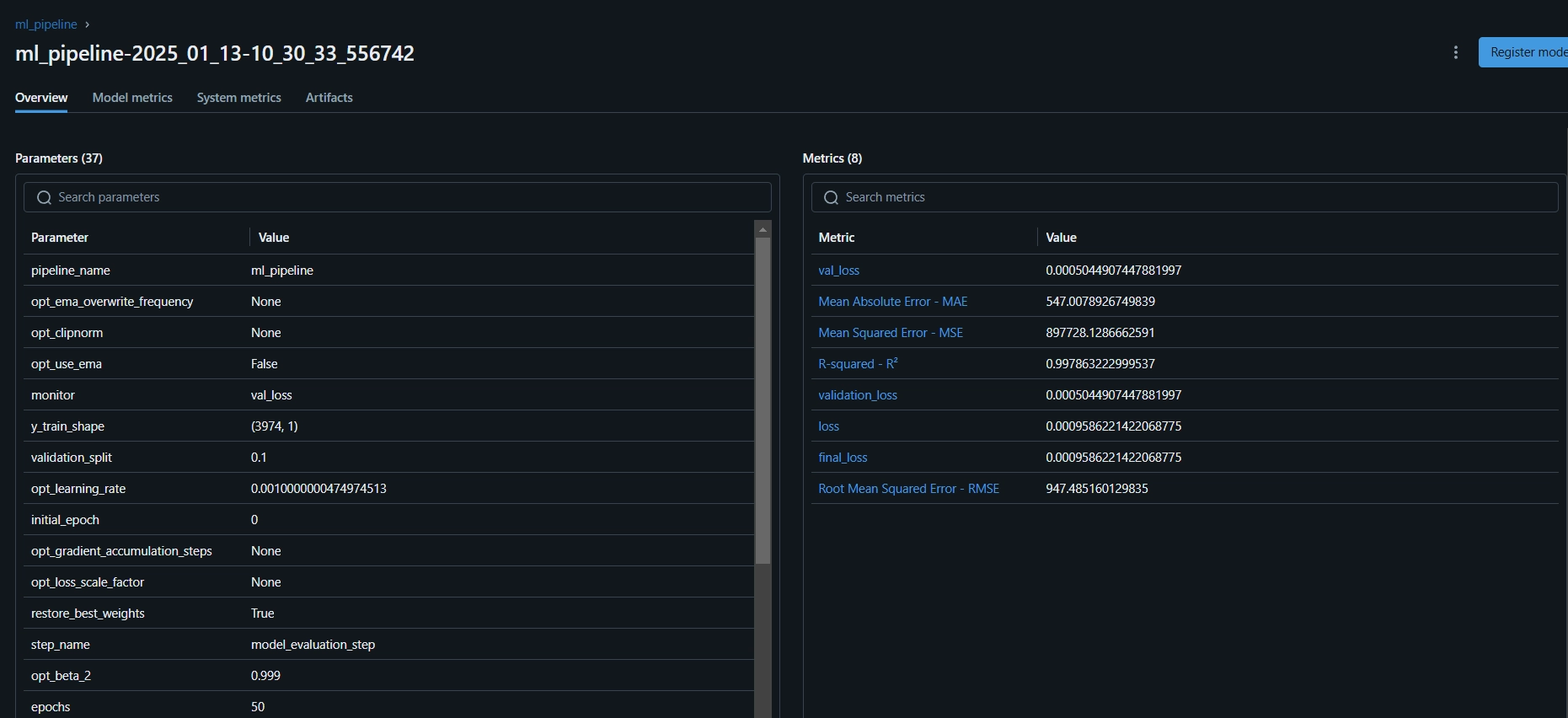
步驟 11:構建 Streamlit 應用
Streamlit 是一個出色的開源、基於 Python 的框架,用於創建互動式用戶界面,我們可以使用 Streamlit 快速構建網頁應用,而無需了解後端或前端開發。首先,我們需要在系統上安裝 Streamlit。
“`bash
# 在本地 PC 上安裝 streamlit
pip install streamlit
# 運行本地 Streamlit 網頁伺服器
streamlit run app.py
“`
同樣,你可以在 GitHub 上找到 Streamlit 應用的代碼。

這裡是項目的 GitHub 代碼和視頻解釋,幫助你更好地理解。
結論
在這篇文章中,我們成功地建立了一個端到端的、準備投入生產的比特幣價格預測 MLOps 項目。從通過 API 獲取數據和預處理到模型訓練、評估和部署,我們的項目突顯了 MLOps 在將開發與生產連接起來方面的關鍵作用。我們更接近於塑造實時預測比特幣價格的未來。API 提供了平滑訪問外部數據的方式,例如來自 CCData API 的比特幣價格數據,消除了對預先存在數據集的需求。
關鍵要點
- API 使得無縫訪問外部數據成為可能,例如來自 CCData API 的比特幣價格數據,消除了對預先存在數據集的需求。
- ZenML 和 MLflow 是強大的工具,促進了在現實應用中開發、跟踪和部署機器學習模型。
- 我們遵循最佳實踐,正確執行數據攝取、清理、特徵工程、模型訓練和評估。
- 持續部署和推斷管道對於確保模型在生產環境中保持高效和可用至關重要。
本文中顯示的媒體不屬於 Analytics Vidhya,並由作者自行決定使用。
常見問題
A. 是的,ZenML 是一個完全開源的 MLOps 框架,使從本地開發到生產管道的過渡變得簡單。
A. MLflow 通過提供實驗跟踪、模型版本控制和部署工具,使機器學習開發變得更容易。
A. 這是你在項目中會遇到的常見錯誤。只需運行 `zenml logout –local`,然後 `zenml clean`,然後再次運行 `zenml login –local`,再運行管道即可解決。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!



")




{kind=link}