


大型語言模型 (LLMs) 的目標是與人類的偏好保持一致,以確保可靠和可信的決策。然而,這些模型會產生偏見、邏輯跳躍和幻覺,使它們在涉及邏輯思考的關鍵任務中變得無效且無害。邏輯一致性問題使得開發邏輯一致的 LLMs 成為不可能。它們還使用時間推理、優化和自動化系統,導致結論的可靠性降低。
目前,將大型語言模型 (LLMs) 與人類偏好對齊的方法依賴於使用指令數據進行的監督訓練和來自人類反饋的強化學習。然而,這些方法存在幻覺、偏見和邏輯不一致等問題,從而削弱了 LLMs 的有效性。因此,大多數對 LLM 一致性的改進主要集中在簡單的事實知識或幾個陳述之間的簡單推論上,而忽略了其他更複雜的決策場景或涉及多個項目的任務。這一差距限制了它們在需要一致性的現實應用中提供連貫和可靠推理的能力。
為了評估大型語言模型 (LLMs) 的邏輯一致性,劍橋大學和莫納什大學的研究人員提出了一個通用框架,通過評估三個關鍵屬性:傳遞性、交換性和否定不變性,來量化邏輯一致性。傳遞性確保如果模型認為一個項目比第二個項目更受偏好,而第二個項目又比第三個項目更受偏好,那麼它也會得出第一個項目比第三個項目更受偏好的結論。交換性則確保無論比較項目的順序如何,模型的判斷保持不變。
同時,否定不變性被檢查以確保在處理關係否定時的一致性。這些屬性構成了模型中可靠推理的基礎。研究人員通過將 LLM 視為一個運算符函數 FFF,來正式化評估過程,該函數比較項對並分配關係決策。邏輯一致性使用如 stran(K)s_{tran}(K)stran(K) 來測量傳遞性,並使用 scomms_{comm}scomm 來評估交換性。Stran (K)s_{tran}(K)stran(K) 通過抽樣項的子集並檢測關係圖中的循環來量化傳遞性。同時,scomms_{comm}scomm 評估當比較項的順序反轉時,模型的判斷是否保持穩定。這兩個指標的範圍從 0 到 1,數值越高表示性能越好。
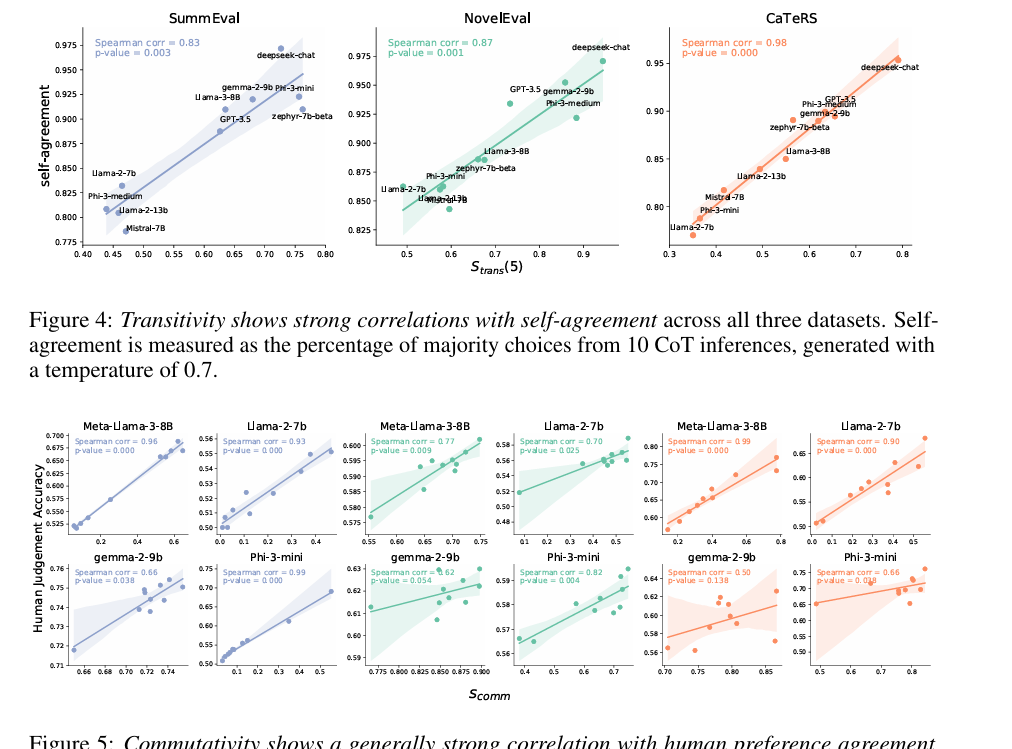
研究人員將這些指標應用於各種 LLMs,揭示了它們對排列和位置偏見等偏見的脆弱性。為了解決這個問題,他們引入了一種數據精煉和增強技術,使用排名聚合方法從嘈雜或稀疏的成對比較中估計部分或有序的偏好排名。這改善了邏輯一致性,而不損害與人類偏好的對齊,並強調了邏輯一致性在提高依賴邏輯的算法性能中的重要作用。
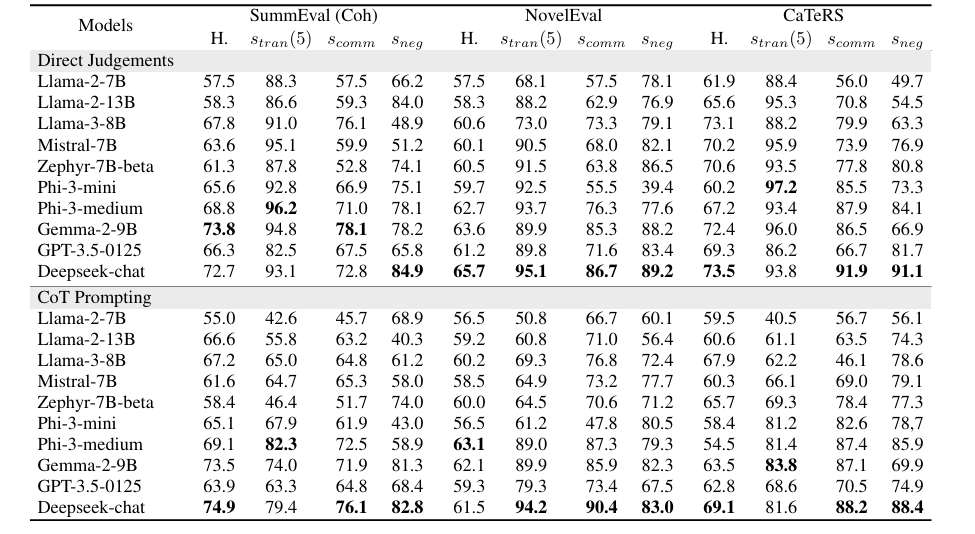
研究人員測試了三個任務以評估 LLMs 的邏輯一致性:抽象總結、文件重新排名和時間事件排序,使用的數據集包括 SummEval、NovelEval 和 CaTeRS。他們評估了傳遞性、交換性、否定不變性以及人類和自我一致性。結果顯示,像 Deepseek-chat、Phi-3-medium 和 Gemma-2-9B 等較新的模型具有更高的邏輯一致性,儘管這與人類一致性的準確性並沒有強烈相關。CaTeRS 數據集顯示出更強的一致性,專注於時間和因果關係。鏈式思考提示的結果參差不齊,有時由於增加的推理標記而降低了傳遞性。自我一致性與傳遞性相關;這表明一致的推理對邏輯一致性至關重要,模型如 Phi-3-medium 和 Gemma-2-9B 在每個任務上具有相等的可靠性,強調了更乾淨的訓練數據的必要性。
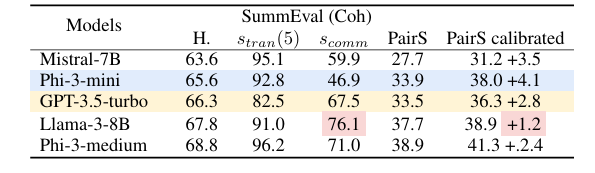
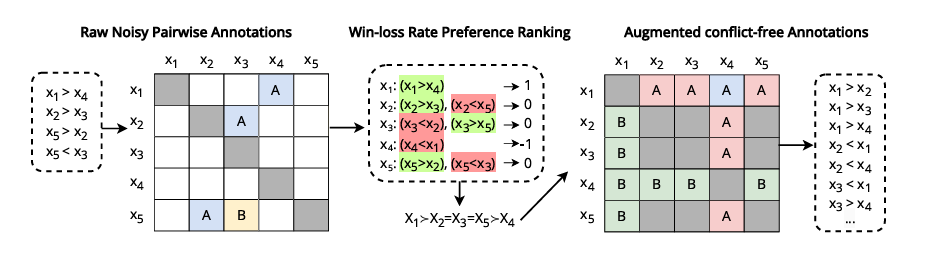
最後,研究人員展示了邏輯一致性在提高大型語言模型可靠性方面的重要性。他們提出了一種測量一致性關鍵方面的方法,並解釋了一個數據清理過程,該過程在保持與人類相關性的同時減少了缺陷的數量。這一框架可以進一步用作後續研究的指導,以改善 LLMs 的一致性,並持續努力將 LLMs 實施到決策系統中,以提高效率和生產力。
查看論文。此研究的所有榮譽歸於該項目的研究人員。同時,別忘了在 Twitter 上關注我們,加入我們的 Telegram 頻道和 LinkedIn 群組。還有,別忘了加入我們的 60k+ ML SubReddit。
🚨 免費即將舉行的 AI 網絡研討會 (2025 年 1 月 15 日):使用合成數據和評估智能提升 LLM 準確性–加入此網絡研討會,獲取提升 LLM 模型性能和準確性的可行見解,同時保護數據隱私。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!



")




{kind=link}