
:一種新穎的通用 MoE 基於擴散政策")

在模仿學習 (Imitation Learning, IL) 中,擴散政策可以產生多樣化的代理行為,但隨著模型變得越來越大且功能強大,其計算需求也隨之增加,導致訓練和推理變得更慢。這對於實時應用造成挑戰,特別是在計算能力有限的環境中,例如移動機器人。這些政策需要許多參數和去噪步驟,因此不適合在這些場景中使用。雖然這些模型可以通過增加數據量來擴展,但其龐大的計算成本仍然是一個重要的限制。
目前在機器人技術中的方法,例如基於變壓器的擴散模型,通常用於模仿學習、離線強化學習和機器人設計等任務。這些模型依賴於卷積神經網絡 (Convolutional Neural Networks, CNNs) 或變壓器,並使用像 FiLM 這樣的條件技術。雖然能夠生成多模態行為,但由於參數龐大和去噪步驟繁多,這些模型的計算成本很高,導致訓練和推理變慢,使其不適合實時應用。此外,專家混合模型 (Mixture-of-Experts, MoE) 面臨專家崩潰和效率低下的問題。儘管有負載平衡的解決方案,這些模型仍然難以優化路由器和專家,導致性能不佳。
為了解決當前方法的限制,卡爾斯魯厄理工學院 (Karlsruhe Institute of Technology) 和麻省理工學院 (MIT) 的研究人員提出了 MoDE,一種專為模仿學習和機器人設計等任務而設計的專家混合擴散政策。MoDE 通過使用噪聲條件路由和自注意機制來提高效率,以便在不同的噪聲水平下進行更有效的去噪。與依賴複雜去噪過程的傳統方法不同,MoDE 僅在每個噪聲水平上計算和整合必要的專家,從而減少延遲和計算成本。這種架構使得推理更快、更有效,同時保持性能,通過在每次前向傳播中僅使用模型參數的子集來實現顯著的計算節省。
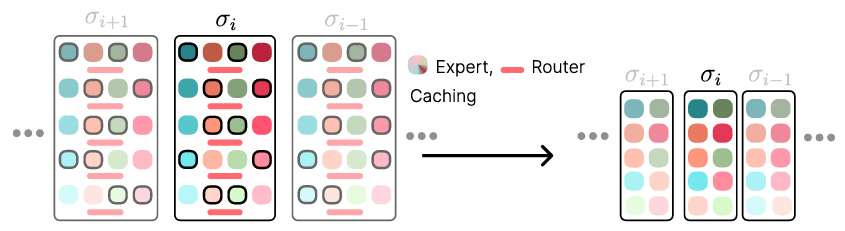
MoDE 框架採用噪聲條件的方法,專家的路由由每一步的噪聲水平決定。它使用凍結的 CLIP 語言編碼器進行語言條件,並使用 FiLM 條件的 ResNets 進行圖像編碼。該模型包含一系列變壓器區塊,每個區塊負責不同的去噪階段。通過引入噪聲感知的位置嵌入和專家緩存,MoDE 確保僅使用必要的專家,減少計算開銷。研究人員對 MoDE 的組件進行了廣泛的分析,這為設計高效且可擴展的變壓器架構提供了有用的見解。MoDE 在多機器人數據集上進行預訓練,使其在性能上超越現有的通用政策。
研究人員進行了實驗,以評估 MoDE 在幾個關鍵問題上的表現,包括與其他政策和擴散變壓器架構的性能比較、大規模預訓練對其性能、效率和速度的影響,以及在不同環境中令牌路由策略的有效性。實驗將 MoDE 與之前的擴散變壓器架構進行比較,確保公平性,並使用相似數量的活動參數,並在長期和短期任務中進行測試。MoDE 在 LIBERO–90 等基準測試中達到了最高性能,超越了其他模型,如擴散變壓器和 QueST。預訓練 MoDE 提升了其性能,顯示出其學習長期任務的能力和計算使用的效率。MoDE 在 CALVIN 語言技能基準測試中也表現出色,超越了 RoboFlamingo 和 GR-1 等模型,同時保持更高的計算效率。MoDE 在零樣本泛化任務中超越了所有基準,顯示出強大的泛化能力。

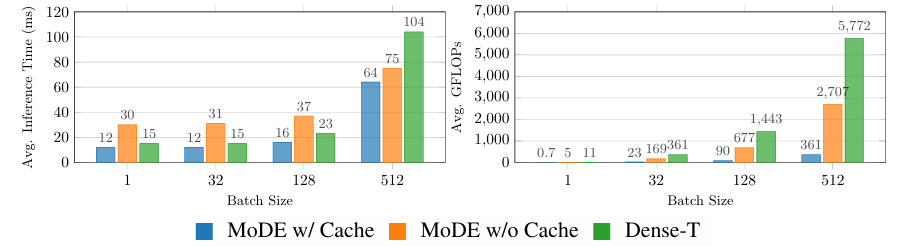
總結來說,這個提出的框架通過結合專家、變壓器和噪聲條件路由策略來提高性能和效率。該模型超越了之前的擴散政策,所需的參數更少,計算成本降低。因此,這個框架可以作為未來研究中提高模型可擴展性的基準。未來的研究也可以討論 MoDE 在其他領域的應用,因為到目前為止,它已經能夠在保持高性能水平的同時持續擴展機器學習任務。
查看 Hugging Face 上的論文和模型。所有的研究成果都歸功於這個項目的研究人員。此外,別忘了在 Twitter 上關注我們,加入我們的 Telegram 頻道和 LinkedIn 群組。還有,記得加入我們的 60k+ 機器學習 SubReddit。
🚨 免費即將舉行的 AI 網路研討會 (2025年1月15日):使用合成數據和評估智能提升 LLM 準確性–加入這個網路研討會,獲取提升 LLM 模型性能和準確性的可行見解,同時保護數據隱私。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!



")




{kind=link}