


人工智慧的進步依賴於訓練數據的可用性和質量,特別是當多模態基礎模型越來越重要時。這些模型依賴於多樣化的數據集,涵蓋文本、語音和視頻,以實現語言處理、語音識別和視頻內容生成的任務。然而,對於數據集的來源和特徵缺乏透明度,造成了重大的障礙。使用地理和語言偏向的訓練數據,或是授權不一致、文件不全的數據,會引發倫理、法律和技術上的挑戰。了解數據來源的差距對於推進負責任和包容性的人工智慧技術至關重要。
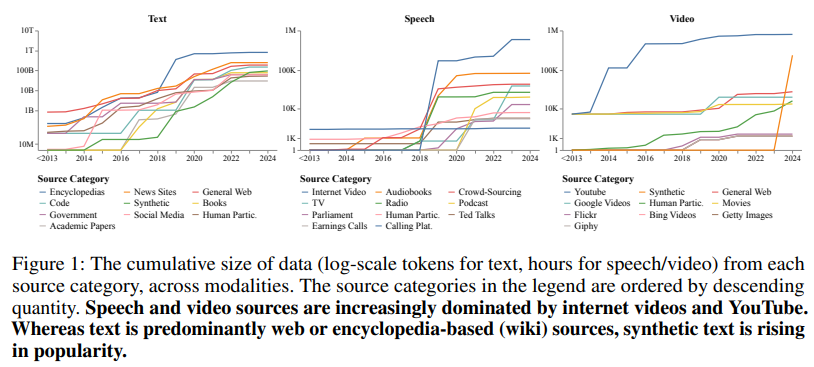
人工智慧系統在數據集的代表性和可追溯性方面面臨著關鍵問題,這限制了無偏見和合法技術的發展。目前的數據集往往過度依賴少數基於網絡或合成生成的來源。這些來源包括像 YouTube 這樣的平台,它在語音和視頻數據集中佔有重要份額,而維基百科則主導文本數據。這種依賴導致數據集未能充分代表那些被低估的語言和地區。此外,許多數據集的不明確授權做法造成法律上的模糊性,因為超過 80% 的廣泛使用數據集都帶有某種形式的未記錄或隱含限制,儘管只有 33% 明確授權用於非商業用途。
解決這些挑戰的嘗試傳統上集中在數據策展的狹窄方面,例如移除有害內容或減少文本數據集中的偏見。然而,這些努力通常僅限於單一模態,缺乏全面的框架來評估語音和視頻等多模態數據集。托管這些數據集的平台,如 HuggingFace 或 OpenSLR,往往缺乏確保元數據準確性或強制一致文件做法的機制。這種支離破碎的方法凸顯了對多模態數據集進行系統性審核的迫切需求,這需要全面考慮其來源、授權和代表性。
為了填補這一空白,數據來源倡議的研究人員進行了最大的多模態數據集縱向審核,檢查了近 4,000 個在 1990 年至 2024 年之間創建的公共數據集。這次審核涵蓋了來自 67 個國家的 659 個組織,涉及 608 種語言和近 190 萬小時的語音和視頻數據。這項廣泛的分析顯示,網絡爬蟲和社交媒體平台現在佔據了大多數訓練數據,合成來源也在快速增長。研究強調,雖然只有 25% 的文本數據集有明確的限制性授權,但幾乎所有來自 YouTube 或 OpenAI 的內容都帶有隱含的非商業限制,這引發了對法律合規性和倫理使用的質疑。
研究人員採用了細緻的方法來標註數據集,追溯其來源。這一過程揭示了數據授權和文件記錄中的重大不一致。例如,雖然 96% 的文本數據集包含商業授權,但超過 80% 的來源材料施加的限制並未在數據集的文件中體現出來。同樣,視頻數據集也高度依賴專有或受限的平台,其中 71% 的視頻數據僅來自 YouTube。這些發現凸顯了從業者在負責任地訪問數據時所面臨的挑戰,特別是當數據集被重新包裝或重新授權而未保留其原始條款時。
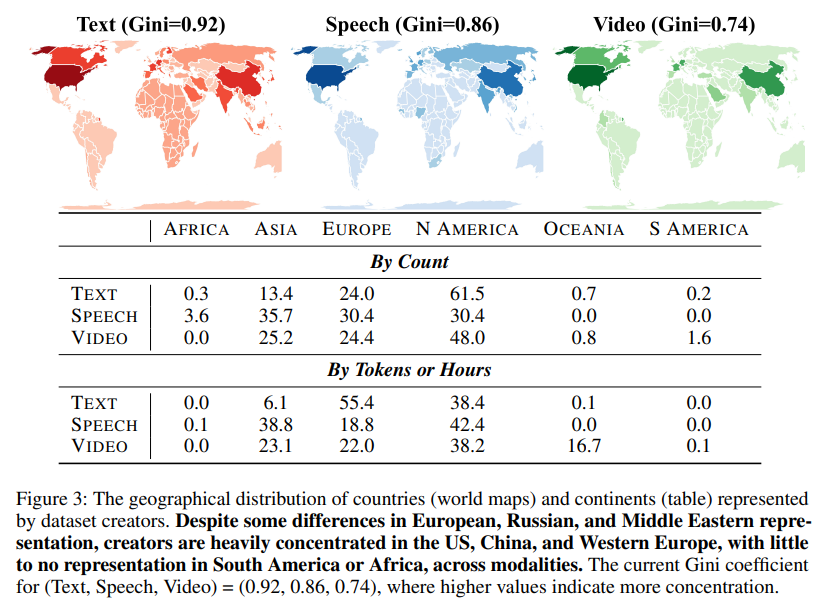
審核的顯著發現包括網絡來源數據的主導地位,特別是在語音和視頻方面。YouTube 成為最重要的來源,為每個語音和視頻內容貢獻了近 100 萬小時,超過了有聲書或電影等其他來源。合成數據集雖然仍然是整體數據的一小部分,但增長迅速,像 GPT-4 這樣的模型也作出了重要貢獻。審核還揭示了明顯的地理不平衡。北美和歐洲的組織佔據了 93% 的文本數據、61% 的語音數據和 60% 的視頻數據。相比之下,非洲和南美的地區在所有模態中的貢獻總共不到 0.2%。
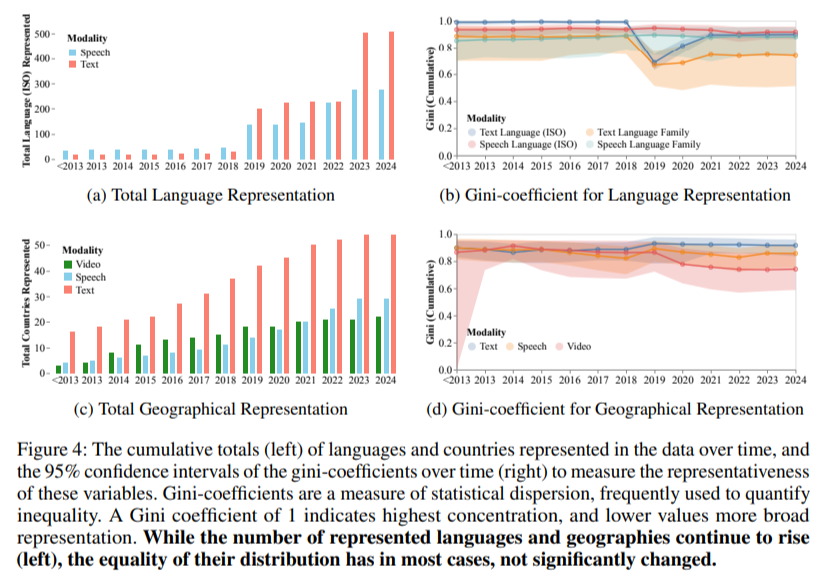
儘管在多樣性上有名義上的增長,但地理和語言的代表性仍然是一個持續的挑戰。在過去十年中,訓練數據集中所代表的語言數量已增長到超過 600 種,但在代表性平等的衡量上並未顯示出顯著改善。基尼係數(Gini coefficient)測量不平等,對於地理分佈仍然高於 0.7,對於文本數據集中的語言代表性則高於 0.8,突顯出來自西方國家的貢獻集中。對於語音數據集,儘管來自中國和印度等亞洲國家的代表性有所改善,但非洲和南美的組織仍然遠遠落後。
這項研究提供了幾個重要的收穫,為開發者和政策制定者提供了有價值的見解:
- 超過 70% 的語音和視頻數據集來自 YouTube 等網絡平台,而合成來源越來越受歡迎,佔據了近 10% 的所有文本數據標記。
- 雖然只有 33% 的數據集明確為非商業用途,但超過 80% 的來源內容受到限制。這種不匹配使法律合規性和倫理使用變得複雜。
- 北美和歐洲的組織主導了數據集的創建,而非洲和南美的貢獻不到 0.2%。語言多樣性名義上有所增長,但仍然集中在許多主導語言中。
- GPT-4、ChatGPT 和其他模型對合成數據集的興起做出了重要貢獻,這些數據集現在在訓練數據中佔據了越來越大的份額,特別是在創意和生成任務中。
- 缺乏透明度和持續的西方中心偏見呼籲對數據集策展進行更嚴格的審核和公平的做法。
總之,這次全面的審核揭示了對網絡爬蟲和合成數據日益依賴的情況、持續存在的代表性不平等以及多模態數據集中的授權複雜性。通過識別這些挑戰,研究人員為創建更透明、公平和負責任的人工智慧系統提供了一個路線圖。他們的工作強調了持續警惕和措施的必要性,以確保人工智慧能夠公平有效地服務於多樣化的社區。這項研究呼籲從業者、政策制定者和研究人員解決人工智慧數據生態系統中的結構性不平等,並優先考慮數據來源的透明性。
查看論文。這項研究的所有功勞都歸於這個項目的研究人員。此外,別忘了在 Twitter 上關注我們,加入我們的 Telegram 頻道和 LinkedIn 群組。不要忘記加入我們的 60k+ ML SubReddit。
🚨 熱門消息:LG 人工智慧研究發佈 EXAONE 3.5:三個開源雙語前沿人工智慧級模型,提供無與倫比的指令跟隨和長上下文理解,為生成人工智慧卓越的全球領導地位提供支持……。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!



")




{kind=link}