訓練大型語言模型(LLMs)對企業來說已經成為一項重要的開支。許多公司希望使用 LLM 基礎模型(FM)來處理特定領域的數據。然而,企業發現用自己的數據對這些模型進行全面微調並不划算。為了降低成本,同時繼續利用人工智慧的力量,許多公司開始使用參數高效微調(PEFT)來對 LLM 進行微調。PEFT 是一組技術,旨在將預訓練的 LLM 調整到特定任務,同時最小化需要更新的參數數量。像低秩適應(LoRA)和加權分解低秩適應(DoRA)等技術,顯著減少了可訓練參數的數量,從而降低了微調的成本。
除了成本,對 LLM 進行大規模微調還面臨重大技術挑戰。設置和配置分佈式訓練環境的過程可能很複雜,需要伺服器管理、叢集配置、網絡和分佈式計算方面的專業知識。手動管理這樣的複雜性往往會適得其反,並消耗企業在人工智慧開發上的寶貴資源。為了簡化基礎設施設置並加速分佈式訓練,AWS 在 2023 年底推出了 Amazon SageMaker HyperPod。
在這篇文章中,我們展示了如何使用 PEFT 在 AWS Trainium 上對 Meta Llama 3 模型進行高效的監督微調。我們使用 HuggingFace 的 Optimum-Neuron 軟體開發工具包(SDK)來將 LoRA 應用於微調任務,並使用 SageMaker HyperPod 作為主要計算叢集,在 Trainium 上進行分佈式訓練。使用 LoRA 監督微調 Meta Llama 3 模型,您可以進一步將微調模型的成本降低多達 50%,並將訓練時間縮短 70%。
解決方案概述
SageMaker HyperPod 的設計旨在通過提供專門構建的基礎設施來減少訓練生成式人工智慧 FM 所需的時間。使用 SageMaker HyperPod 進行訓練時,SageMaker 會主動監控叢集的健康狀況,自動替換故障節點並從檢查點恢復模型訓練。這些叢集預先配置了 SageMaker 分佈式訓練庫,使您能夠在數千個計算節點之間拆分訓練數據和模型,允許數據並行處理,同時充分利用叢集的計算和網絡基礎設施。您還可以自定義分佈式訓練。以下的架構圖提供了這些不同組件的高級概述:
計算叢集:這包含一個主節點,負責協調叢集中的工作節點的計算。由於主節點僅負責協調訓練,因此通常是一個較小的實例。在這篇文章中,我們使用 Amazon Elastic Compute Cloud(Amazon EC2)Trn1 實例作為工作節點,並使用一個 Amazon EC2 C5 實例作為主節點。
共享存儲:FSx for Lustre 被用作節點之間的共享存儲卷,以最大化數據吞吐量。它在主節點和計算節點上掛載於 /fsx。
外部存儲:Amazon Simple Storage Service(Amazon S3)用於存儲叢集的生命週期腳本、配置文件、數據集和檢查點。
調度器:SLURM 被用作叢集的作業調度器。
Trainium 晶片是專門為訓練 1000 億及以上參數模型的深度學習而設計的。Trainium 上的模型訓練得到了 AWS Neuron SDK 的支持,該 SDK 提供編譯器、運行時和分析工具,解鎖高性能和成本效益的深度學習加速。要了解更多關於 Trainium 晶片和 Neuron SDK 的信息,請參閱《歡迎來到 AWS Neuron》。
為了將 Trainium 晶片與通過 transformers 套件提供的現有模型和工具集成,Hugging Face 的 Optimum-Neuron 套件充當 Neuron 的接口。使用 Optimum-Neuron,使用者可以將 LoRA 等技術應用於微調任務,簡化將 LLM 調整到特定任務的過程,同時利用 AWS 基礎設施提供的性能增益。
傳統的微調涉及修改模型的所有參數,這可能會消耗大量計算資源和內存。PEFT 方法如 LoRA 專注於引入一小部分可訓練參數,通常以低秩矩陣的形式調整模型的行為,同時保持大多數參數不變。LoRA 的優勢在於能夠保持基礎模型的性能,同時顯著降低計算負擔和資源需求。Neuron 2.20 版本支持在 Trainium 上使用 LoRA 進行模型訓練。
在接下來的部分中,我們將通過三個步驟來介紹在 Trainium 上使用 HyperPod 的 PEFT 代碼:
設置和部署 HyperPod 叢集以進行分佈式訓練。
在 Trainium 實例上使用 dolly 15k 數據集對 Meta Llama 3-8B 模型進行微調。
模型權重整合和推理。
Amazon SageMaker HyperPod 叢集設置
在這第一部分中,您將開始設置 Amazon SageMaker HyperPod 計算環境以進行微調。
前置條件
以下是配置和部署 SageMaker HyperPod 叢集以進行微調的前置條件:
步驟 1:基礎設施設置
完成前置條件後,部署一個 AWS CloudFormation 堆疊,其中包含通過 SageMaker HyperPod 進行分佈式訓練所需的基礎設施組件。模板中指定的默認區域是 us-west-2,但您可以修改它。您還需要指定將部署子網的可用區域。該模板使用 Amazon Virtual Private Cloud(Amazon VPC)和相應的公共和私有子網進行網絡隔離來配置您的環境。它在您的 VPC 內建立其他組件,包括一個用於生命週期腳本的 S3 存儲桶和 FSx for Lustre,這是一個在 HyperPod 叢集的主節點和計算節點之間共享的文件系統。
步驟 2:叢集配置
配置並部署 HyperPod 叢集。首先通過 create_config 腳本定義基礎設施的環境變量。該腳本使用 AWS CLI 從您的 CloudFormation 堆疊中提取基礎設施組件變量,包括區域、資源 ID 和 Amazon 資源名稱(ARN)。
# 設置區域
export AWS_REGION=us-west-2
# 獲取 create_config 腳本
curl ‘https://static.us-east-1.prod.workshops.aws/public/05a78a77-24f9-4f29-867c-64c9687646e1/static/scripts/create_config.sh’ –output create_config.sh
# 設置環境變量
bash create_config.sh
source env_vars
設置環境變量後,下載啟動計算節點所需的生命週期腳本,並在將腳本上傳到 S3 存儲桶之前定義其配置設置。
# 下載生命週期腳本
git clone –depth=1 https://github.com/aws-samples/awsome-distributed-training/
# 將腳本上傳到 s3
aws s3 cp –recursive awsome-distributed-training/1.architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/ s3://${BUCKET}/src
將生命週期腳本上傳到 Amazon S3 後,創建叢集和文件系統配置。請參見 SageMaker HyperPod 工作坊的創建叢集部分以創建這些文件。在生成 cluster-config.json 和 provisioning_parameters.json 配置文件後,驗證它們並將 FSx for Lustre 配置文件上傳到 Amazon S3。
# 驗證並檢查配置是否存在已知問題
curl -O https://raw.githubusercontent.com/aws-samples/awsome-distributed-training/main/1.architectures/5.sagemaker-hyperpod/validate-config.py
python3 validate-config.py –cluster-config cluster-config.json –provisioning-parameters provisioning_parameters.json
# 將 FSx 配置上傳到 S3
aws s3 cp provisioning_parameters.json s3://${BUCKET}/src/
步驟 3:叢集部署
現在叢集的配置已經定義,您可以創建叢集。
aws sagemaker create-cluster \
–cli-input-json file://cluster-config.json \
–region $AWS_REGION
您應該能夠通過導航到 AWS 管理控制台中的 SageMaker HyperPod 來查看您的叢集,並看到名為 ml-cluster 的叢集列出。幾分鐘後,其狀態應該會從創建變更為運行中。
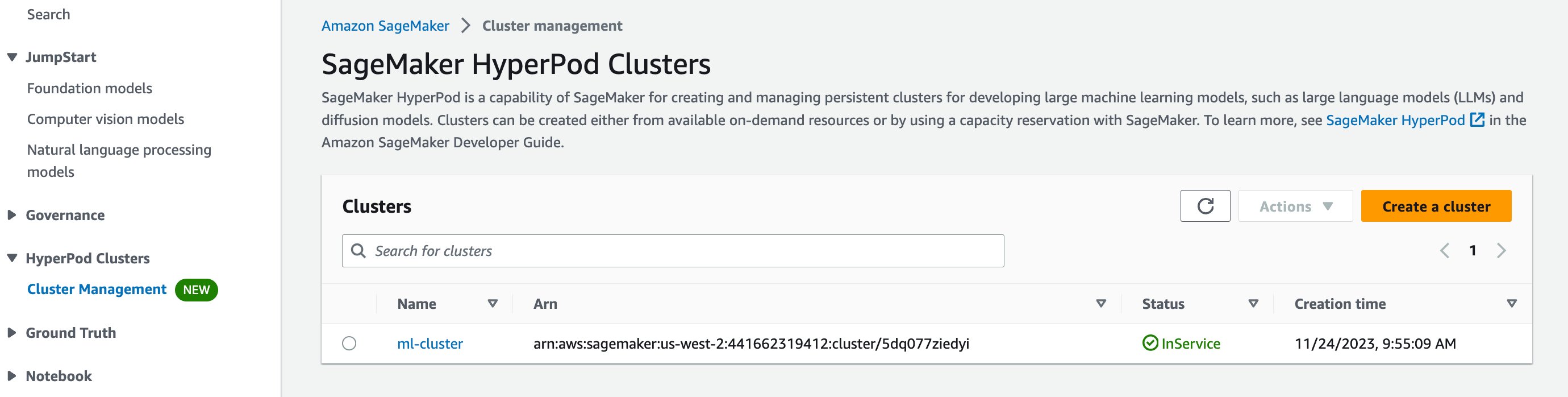
如果您選擇您的叢集,您將能夠查看計算叢集的詳細信息,包括主節點和工作節點。
安裝系統管理器會話管理器插件後,您可以使用 easy-ssh 腳本通過 ssh 進入叢集的主節點以開始訓練。
# 修改權限並 ssh
chmod +x easy-ssh.sh
./easy-ssh.sh -c controller-machine ml-cluster
# 切換到 ubuntu 用戶
sudo su – ubuntu
# 更改目錄
cd /fsx
現在您的叢集正在運行並可以通過 ssh 訪問,您可以開始通過 curl 或 AWS CLI 將模型訓練腳本上傳到共享文件系統。要獲取有關設置叢集的更多說明,請參見 SageMaker HyperPod 工作坊。
微調
現在您的 SageMaker HyperPod 叢集已經部署,您可以開始準備執行微調任務。
數據準備
成功的語言模型微調的基礎在於正確結構和準備的訓練數據。本實現專注於指令調整數據集,這些數據集構成了現代語言模型適應的骨幹。這些數據集通過三個基本組件共同創建有意義的訓練示例:
指導模型任務的指令。
提供背景信息的可選上下文。
代表所需輸出的回應。
訓練開始時,通過加載數據集並使用此結構格式化數據集示例來進行。可以通過 Hugging Face 數據集庫加載數據集,該庫提供了訪問和管理訓練數據的簡單接口。Hugging Face 還為 databricks-dolly-15k 數據集提供了此格式函數。請注意,格式函數需要嵌入到您的 train.py 文件中(如下所示)。它由 NeuronSFTTrainer 引用,以在微調期間格式化您的數據集。
# 加載數據集
dataset = load_dataset(args.dataset, split=”train”)
def format_dolly(examples):
output_text = []
for i in range(len(examples[“instruction”])):
instruction = f”### Instruction\n{examples[‘instruction’][i]}”
context = f”### Context\n{examples[‘context’][i]}” if examples[“context”][i] else None
response = f”### Answer\n{examples[‘response’][i]}”
prompt = “\n\n”.join([i for i in [instruction, context, response] if i is not None])
output_text.append(prompt)
return output_text
格式化函數使用分隔符標記(”###”)在每個訓練示例的不同組件之間創建明確的邊界。這種分離很重要,因為它幫助模型在訓練期間區分輸入的不同部分。該函數處理上下文可能缺失的情況,確保最終格式保持一致,無論所有組件是否存在。部分之間的雙換行提供了額外的結構清晰度,幫助模型識別輸入中的自然斷點。
標記化
在格式化數據集後,下一步是標記化——將文本數據轉換為模型可以理解的數字格式的過程。標記化作為人類可讀文本與驅動模型理解語言的數學運算之間的橋樑。首先,您使用 Hugging Face 的 AutoTokenizer 加載模型的標記器。
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_path)
tokenizer.pad_token = tokenizer.eos_token
AutoTokenizer 類自動選擇適合您模型的標記器,不僅加載詞彙,還加載與您的訓練配置相匹配的規則和特殊標記。將填充標記分配為結束序列標記對於因果語言建模特別重要,因為它驗證了對可變長度序列的一致處理。
標記化過程本身分為幾個階段。首先,它根據詞彙將輸入文本分解為標記。然後,這些標記被轉換為模型可以處理的數字 ID。在此過程中,標記器還處理標記序列的開始和結束的特殊標記,以及確保批次中的序列具有相同長度的填充標記。
在使用標記器時,序列長度管理成為一個關鍵考慮因素。您的最大序列長度必須在保留足夠信息以便模型理解上下文和保持在模型的架構限制之間取得平衡。太短,您可能會失去重要的上下文;太長,您可能會超出內存限制或引入不必要的計算開銷。
模型編譯和微調
對於這個解決方案,您創建了一個包含控制節點和一個工作節點的 SageMaker HyperPod 叢集。工作節點包含一個 ml.trn1.32xlarge 實例,該實例擁有 32 個 Neuron 核心。您可以使用工作節點中的所有 32 個 Neuron 核心進行分佈式微調。
步驟 1:環境設置
您首先需要安裝微調所需的 Python 套件。以下是 Python 環境設置的 bash 腳本。請注意,該解決方案使用最新發布的 Neuron SDK。在 HOME 目錄中,創建一個名為 environment.sh 的文件,並使用以下代碼運行它,命令為 sbatch ./environment.sh。在運行這些腳本之前,您可能需要修改此文中的 shell 腳本的權限,使用命令 chmod +x environment.sh。
#!/usr/bin/env bash
#SBATCH –nodes=1
#SBATCH –exclusive
#SBATCH -o /fsx/ubuntu/peft_ft/logs/8b/environment.out
sudo apt install -y python3.8-venv git
python3.8 -m venv $HOME/peft_ft/env_llama3_8B_peft
source $HOME/peft_ft/env_llama3_8B_peft/bin/activate
pip install -U pip
python3 -m pip config set global.extra-index-url “https://pip.repos.neuron.amazonaws.com”
python3 -m pip install torch-neuronx==2.1.2.2.3.0 neuronx-cc==2.15.128.0 neuronx_distributed==0.9.0 torchvision
python3 -m pip install datasets transformers peft huggingface_hub trl PyYAML
python3 -m pip install git+https://github.com/huggingface/optimum-neuron.git
環境創建完成後,切換到微調目錄,然後進入下一步:cd $HOME/peft_ft。
步驟 1:從 Hugging Face 下載基礎 Llama 3 8B 模型和標記器
從 Hugging Face 下載基礎 Meta Llama 3 8B 模型及其相應的標記器。您需要先向 Meta 申請該模型的訪問權限,然後使用您的 Hugging Face 訪問令牌下載模型。以下是 get_model.py 腳本的 Python 代碼,用於下載模型和標記器。使用 touch get_model.py 創建此文件,然後將以下代碼複製到該文件中,然後再進入下一步。
import os
import argparse
from transformers import AutoTokenizer, LlamaForCausalLM
def download_model_and_tokenizer(model_id: str, model_output_path: str, tokenizer_output_path: str, huggingface_token: str = None) -> None:
huggingface_token = os.environ.get(“HUGGINGFACE_TOKEN”, None)
model = LlamaForCausalLM.from_pretrained(model_id, token=huggingface_token)
model.save_pretrained(model_output_path)
tokenizer = AutoTokenizer.from_pretrained(model_id, token=huggingface_token)
tokenizer.save_pretrained(tokenizer_output_path)
if __name__ == “__main__”:
parser = argparse.ArgumentParser()
parser.add_argument(“–model_id”, type=str, required=True, help=”Hugging Face Model id”)
parser.add_argument(“–model_output_path”, type=str, required=True, help=”Path to save model/weights file”)
parser.add_argument(“–tokenizer_output_path”, type=str, required=True, help=”Path to save tokenizer file”)
args, _ = parser.parse_known_args()
download_model_and_tokenizer(model_id=args.model_id, model_output_path=args.model_output_path, tokenizer_output_path=args.tokenizer_output_path)
接下來,創建 bash 腳本 touch get_model.sh,並使用以下代碼運行它,命令為 sbatch ./get_model.sh。這將觸發 get_model.py 腳本以使用 Slurm 下載模型和標記器。由於您正在使用 Llama 3 8B 模型,Hugging Face 要求您在下載之前使用訪問令牌進行身份驗證。在運行腳本之前,請確保將您的訪問令牌添加到 get_model.sh 中。
#!/bin/bash
#SBATCH –nodes=1
#SBATCH –exclusive
#SBATCH -o /fsx/ubuntu/peft_ft/logs/8b/get_model.out
export OMP_NUM_THREADS=1
export HUGGINGFACE_TOKEN=”“
source $HOME/peft_ft/env_llama3_8B_peft/bin/activate
srun python3 $HOME/peft_ft/get_model.py \
–model_id meta-llama/Meta-Llama-3-8B-Instruct \
–model_output_path $HOME/peft_ft/model_artifacts/llama3-8B \
–tokenizer_output_path $HOME/peft_ft/tokenizer/llama3-8B
步驟 2:預編譯模型
在 Trainium 上訓練深度學習模型需要模型編譯。為此,使用 neuron_parallel_compile CLI 工具,它將從腳本的試運行中提取圖形,並對計算圖進行並行預編譯。請注意,模型預編譯的腳本與實際訓練的腳本相同,除了 max_steps。這是因為預編譯不需要完成整個訓練週期;相反,它需要大約 10 步訓練來提取圖形。在編譯模型之前,您需要創建訓練腳本,使用 touch train.py,該腳本用於預編譜和模型微調步驟。創建文件後,添加以下代碼,並包含之前提到的格式函數。
import os
import torch
import argparse
from datasets import load_dataset
from peft import LoraConfig
from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
from optimum.neuron import NeuronSFTConfig, NeuronSFTTrainer
from optimum.neuron.distributed import lazy_load_for_parallelism
import torch_xla.core.xla_model as xm
# 在此處添加 format_dolly 函數
def training_function(args):
dataset = load_dataset(args.dataset, split=”train”)
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_path)
tokenizer.pad_token = tokenizer.eos_token
with lazy_load_for_parallelism(tensor_parallel_size=args.tp_size):
model = AutoModelForCausalLM.from_pretrained(
args.model_path,
low_cpu_mem_usage=True,
torch_dtype=torch.bfloat16 if args.bf16 else torch.float32
)
lora_config = LoraConfig(
r=16,
lora_alpha=16,
lora_dropout=0.05,
target_modules=[“q_proj”, “v_proj”],
bias=”none”,
task_type=”CAUSAL_LM”,
)
training_args = NeuronSFTConfig(
output_dir=args.model_checkpoint_path,
overwrite_output_dir=True,
num_train_epochs=args.epochs,
per_device_train_batch_size=args.train_batch_size,
gradient_accumulation_steps=args.gradient_accumulation_steps,
learning_rate=args.learning_rate,
weight_decay=args.weight_decay,
warmup_steps=args.warmup_steps,
bf16=args.bf16,
tensor_parallel_size=args.tp_size,
pipeline_parallel_size=args.pp_size,
save_steps=args.checkpoint_frequency,
logging_steps=100,
max_steps=args.max_steps,
)
trainer = NeuronSFTTrainer(
args=training_args,
model=model,
peft_config=lora_config,
tokenizer=tokenizer,
train_dataset=dataset,
formatting_func=format_dolly,
)
trainer.train()
trainer.save_model(args.model_final_path)
if __name__ == “__main__”:
parser = argparse.ArgumentParser()
parser.add_argument(“–model_path”, type=str)
parser.add_argument(“–tokenizer_path”, type=str)
parser.add_argument(“–epochs”, type=int)
parser.add_argument(“–train_batch_size”, type=int)
parser.add_argument(“–learning_rate”, type=float)
parser.add_argument(“–weight_decay”, type=float)
parser.add_argument(“–bf16”, type=bool)
parser.add_argument(“–tp_size”, type=int)
parser.add_argument(“–pp_size”, type=int)
parser.add_argument(“–gradient_accumulation_steps”, type=int)
parser.add_argument(“–warmup_steps”, type=int)
parser.add_argument(“–early_stopping_patience”, type=int)
parser.add_argument(“–checkpoint_frequency”, type=int)
parser.add_argument(“–dataset”, type=str)
parser.add_argument(“–max_steps”, type=int)
parser.add_argument(“–max_seq_length”, type=int)
parser.add_argument(“–model_checkpoint_path”, type=str)
parser.add_argument(“–model_final_path”, type=str)
args = parser.parse_args()
training_function(args)
創建訓練文件後,使用以下代碼創建 compile.sh 腳本,該腳本將觸發 finetune-llama3-8B.sh 以使用 neuron_parallel_compile 命令編譯 Llama 3 8B 模型。您可以使用 sbatch compile.sh 命令運行此腳本。
#!/bin/bash
#SBATCH –nodes=1
#SBATCH –exclusive
#SBATCH -o /fsx/ubuntu/peft_ft/logs/8b/compile.out
source $HOME/peft_ft/env_llama3_8B_peft/bin/activate
export NEURON_EXTRACT_GRAPHS_ONLY=0
srun bash ${HOME}/peft_ft/finetune-llama3-8B.sh
以下是 finetune-llama3-8B.sh 腳本,其中列出了模型微調的超參數。該腳本使用張量並行性進行訓練,並且並行度為 8。在 ml.trn1.32xlarge 實例中擁有 32 個 Neuron 核心,您獲得的數據並行度為 4。請注意,該腳本還設置了 XLA_USE_BF16=1,以將 torch.float 和 torch.double 張量映射到 bfloat16 張量。這可以減少內存佔用並提高性能。然後,腳本將 gradient_accumulation_steps 設置為 3,以獲得更大的有效批次大小進行梯度更新。
#!/bin/bash
GPUS_PER_NODE=32
if [ $NEURON_EXTRACT_GRAPHS_ONLY -gt 0 ]; then
MAX_STEPS=10
MAYBE_COMPILE=”neuron_parallel_compile”
else
MAX_STEPS=-1
fi
declare -a TORCHRUN_ARGS=(
–nproc_per_node=$GPUS_PER_NODE
–nnodes=$SLURM_JOB_NUM_NODES
)
export TRAIN_SCRIPT=${HOME}/peft_ft/train.py
declare -a TRAINING_ARGS=(
–bf16 True \
–checkpoint_frequency 400 \
–dataset “databricks/databricks-dolly-15k” \
–max_steps $MAX_STEPS \
–max_seq_length 1024 \
–epochs 1 \
–gradient_accumulation_steps 3 \
–learning_rate 2e-05 \
–model_path “/fsx/ubuntu/peft_ft/model_artifacts/llama3-8B” \
–tokenizer_path “/fsx/ubuntu/peft_ft/tokenizer/llama3-8B” \
–model_checkpoint_path “/fsx/ubuntu/peft_ft/model_checkpoints” \
–model_final_path “/fsx/ubuntu/peft_ft/model_checkpoints/final” \
–tp_size 8 \
–pp_size 1 \
–train_batch_size 1 \
–warmup_steps 100 \
–weight_decay 0.01
)
$MAYBE_COMPILE torchrun “${TORCHRUN_ARGS[@]}” $TRAIN_SCRIPT “${TRAINING_ARGS[@]}”
步驟 3:模型微調
在模型編譯完成後,您可以通過重用 compile.sh 腳本開始模型微調。為此,通過在 compile.sh 中設置 export NEURON_EXTRACT_GRAPHS_ONLY=-1 來防止使用 neuron_parallel_compile 工具,然後重新運行該腳本以開始微調模型。在開始微調任務之前,您可能需要刪除在之前模型編譯步驟中創建的 model_consolidation 目錄。
模型整合
在處理分佈式機器學習工作流程時,您經常需要有效地管理和合併模型權重。讓我們探討在執行 LoRA 微調時經常遇到的兩個基本過程:檢查點整合和權重合併。
檢查點整合
在分佈式訓練期間,您的模型檢查點通常根據您提供的模型並行配置分散在多個設備上。要將這些部分重新組合在一起,您將使用整合過程。您的整合函數處理三個主要任務。首先,它將分佈式檢查點合併為統一模型。然後,它通過分塊處理張量來有效管理內存。最後,它創建帶有索引文件的分片輸出,以便快速訪問。
LoRA 權重合併
當您使用 LoRA 時,您需要將這些適配器與基礎模型合併。合併過程非常簡單,但需要仔細注意細節。首先加載您的基礎模型和 LoRA 配置。然後將 LoRA 權重名稱轉換為與基礎模型結構匹配。該過程以合併適配器並以分片格式保存最終模型結束。
為了將這些工具付諸實踐,您可以在微調任務完成後使用以下腳本。首先,創建 Python 文件 touch consolidation.py 和 shell 文件 touch consolidation.sh,使用以下代碼。
import argparse
import json
from pathlib import Path
from huggingface_hub import split_torch_state_dict_into_shards
from safetensors.torch import save_file
from optimum.neuron.distributed.checkpointing import consolidate_model_parallel_checkpoints
import torch
def custom_consolidate_to_unified_checkpoint(checkpoint_dir: str, output_dir: str, save_format: str = “safetensors”):
output_dir.mkdir(parents=True, exist_ok=True)
state_dict = consolidate_model_parallel_checkpoints(checkpoint_dir)
for key, value in state_dict.items():
if isinstance(value, torch.Tensor):
state_dict[key] = value.contiguous()
split_result = split_torch_state_dict_into_shards(state_dict, max_shard_size=”5GB”)
# 保存分片
for shard_file, shard_tensors in split_result.filename_to_tensors.items():
shard_dict = {name: state_dict[name] for name in shard_tensors}
shard_path = output_dir / shard_file
if save_format == “safetensors”:
save_file(shard_dict, shard_path, metadata={“format”: “pt”})
else:
torch.save(shard_dict, shard_path)
index = {
“metadata”: split_result.metadata,
“weight_map”: split_result.tensor_to_filename
}
index_file = “model.safetensors.index.json” if save_format == “safetensors” else “pytorch_model.bin.index.json”
with open(output_dir / index_file, “w”) as f:
json.dump(index, f, indent=2)
if __name__ == “__main__”:
parser = argparse.ArgumentParser()
parser.add_argument(“–input_dir”, type=str, required=True)
parser.add_argument(“–output_dir”, type=str, required=True)
parser.add_argument(“–save_format”, type=str, choices=[“safetensors”, “pytorch”])
args = parser.parse_args()
output_dir = Path(args.output_dir)
checkpoint_dir = Path(args.input_dir) / “adapter_shards”
custom_consolidate_to_unified_checkpoint(
checkpoint_dir=checkpoint_dir,
output_dir=output_dir,
save_format=args.save_format
)
這段代碼將在訓練過程中生成的分片檢查點文件整合為統一的 LoRA 適配器 safetensor 格式。在保存文件後,您可以調用此腳本以觸發模型檢查點整合任務。您提供的輸入目錄指向您微調模型的分片檢查點,輸出目錄則是整合的 LoRA 適配器 safetensor 文件。您可以使用 sbatch consolidation.sh 觸發此操作。
#!/bin/bash
#SBATCH –nodes=1
#SBATCH –exclusive
export OMP_NUM_THREADS=1
source $HOME/peft_ft/env_llama3_8B_peft/bin/activate
srun python3 “$HOME/peft_ft/consolidation.py” \
–input_dir “/fsx/ubuntu/peft_ft/model_checkpoints/checkpoint-1251” \
–output_dir “$HOME/peft_ft/model_checkpoints/adapter_shards_consolidation”\
–save_format “safetensors”
整合完成後,您需要將整合文件中的 LoRA 適配器權重與基礎模型的權重合併。首先,創建一個新的 Python 文件 touch merge_lora.py 和 shell 文件 merge_lora.sh,使用以下代碼。
import json
from peft import LoraConfig, PeftModel
from transformers import AutoModelForCausalLM
import torch
import argparse
from safetensors import safe_open
def merge_lora_weights(args):
base_model = AutoModelForCausalLM.from_pretrained(args.base_model_path)
with open(args.adapter_config_path, “r”) as f:
config_dict = json.load(f)
peft_config = LoraConfig(**config_dict)
model = PeftModel(base_model, peft_config)
lora_weights_tensors = {}
with safe_open(args.lora_safetensors_path, framework=”pt”, device=”cpu”) as f:
for k in f.keys():
lora_weights_tensors[k] = f.get_tensor(k)
for layer_name in list(lora_weights_tensors):
if ‘layer’ in layer_name and ‘lora’ in layer_name:
new_layer_name = layer_name.replace(‘weight’, ‘default.weight’)
lora_weights_tensors[new_layer_name] = lora_weights_tensors[layer_name].clone()
del lora_weights_tensors[layer_name]
else:
del lora_weights_tensors[layer_name]
updated_state_dict = model.state_dict().copy()
for layer, weights in lora_weights_tensors.items():
updated_state_dict[layer] = weights
model.load_state_dict(updated_state_dict)
merged_model = model.merge_and_unload()
merged_model.save_pretrained(args.final_model_path, safe_serialization=True, max_shard_size=”5GB”)
if __name__ == “__main__”:
parser = argparse.ArgumentParser()
parser.add_argument(“–final_model_path”, type=str)
parser.add_argument(“–adapter_config_path”, type=str)
parser.add_argument(“–base_model_path”, type=str)
parser.add_argument(“–lora_safetensors_path”, type=str)
args = parser.parse_args()
merge_lora_weights(args)
#!/bin/bash
#SBATCH –nodes=1
#SBATCH –exclusive
#SBATCH –output=/fsx/ubuntu/peft_ft/logs/8b/lora_weights.log
export OMP_NUM_THREADS=1
source $HOME/peft_ft/env_llama3_8B_peft/bin/activate
srun python3 “$HOME/peft_ft/merge_lora.py” \
–final_model_path “/fsx/ubuntu/peft_ft/model_checkpoints/final_model_output” \
–adapter_config_path “/fsx/ubuntu/peft_ft/model_checkpoints/checkpoint-1251/adapter_config.json”\
–base_model_path “/fsx/ubuntu/peft_ft/model_artifacts/llama3-8B” \
–lora_safetensors_path “/fsx/ubuntu/peft_ft/model_checkpoints/adapter_shards_consolidation/model.safetensors”
使用 sbatch merge_lora.sh 觸發運行以合併模型權重。這裡的 base_model_path 參數是您在“模型編譯和微調”步驟 1 中從 Hugging Face 下載模型的本地目錄。同樣,adapter_config_path 參數將是之前下載的模型配置文件,而 lora_safetensors_path 參數將是由 LoRA 整合在前一步生成的 model.safetensor 文件的路徑。
推理
在整合和合併之後,safetensors 文件將保存到您的 final_model_path 輸出目錄中,該目錄包含微調後的更新模型權重。使用這些更新的權重,您可以加載並生成對您訓練模型的預測,以檢查微調模型是否理解它所微調的 databricks-dolly-15k 數據集,選擇數據集中的一個問題進行驗證,如下圖所示。
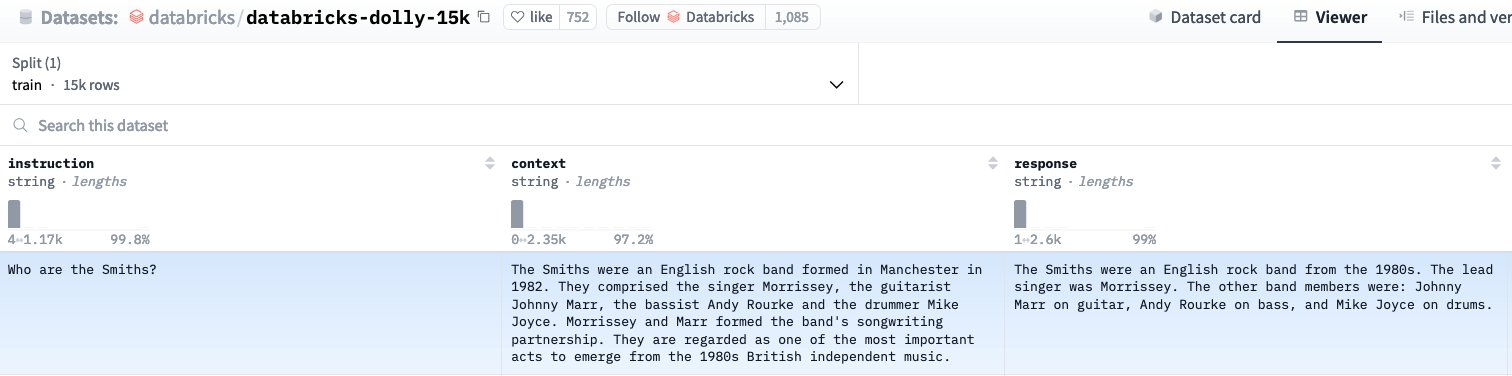
使用 Hugging Face 的 LlamaForCausalLM 類,您可以加載新微調的模型,並生成對問題“史密斯一家是誰?”的預測(如下圖所示):

將生成的答案與來自訓練數據集的真實上下文和回應進行比較,可以清楚地看出微調後的 Meta Llama 3 模型現在理解這些數據,並能夠對提出的問題給出連貫的回答。
結果
技術
可訓練參數
每秒處理樣本
訓練時間(分鐘)
FPFT
7,570,591,744
2.083
90
PEFT
6,815,744
3.554
53
為了基準測試微調模型在單個 ml.trn1.32xlarge 上使用 LoRA 的性能,我們將其與模型在三個訓練週期中的全參數微調(FPFT)進行了比較。測量每秒處理的訓練樣本顯示,LoRA 微調模型的吞吐量提高了 70%,訓練時間減少。隨後,對 dolly 15k 數據集進行三個週期的微調所需的按需小時數與 FPFT 相比減半,從而使訓練成本降低了 50%。
清理
要清理為這篇文章提供的資源,首先刪除 SageMaker HyperPod 叢集。這可以通過 AWS CLI 或在 SageMaker 控制台中完成。
aws sagemaker delete-cluster –cluster-name ml-cluster
刪除叢集後,刪除 CloudFormation 模板以刪除剩餘的資源。
aws cloudformation delete-stack –stack-name sagemaker-hyperpod
結論
在這篇文章中,我們向您展示了如何設置 SageMaker HyperPod 計算叢集以進行訓練。然後,我們展示了如何使用 LoRA 在 Trainium 上對 Meta Llama 3 模型進行多節點分佈式微調。最後,我們展示了如何在分佈式訓練環境中整合模型權重,以生成微調後模型的連貫預測。
關於作者
 Georgios Ioannides 是 AWS 生成式人工智慧創新中心的深度學習架構師。在加入 AWS 之前,Georgios 在初創公司工作,專注於信號處理、深度學習以及語音、視覺和文本應用的多模態和跨模態機器學習系統。他擁有倫敦帝國學院和卡內基梅隆大學的碩士學位。
Georgios Ioannides 是 AWS 生成式人工智慧創新中心的深度學習架構師。在加入 AWS 之前,Georgios 在初創公司工作,專注於信號處理、深度學習以及語音、視覺和文本應用的多模態和跨模態機器學習系統。他擁有倫敦帝國學院和卡內基梅隆大學的碩士學位。
 Bingchen Liu 是 AWS 生成式人工智慧創新中心的機器學習工程師。在加入 AWS 之前,他在 ADP 擔任首席機器學習工程師,專注於 RAG 應用、向量數據庫、模型開發和服務。他擁有哥倫比亞大學的計算機科學碩士學位和南方衛理公會大學的統計學博士學位。
Bingchen Liu 是 AWS 生成式人工智慧創新中心的機器學習工程師。在加入 AWS 之前,他在 ADP 擔任首席機器學習工程師,專注於 RAG 應用、向量數據庫、模型開發和服務。他擁有哥倫比亞大學的計算機科學碩士學位和南方衛理公會大學的統計學博士學位。
 Hannah Marlowe 是 AWS 生成式人工智慧創新中心的模型定制高級經理。她的團隊專注於幫助客戶使用其獨特和專有數據開發差異化的生成式人工智慧解決方案,以實現關鍵業務成果。她擁有愛荷華大學的物理學博士學位,專注於天文 X 射線分析和儀器開發。在工作之外,她喜歡在科羅拉多的山區徒步旅行、山地自行車和滑雪。
Hannah Marlowe 是 AWS 生成式人工智慧創新中心的模型定制高級經理。她的團隊專注於幫助客戶使用其獨特和專有數據開發差異化的生成式人工智慧解決方案,以實現關鍵業務成果。她擁有愛荷華大學的物理學博士學位,專注於天文 X 射線分析和儀器開發。在工作之外,她喜歡在科羅拉多的山區徒步旅行、山地自行車和滑雪。
 Jeremy Roghair 是 AWS 生成式人工智慧創新中心的機器學習工程師,專注於為客戶開發分佈式訓練工作負載和模型托管的生成式人工智慧解決方案。在加入 AWS 之前,Jeremy 在金融/保險行業擔任數據科學家,並在愛荷華州立大學獲得計算機科學碩士學位,研究強化學習。
Jeremy Roghair 是 AWS 生成式人工智慧創新中心的機器學習工程師,專注於為客戶開發分佈式訓練工作負載和模型托管的生成式人工智慧解決方案。在加入 AWS 之前,Jeremy 在金融/保險行業擔任數據科學家,並在愛荷華州立大學獲得計算機科學碩士學位,研究強化學習。






")




{kind=link}