


大型語言模型 (LLMs) 在許多語言任務中展現了驚人的能力。然而,這些模型的表現受到訓練過程中使用的數據影響很大。
在這篇文章中,我們將介紹如何準備自己的數據集來訓練 LLM。無論你的目標是針對特定任務微調一個已訓練的模型,還是繼續進行針對特定領域的預訓練,擁有一個精心策劃的數據集對於達到最佳表現至關重要。
數據預處理
文本數據可以來自不同的來源,並存在各種格式,如 PDF、HTML、JSON,以及 Microsoft Office 文件(如 Word、Excel 和 PowerPoint)。很少會有現成的文本數據可以直接處理並用於 LLM 的訓練。因此,LLM 數據準備流程的第一步是從這些不同的來源和格式中提取和整理數據。在這一步中,你需要從多個來源讀取數據,使用光學字符識別 (OCR) 工具提取掃描的 PDF 文本,使用 HTML 解析器處理網頁文件,還有專門的庫來處理 Microsoft Office 文件等專有格式。通常會去除或標準化非文本元素,如 HTML 標籤和非 UTF-8 字符。
接下來的步驟是過濾低質量或不需要的文件。常見的過濾模式包括:
根據元數據(如文件名稱或 URL)進行過濾。
基於內容的過濾,如排除任何有毒或有害的內容或個人識別信息 (PII)。
使用正則表達式過濾特定字符模式。
過濾包含過多重複句子或 n-gram 的文件。
過濾特定語言,如英語。
其他質量過濾標準,如文件中的單詞數、平均單詞長度、字母字符與非字母字符的比例等。
基於模型的質量過濾,使用輕量級文本分類器來識別低質量文件。例如,FineWeb-Edu 分類器用於分類網頁的教育價值。
從各種文件格式中提取文本可能是一項不簡單的任務。幸運的是,許多高級庫可以顯著簡化這個過程。我們將使用幾個示例來演示如何提取文本,並在後面討論如何擴展到大型文檔集合。
HTML 預處理
在處理 HTML 文檔時,需去除非文本數據,如文檔標記標籤、內聯 CSS 樣式和內聯 JavaScript。此外,將結構化對象(如列表、表格和示例代碼塊)轉換為 Markdown 格式。trafilatura 庫提供了一個命令行界面 (CLI) 和 Python SDK,用於以這種方式轉換 HTML 文檔。以下代碼片段演示了該庫的使用,通過在 Amazon SageMaker 博客文章中使用 torchtune 提取和預處理 Fine-tune Meta Llama 3.1 模型的 HTML 數據。
trafilatura 提供了許多處理 HTML 的功能。在前面的示例中,fetch_url 用於獲取原始 HTML,html2txt 提取文本內容,包括導航鏈接、相關內容鏈接和其他文本內容。最後,extract 方法提取主要內容,即博客文章本身。前面代碼的輸出應如下所示:
PDF 處理
PDF 是一種常見的格式,用於在組織內部存儲和分發文檔。從 PDF 中提取乾淨的文本可能會面臨多種挑戰。PDF 可能使用複雜的佈局,包括文本列、圖像、表格和圖形。它們還可能包含無法被標準庫解析的嵌入字體和圖形。與 HTML 不同,PDF 沒有結構性信息可供使用,如標題、段落、列表等,這使得解析 PDF 文檔變得更加困難。如果可能,應避免解析 PDF,特別是當文檔存在其他格式(如 HTML、Markdown 或 DOCX 文件)時。在無法使用其他格式的情況下,可以使用 pdfplumber、pypdf 和 pdfminer 等庫來幫助從 PDF 中提取文本和表格數據。以下是使用 pdfplumber 解析 2023 年 Amazon 年度報告 PDF 的第一頁的示例。
pdfplumber 提供邊界框信息,可用於去除多餘的文本,如頁眉和頁腳。然而,該庫僅適用於包含文本的 PDF,例如數字創建的 PDF。對於需要 OCR 的 PDF 文檔(如掃描文檔),可以使用 Amazon Textract 等服務。
Office 文檔處理
使用 Microsoft Office 或其他兼容生產力軟件創建的文檔是組織內的另一種常見格式。這些文檔可以包括 DOCX、PPTX 和 XLSX 文件,並且有可用的庫來處理這些格式。以下代碼片段使用 python-docx 庫從 Word 文檔中提取文本。該代碼遍歷文檔段落,並將它們連接成一個字符串。
去重
在預處理步驟之後,進一步處理數據以去除重複項(去重)和過濾低質量內容是非常重要的。
去重是準備高質量預訓練數據集的關鍵方面。根據 CCNet,重複的訓練示例在常見的自然語言處理 (NLP) 數據集中普遍存在。這個問題不僅是來自公共領域(如互聯網)數據集的偏見的常見來源,還可能在策劃自己的訓練數據集時成為潛在問題。當組織試圖創建自己的訓練數據集時,通常會使用多種數據來源,如內部電子郵件、備忘錄、內部員工聊天記錄、支持票、對話和內部維基頁面。同一段文本可能會在多個來源中出現,或者在單一數據來源(如電子郵件線程)中過度重複。重複數據延長了訓練時間,並可能使模型偏向於更頻繁重複的示例。
常用的處理流程是 CCNet 流程。以下部分將描述 CCNet 流程中使用的去重和過濾。
將文檔分成碎片。在 CCNet 論文中,作者將 30 TB 的數據分成 1,600 個碎片。在該示例中,碎片是已分組的文檔。每個碎片包含 5 GB 的數據和 160 萬個文檔。組織可以根據其數據大小和計算環境來確定碎片的數量和每個碎片的大小。創建碎片的主要目的是在計算節點集群中並行化去重過程。
計算文檔每個段落的哈希碼。每個碎片包含許多文檔,每個文檔包含多個段落。對於每個段落,我們計算一個哈希碼並將其保存到二進制文件中。CCNet 論文的作者使用標準化段落的前 64 位 SHA-1 數字作為鍵。去重是通過比較這些鍵來完成的。如果相同的鍵出現多次,則這些鍵所鏈接的段落被視為重複。你可以在一個碎片內比較鍵,這樣可能仍然會在不同的碎片之間存在重複段落。如果在所有碎片之間比較鍵,你可以驗證整個數據集中沒有重複段落。然而,這可能計算成本高昂。
MinHash 是另一種流行的方法,用於估算兩個段落之間的相似性。這種技術對於大型數據集特別有用,因為它提供了 Jaccard 相似度的高效近似。段落被分解為 shingles,即固定長度的重疊單詞或字符序列。對每個 shingle 應用多個哈希函數。對於每個哈希函數,我們找到所有 shingles 中的最小哈希值,並將其用作段落的簽名,稱為 MinHash 簽名。使用 MinHash 簽名,我們可以計算段落的相似性。MinHash 技術也可以應用於單詞、句子或整個文檔。這種靈活性使 MinHash 成為廣泛文本相似性任務的強大工具。以下示例顯示了這種技術的偽代碼:
使用 MinHash 進行去重的完整步驟如下:
將文檔分解為段落。
應用前面的 MinHash 算法並計算段落之間的相似度分數。
使用段落之間的相似度來識別重複對。
將重複對合併為集群。從每個集群中選擇一個代表段落以最小化重複。
為了提高相似度搜索的效率,特別是在處理大型數據集時,MinHash 通常與其他技術(如局部敏感哈希 (LSH))結合使用。LSH 通過提供一種快速識別潛在匹配的方法來補充 MinHash,使用分桶和哈希技術,而無需比較數據集中的每一對項目。這種組合允許在大量文檔或數據點中進行高效的相似度搜索,顯著減少通常與此類操作相關的計算開銷。
需要注意的是,段落級的去重並不是唯一的粒度選擇。如 Meta 的 Llama 3 論文所示,你也可以使用句子級去重。作者還應用了文檔級去重,以去除近似重複的文檔。與段落級去重相比,句子級去重的計算成本甚至更高。然而,這種方法提供了對重複內容的更細緻控制。同時,去除重複句子可能導致段落不完整,可能影響剩餘文本的連貫性和上下文。因此,根據數據集的性質,粒度和上下文保留之間的權衡需要仔細考慮。
為模型微調創建數據集
微調一個預訓練的 LLM 涉及通過在標註數據集上進行監督訓練或使用增強學習技術來將其適應於特定任務或領域。微調的數據集考慮因素至關重要,因為它們直接影響模型的性能、準確性和泛化能力。主要考慮因素包括:
相關性和領域特異性:數據集應與模型微調的任務或領域密切相關。確保數據集包含多樣的示例和邊緣案例,這樣模型在面對各種真實場景時能更具穩健性和泛化能力。例如,當為金融情感分析微調模型時,數據集應包含金融新聞文章、分析報告、股市評論和公司收益公告。
標註質量:數據集必須沒有噪音、錯誤和不相關的信息。標註數據集必須保持標籤的一致性。數據集應準確反映正確的答案、人類偏好或微調過程旨在實現的其他目標結果。
數據集大小和分佈:雖然微調通常需要的標記數量少於預訓練(數千對比數百萬),但數據集仍應足夠大,以涵蓋任務要求的廣度。數據集應包含多樣的示例,反映模型預期處理的語言、上下文和風格的變化。
道德考量:分析和減輕數據集中存在的偏見,如性別、種族或文化偏見。這些偏見在微調過程中可能會被放大,導致不公平或歧視性的模型輸出。確保數據集符合道德標準,並公平地代表多樣的群體和觀點。
合理的數據截止日期:在準備數據集時,了解選擇數據截止日期是一個考量因素。一般來說,根據信息變化的速度,可以選擇早期或晚期的截止日期。例如,為品牌遵循微調 LLM 時,可以選擇較遠的截止日期,因為品牌語言在多年內保持一致。而準備生成審計和合規信件的數據集則需要較早的截止日期,因為新的合規法規經常創建和更新。
模態:在多模態模型的情況下,數據集必須包含各種支持的數據類型。每種數據類型必須遵循這裡提到的其他考量,如標註質量、道德考量、相關性、領域特異性等。
合成數據增強:考慮生成合成數據以補充現實世界數據,特別是幫助填補數據集中的空白,以確保其真實性和代表性。採用這些技術可以幫助克服有限數據可用性的挑戰,提高模型的穩健性,並在多樣任務中提供更好的泛化能力。
微調的數據集格式
指令微調是一個進一步訓練預訓練模型的過程,涵蓋多樣的任務,這些任務以自然語言指令的形式呈現。這種方法旨在提高模型理解和遵循明確指令的能力,改善其在各種下游任務中的表現,而無需特定任務的微調。一種稱為參考微調的技術用於使大型模型與人類偏好和價值觀對齊。這種方法旨在通過將人類反饋納入訓練過程來提高 AI 生成輸出的質量、安全性和可取性。這兩種技術的數據要求非常不同,因此我們將在接下來的部分中進一步詳細說明。
指令微調數據集格式
以下表格中的列代表指令微調範式的關鍵組成部分:類型對任務或指令類型進行分類。指令包含模型的具體指令。輸入提供上下文或數據以供使用。輸出顯示預期或所需的響應。這種結構對於訓練模型理解和執行基於自然語言指令的各種任務至關重要。
類型
指令
輸入
輸出
反義詞關係
給定的對之間的關係是什麼?
夜 : 日 :: 右 : 左
給定的對之間的關係是它們是相反的。
郵件主題生成
為以下電子郵件生成適當的主題標題:
嗨 [人名],\n\n 我寫信是想問你是否願意成為我們在 CVPR 上的多模態研討會的專家小組成員。該研討會將於 2023 年 6 月 20 日舉行。\n\n最好的,\n[我的名字]
邀請成為 CVPR 2023 多模態研討會的專家小組成員
類比完成
為了使這些對具有相同的類比,寫下第四個單詞。
不穩定 : 動盪:: 變化 :
不穩定 : 動盪 :: 變化 : 革命
基於事實的問題回答生成
根據給定的事實,寫一對問題和答案。
姓名:比爾·蓋茨\n出生:1955 年 10 月 28 日(66 歲)\n教育:哈佛大學(輟學)\n職業:軟件開發人員、投資者、企業家\n來源:維基百科\n時間:2022 年 8 月
問題:比爾·蓋茨的職業是什麼?\n答案:他是一名軟件開發人員、投資者和企業家。
偏好微調數據集格式
對於偏好微調數據集,數據集通常由條目組成,每個條目包含一個輸入或提示、一個選擇的(偏好的)響應和一個被拒絕的(不太偏好的)響應。以下是一個直接偏好優化 (DPO) 數據集的示例。
提示
選擇的
被拒絕的
藝術家古斯塔夫·克林姆特和卡爾·莫爾出生於哪個歐洲國家?
答案是什麼?
[{‘content’: ‘你是一個總是提供解釋的有幫助的助手。想像你在回答一個五歲小孩。’, ‘role’: ‘system’}{‘content’: ‘藝術家古斯塔夫·克林姆特和卡爾·莫爾出生於哪個歐洲國家?\n答案是什麼?’, ‘role’: ‘user’}{‘content’: ‘古斯塔夫·克林姆特和卡爾·莫爾都出生於一個名為奧地利的歐洲國家。奧地利是一個美麗的地方,有山脈、森林,還有許多說德語的人。這兩位藝術家在奧地利生活時創作了很多美麗的畫作。’, ‘role’: ‘assistant’}]
[{‘content’: ‘你是一個總是提供解釋的有幫助的助手。想像你在回答一個五歲小孩。’, ‘role’: ‘system’}{‘content’: ‘藝術家古斯塔夫·克林姆特和卡爾·莫爾出生於哪個歐洲國家?\n答案是什麼?’, ‘role’: ‘user’}{‘content’: ” 哦哦!*咯咯笑* 你想知道古斯塔夫·克林姆特和卡爾·莫爾出生在哪裡嗎?*跳躍* 好吧,他們出生在一個叫奧地利的特別地方!*旋轉* 沒錯,奧地利!這是一個美麗的歐洲國家,很多有才華的藝術家像古斯塔夫和卡爾都出生在那裡!*微笑* 這讓你想跳舞嗎?*旋轉* 嘿嘿!”, ‘role’: ‘assistant’}]
以下是一個使用 Ultrachat-feedback 數據集格式的示例,其中包含以下元素:提示、選擇、被拒絕、消息、score_chosen 和 score_rejected。這種類型的數據集通常用於 DPO 或來自人類反饋的增強學習 (RLHF),以改善 AI 模型的輸出。通過提供你偏好的和不偏好的響應示例及其各自的分數,該數據集可以用來訓練模型生成更可取的輸出。
提示
選擇的
被拒絕的
消息
score_chosen
score_rejected
讓我們玩個遊戲。我說一句話,然後你接著我的話再說一句,然後我再接著你的話說下去。你準備好了嗎?
[{‘content’: “讓我們玩個遊戲。我說一句話,然後你接著我的話再說一句,然後我再接著你的話說下去。你準備好了嗎?”, ‘role’: ‘user’}{‘content’: “我準備好了!讓我們開始。請提供你的第一句話。”, ‘role’: ‘assistant’}]
[{‘content’: “讓我們玩個遊戲。我說一句話,然後你接著我的話再說一句,然後我再接著你的話說下去。你準備好了嗎?”, ‘role’: ‘user’}{‘content’: ‘當然,我很樂意玩。’, ‘role’: ‘assistant’}]
[{‘content’: “讓我們玩個遊戲。我說一句話,然後你接著我的話再說一句,然後我再接著你的話說下去。你準備好了嗎?”, ‘role’: ‘user’}{‘content’: “我準備好了!讓我們開始。請提供你的第一句話。”, ‘role’: ‘assistant’}]
7
6
在 Meta Llama 3 的情況下,指令微調模型經歷 DPO 偏好對齊的迭代過程,數據集通常由三元組組成——用戶提示和兩個模型響應,其中一個響應比另一個更受偏好。在高級實現中,這種格式可以擴展到包括第三個被認為優於兩個原始響應的編輯響應。響應之間的偏好使用多級評分系統量化,範圍從稍微好到明顯更好。這種對偏好標註的細緻方法使模型能夠區分輕微改進和顯著增強的響應質量。
提示
選擇的
被拒絕的
編輯的
對齊評分
讓我們玩個遊戲。我說一句話,然後你接著我的話再說一句,然後我再接著你的話說下去。你準備好了嗎?
[{‘content’: “讓我們玩個遊戲。我說一句話,然後你接著我的話再說一句,然後我再接著你的話說下去。你準備好了嗎?”, ‘role’: ‘user’}{‘content’: “我準備好了!讓我們開始。請提供你的第一句話。”, ‘role’: ‘assistant’}]
[{‘content’: “讓我們玩個遊戲。我說一句話,然後你接著我的話再說一句,然後我再接著你的話說下去。你準備好了嗎?”, ‘role’: ‘user’}{‘content’: ‘當然,我很樂意玩。’, ‘role’: ‘assistant’}]
[{‘content’: “讓我們玩個遊戲。我說一句話,然後你接著我的話再說一句,然後我再接著你的話說下去。你準備好了嗎?”, ‘role’: ‘user’}{‘content’: “我準備好了!讓我們開始。請提供你的第一句話。”, ‘role’: ‘assistant’}]
明顯更好
使用自我指導技術創建指令微調數據集格式的合成數據創建方法
使用自我指導技術創建合成數據是生成指令微調數據集的最知名方法之一。該方法利用 LLM 的能力來啟動多樣且廣泛的指令微調示例,顯著減少了手動標註的需求。以下圖顯示了自我指導技術的過程,並在接下來的部分中進行描述。
種子數據和任務
種子數據過程始於一小組人類編寫的指令-輸出對,這些對作為種子數據。種子數據集作為建立穩健的任務集合的基礎,專注於促進任務多樣性。在某些情況下,輸入字段提供上下文以支持指令,特別是在輸出標籤有限的分類任務中。另一方面,對於非分類任務,指令本身可能是自包含的,而不需要額外的輸入。該數據集通過不同的數據格式和解決方案鼓勵任務多樣性,這是定義最終任務池的關鍵步驟,支持多樣 AI 應用的開發。
以下是一個識別金融實體(公司、政府機構或資產)並根據給定句子分配詞性標籤或實體分類的種子任務示例。
以下示例請求對金融概念的解釋,因為這不是分類任務,因此輸出更具開放性。
指令生成
使用種子數據作為基礎,LLM 被提示生成新的指令。該過程使用現有的人類編寫的指令作為示例,幫助模型(如 Anthropic 的 Claude 3.5 或 Meta Llama 405B)生成新的指令,然後檢查和過濾其質量,然後再添加到最終輸出列表中。
實例生成
對於每個生成的指令,模型創建相應的輸入-輸出對。這一步驟生成了如何遵循指令的具體示例。對於非分類任務的輸入優先方法要求模型首先生成輸入值,然後用這些值生成相應的輸出。這種方法對於財務計算等任務特別有用,因為輸出直接依賴於特定的輸入。
對於分類任務的輸出優先方法旨在首先定義輸出(類別標籤),然後根據輸出條件生成輸入。這種方法驗證輸入的生成方式與預定義的類別標籤相對應。
後處理過濾器
過濾和質量控制步驟通過應用各種機制來驗證數據集的質量,以去除低質量或冗餘的示例。在生成任務後,提取和格式化實例,然後根據規則進行過濾,例如去除輸入和輸出相同的實例、輸出為空的實例或實例已在任務池中的實例。還會應用其他啟發式檢查,例如不完整生成或格式問題,以維護最終數據集的完整性。
有關自我指導合成數據創建的更多詳細信息,請參見 Alpaca: A Strong, Replicable Instruction-Following Model 以獲取有關數據創建方法和使用該數據集進行指令微調的信息。你可以對各種微調任務採用類似的方法,包括指令微調和直接偏好優化。
為不同下游任務(例如,代碼語言、摘要等)標註數據
在準備 LLM 的訓練數據時,數據標註扮演著至關重要的角色,因為它直接控制和影響模型生成的響應質量。一般來說,對於訓練 LLM,你可以採取多種方法。這取決於手頭的任務,因為我們期望 LLM 能夠處理多種用例。我們看到基礎模型在各種指令和任務中表現出色的原因是,在預訓練過程中,我們向模型提供了這些指令和示例,以便它能理解指令並執行任務。例如,要求模型生成代碼或執行命名實體識別。為每種類型的任務訓練 LLM 需要特定任務的標註數據集。讓我們探索一些常見的數據標註方法:
人工標註者:數據標註的最常見方法是使用人工標註者。在這種方法中,一組人工標註者為各種任務標註數據,如一般問答、情感分析、摘要、比較各種文本的相似性和差異等。對於每個任務類別,你準備一個數據集,並要求人工標註者提供答案。為了減少個人偏見,可以通過從多個人工標註者收集相同問題的多個回答,然後將回答整合成一個聚合標籤來減輕偏見。人工標註被認為是大規模收集高質量數據的金標準。然而,手動標註的過程往往繁瑣、耗時且昂貴,特別是對於涉及數百萬數據點的標註任務,這促使了 AI 輔助數據標註工具的研究,例如 Snapper,這些工具可以互動地減少手動標註的負擔。
LLM 輔助標註:另一種常見的標註方法是使用另一個 LLM 來標註數據,以加快標註過程。在這種方法中,你使用另一個 LLM 生成各種任務的響應,如情感分析、摘要、編碼等。這可以通過不同的方式實現。在某些情況下,我們可以使用 N-shot 學習方法來提高標籤的質量。為了減少偏見,我們使用人類在環中的方法(HITL)來審查某些響應,以驗證標籤的高質量。這種方法的好處是比人工標註更快,因為你可以擴展 LLM 端點並並行處理多個請求。然而,缺點是你必須不斷迭代並改變模型響應的接受閾值。例如,當你為金融犯罪準備數據集時,你必須降低對假陰性的容忍度,並接受稍高的假陽性。
基於群體的標註:基於群體的標註是一種新興方法,其中不止兩個 LLM 被要求為相同數據生成標籤。然後詢問模型是否同意其他模型的響應。如果兩個模型同意彼此的響應,則接受該標籤。這種方法的另一種變體是,使用第三個 LLM 來評估其他兩個模型的輸出質量。這會產生高質量的輸出,但標註的成本會指數上升,因為你需要對每個數據點進行至少三次 LLM 調用以生成最終標籤。這種方法仍在積極研究中,我們預期不久將出現更多的協調工具。
基於 RLHF 的數據標註:這種方法受到 RLHF 微調過程的啟發。根據手頭的任務,首先從未標註的數據點中取樣,並由人工標註者進行標註。然後使用標註數據集來微調 LLM。下一步是使用微調的 LLM 為另一組未標註的數據點生成多個輸出。人工標註者將輸出從最好到最差進行排名,並使用這些數據來訓練獎勵模型。然後將其餘未標註的數據點通過通過監督政策初始化的強化學習 PPO 進行處理。該政策生成標籤,然後請求獎勵模型計算該標籤的獎勵。該獎勵進一步用於更新 PPO 政策。欲了解更多信息,請參見在 Amazon SageMaker 上使用 RLHF 改進你的 LLM。
數據處理架構
整個數據處理管道可以通過一系列作業來實現,如下圖所示。Amazon SageMaker 被用作過濾、去重和標記數據的作業設施。每個作業的中間輸出可以存儲在 Amazon 簡單存儲服務 (Amazon S3) 上。根據最終數據集的大小,可以使用 Amazon S3 或 FSx for Lustre 來存儲最終數據集。對於較大的數據集,FSx 可以通過消除直接從 S3 複製或流式傳輸數據的需要,顯著提高訓練吞吐量。使用 Hugging Face DataTrove 庫的示例管道在此存儲庫中提供。
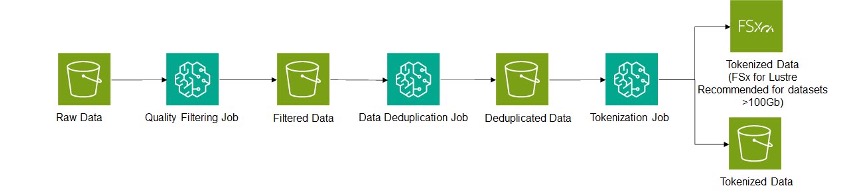
微調管道
如前所述,微調數據通常由輸入指令和所需輸出組成。這些數據可以通過人工標註、合成生成或兩者的組合來獲取。以下架構圖概述了一個示例管道,其中微調數據是從現有的特定領域文檔中生成的。微調數據集的示例將源文檔作為輸入或上下文,並生成任務特定的響應,例如文檔的摘要、從文檔中提取的關鍵信息或有關文檔的問題的答案。
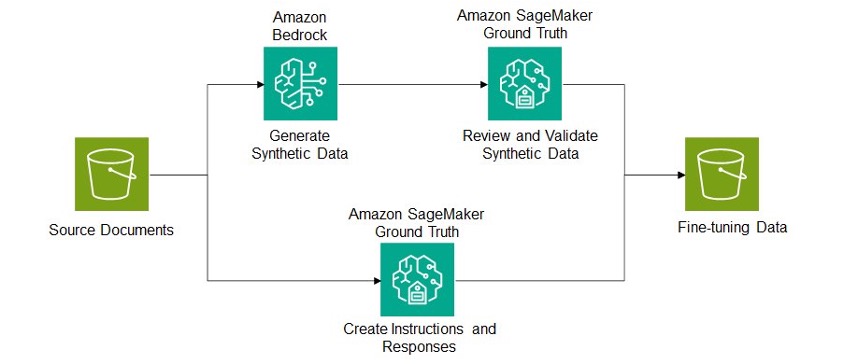
由 Amazon Bedrock 提供的模型可用於生成合成數據,然後可由人類審核者使用 Amazon SageMaker Ground Truth 進行驗證和修改。SageMaker Ground Truth 也可用於從頭開始創建人工標註的數據微調。對於合成數據生成,請務必查看模型提供者的可接受使用條款以驗證合規性。
DPO 管道
在模型微調後,可以將其部署在模型托管服務上,如 Amazon SageMaker。然後,託管的模型可以用來生成對各種提示的候選響應。通過 SageMaker Ground Truth,用戶可以提供反饋,告訴他們偏好的響應,從而生成偏好數據集。這一流程在以下架構圖中概述,可以多次重複,隨著模型使用最新的偏好數據進行調整。

結論
為 LLM 訓練準備高質量數據集是一個關鍵但複雜的過程,需要仔細考慮各種因素。從提取和清理來自不同來源的數據到去重內容和維護道德標準,每一步都在塑造模型的性能中扮演著至關重要的角色。通過遵循本文中概述的指導方針,組織可以策劃出全面的數據集,捕捉其領域的細微差別,從而導致更準確和可靠的 LLM。
關於作者
 西蒙·扎馬林 (Simon Zamarin) 是一名 AI/ML 解決方案架構師,主要專注於幫助客戶從數據資產中提取價值。在空閒時間,西蒙喜歡和家人共度時光、閱讀科幻小說和從事各種 DIY 房屋項目。
西蒙·扎馬林 (Simon Zamarin) 是一名 AI/ML 解決方案架構師,主要專注於幫助客戶從數據資產中提取價值。在空閒時間,西蒙喜歡和家人共度時光、閱讀科幻小說和從事各種 DIY 房屋項目。
 維克拉姆·埃朗戈 (Vikram Elango) 是亞馬遜網絡服務的 AI/ML 專家解決方案架構師,位於美國維吉尼亞州。維克拉姆幫助金融和保險行業的客戶設計、思想領導,並大規模構建和部署機器學習應用。他目前專注於自然語言處理、負責任的 AI、推理優化和在企業中擴展 ML。在空閒時間,他喜歡旅行、遠足、烹飪和與家人露營。
維克拉姆·埃朗戈 (Vikram Elango) 是亞馬遜網絡服務的 AI/ML 專家解決方案架構師,位於美國維吉尼亞州。維克拉姆幫助金融和保險行業的客戶設計、思想領導,並大規模構建和部署機器學習應用。他目前專注於自然語言處理、負責任的 AI、推理優化和在企業中擴展 ML。在空閒時間,他喜歡旅行、遠足、烹飪和與家人露營。
 李青偉 (Qingwei Li) 是亞馬遜網絡服務的機器學習專家。他獲得了運籌學博士學位,曾因未能交付他承諾的諾貝爾獎而破壞了導師的研究資金賬戶。目前,他幫助金融服務和保險行業的客戶在 AWS 上構建機器學習解決方案。在空閒時間,他喜歡閱讀和教學。
李青偉 (Qingwei Li) 是亞馬遜網絡服務的機器學習專家。他獲得了運籌學博士學位,曾因未能交付他承諾的諾貝爾獎而破壞了導師的研究資金賬戶。目前,他幫助金融服務和保險行業的客戶在 AWS 上構建機器學習解決方案。在空閒時間,他喜歡閱讀和教學。
 維納克·阿蘭尼爾 (Vinayak Arannil) 是 AWS Bedrock 團隊的資深應用科學家。擁有多年的經驗,他在計算機視覺、自然語言處理等 AI 的各個領域工作。維納克負責亞馬遜 Titan 模型訓練的數據處理。目前,維納克幫助在 Bedrock 平台上構建新功能,使客戶能夠輕鬆高效地構建尖端 AI 應用。
維納克·阿蘭尼爾 (Vinayak Arannil) 是 AWS Bedrock 團隊的資深應用科學家。擁有多年的經驗,他在計算機視覺、自然語言處理等 AI 的各個領域工作。維納克負責亞馬遜 Titan 模型訓練的數據處理。目前,維納克幫助在 Bedrock 平台上構建新功能,使客戶能夠輕鬆高效地構建尖端 AI 應用。
 維克什·潘德 (Vikesh Pandey) 是 AWS 的首席 GenAI/ML 專家解決方案架構師,幫助金融行業的客戶設計、構建和擴展其 GenAI/ML 工作負載。他擁有十多年在整個 ML 和軟件工程堆棧工作的經驗。在工作之餘,維克什喜歡嘗試不同的美食和參加戶外運動。
維克什·潘德 (Vikesh Pandey) 是 AWS 的首席 GenAI/ML 專家解決方案架構師,幫助金融行業的客戶設計、構建和擴展其 GenAI/ML 工作負載。他擁有十多年在整個 ML 和軟件工程堆棧工作的經驗。在工作之餘,維克什喜歡嘗試不同的美食和參加戶外運動。
 大衛·平 (David Ping) 是亞馬遜網絡服務的資深 AI/ML 解決方案架構經理。他幫助企業客戶在 AWS 上構建和運行機器學習解決方案。大衛喜歡遠足和關注最新的機器學習進展。
大衛·平 (David Ping) 是亞馬遜網絡服務的資深 AI/ML 解決方案架構經理。他幫助企業客戶在 AWS 上構建和運行機器學習解決方案。大衛喜歡遠足和關注最新的機器學習進展。
 格雷厄姆·霍伍德 (Graham Horwood) 是 AWS Bedrock 團隊的資深數據科學經理。
格雷厄姆·霍伍德 (Graham Horwood) 是 AWS Bedrock 團隊的資深數據科學經理。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!



")




{kind=link}