


機器人操作領域因為出現了視覺-語言-行動 (VLA) 模型而發生了顯著變化。這些先進的計算框架在執行複雜的操作任務方面展現了很大的潛力,並且可以在不同的環境中運作。儘管它們的能力令人印象深刻,VLA 模型在面對新的情境時仍然遇到不少挑戰,包括不同的物體、環境和語意情境。
目前的訓練方法,特別是監督式微調 (SFT),是這些模型的基本限制。這種方法主要依賴行為模仿,透過成功的行動回放來訓練模型。這樣的方式限制了模型對任務目標和潛在失敗機制的全面理解。因此,這些模型常常難以適應細微的變化和意外情況,顯示出需要更複雜的訓練策略。
過去的機器人學習研究主要使用分層規劃策略,例如 Code as Policies 和 EmbodiedGPT,這些模型利用大型語言模型和視覺-語言模型來生成高層次的行動計劃。這些方法通常使用大型語言模型來創建行動序列,然後由低層控制器解決局部軌跡挑戰。然而,這些方法在技能適應性和日常機器人操作任務的泛化能力上顯示出顯著的限制。
VLA 模型在行動規劃上採取了兩種主要方法:行動空間離散化和擴散模型。離散化方法,例如 OpenVLA,涉及將行動空間均勻地切割成離散的標記,同時保持自回歸語言解碼目標。擴散模型則是通過多次去噪步驟來生成行動序列,而不是產生單一的逐步行動。儘管這些結構上有所不同,這些模型仍然依賴於使用成功的行動回放進行監督式訓練,這根本限制了它們在新操作情境中的泛化能力。
來自北卡羅來納大學教堂山分校 (UNC Chapel-Hill)、華盛頓大學 (University of Washington) 和芝加哥大學 (University of Chicago) 的研究人員提出了 GRAPE (通過偏好對齊來泛化機器人政策),這是一種創新的方法,旨在解決 VLA 模型訓練中的基本限制。GRAPE 提供了一種強大的軌跡偏好優化 (TPO) 技術,通過隱式建模來自成功和不成功試驗序列的獎勵,來戰略性地對齊機器人政策。這種方法使得在多樣的操作任務中增強了泛化能力,超越了傳統的訓練限制。
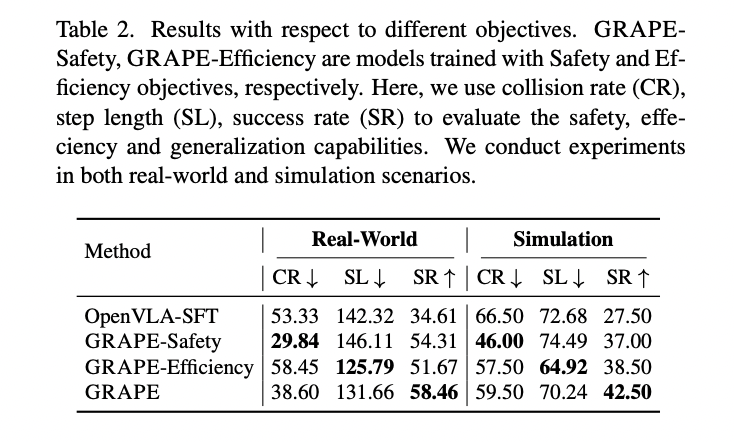
GRAPE 方法的核心是一種複雜的分解策略,將複雜的操作任務分解為多個獨立的階段。這種方法提供了前所未有的靈活性,利用大型視覺模型為每個階段提出關鍵點,並將其與空間-時間約束相關聯。這些可自定義的約束允許與不同的操作目標對齊,包括任務完成、機器人互動安全性和運營成本效率,這標誌著機器人政策發展的一個重大進步。
研究團隊在模擬和現實世界的機器人環境中對 GRAPE 進行了全面評估,以驗證其性能和泛化能力。在 Simpler-Env 和 LIBERO 等模擬環境中,GRAPE 展現了卓越的能力,顯著超越了現有的模型 Octo-SFT 和 OpenVLA-SFT。具體來說,在 Simpler-Env 中,GRAPE 的表現比之前的模型平均提高了 24.48% 和 13.57%,涵蓋了主題、物理和語意等多個泛化方面。
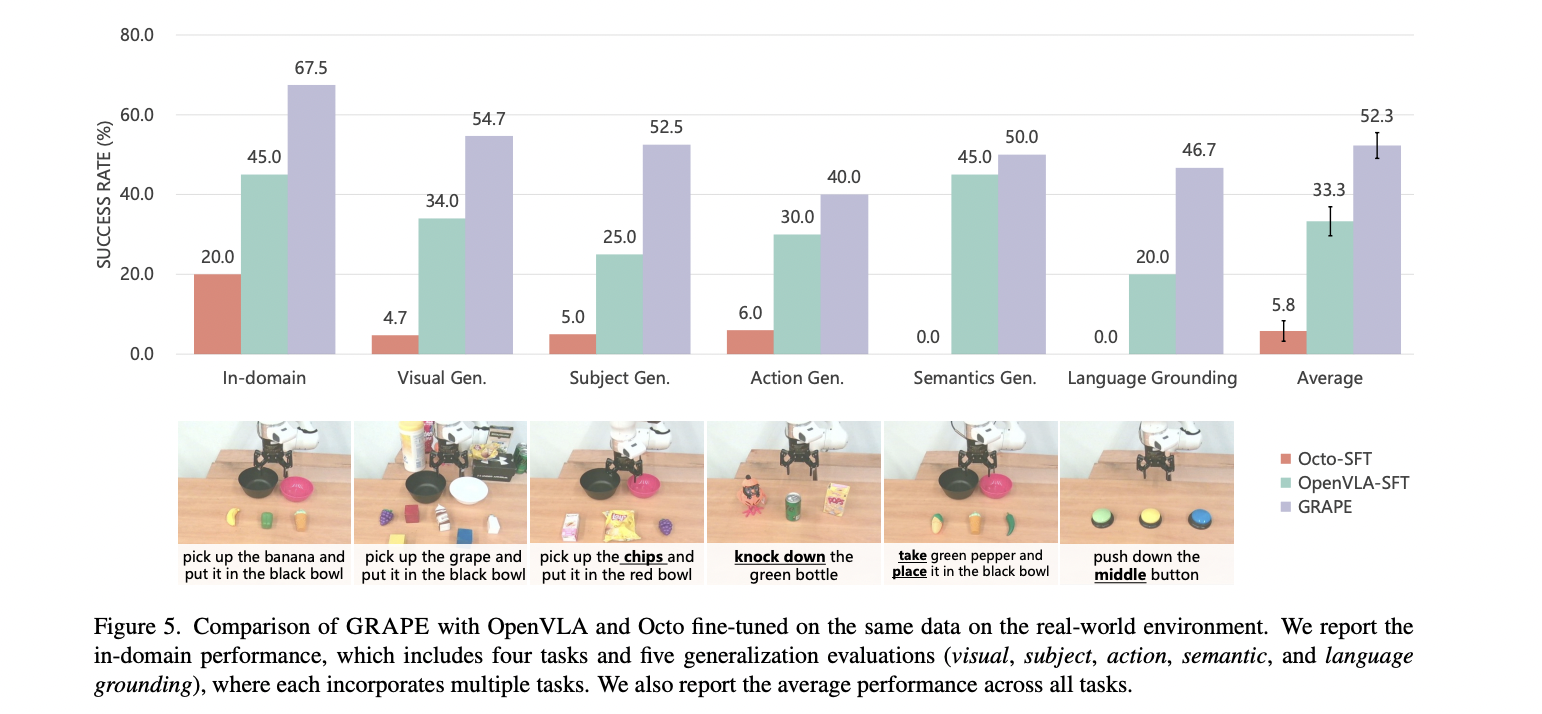
現實世界的實驗結果進一步證實了 GRAPE 的有效性,該模型在多樣的任務情境中展現了卓越的適應能力。在特定領域的任務中,GRAPE 的成功率達到了 67.5%,比 OpenVLA-SFT 提高了 22.5%,並且大幅超越了 Octo-SFT。特別令人印象深刻的是 GRAPE 在挑戰性的泛化任務中的表現,在視覺、行動和語言基礎情境中保持了優越的結果,總平均成功率達到了 52.3%——比現有方法提高了 19%。
這項研究介紹了 GRAPE 作為解決 VLA 模型面臨的關鍵挑戰的變革性解決方案,特別是在操作任務中的有限泛化能力和適應能力。通過實施一種新穎的軌跡級政策對齊方法,GRAPE 展示了從成功和不成功的試驗序列中學習的卓越能力。這種方法在將機器人政策與多樣的目標對齊方面提供了前所未有的靈活性,包括安全性、效率和任務完成,並通過創新的空間時間約束機制實現。實驗結果驗證了 GRAPE 的顯著進步,展示了在特定領域和未見任務環境中的性能大幅提升。
查看論文和 GitHub 頁面。這項研究的所有功勞都歸功於這個項目的研究人員。此外,別忘了在 Twitter 上關注我們,加入我們的 Telegram 頻道和 LinkedIn 群組。如果你喜歡我們的工作,你一定會喜歡我們的電子報。別忘了加入我們的 60k+ ML SubReddit。
🚨 [必參加的網路研討會]:‘將概念驗證轉化為生產就緒的 AI 應用和代理’(推廣)
新聞來源
本文由 AI 台灣 使用 AI 編撰,內容僅供參考,請自行進行事實查核。加入 AI TAIWAN Google News,隨時掌握最新 AI 資訊!



")




{kind=link}