


生成代碼並獲得執行反饋是很困難的,因為錯誤通常需要多次修正,而以有結構的方式修正這些錯誤並不簡單。訓練模型從執行反饋中學習是必要的,但這些方法面臨挑戰。有些方法試圖在一步內修正錯誤,但當需要多次改進時卻失敗了。其他方法使用複雜的學習技術來優化長期改進,但這些方法在學習信號較弱的情況下,訓練變得緩慢且效率低下。缺乏有效處理迭代修正的方法導致學習不穩定,表現不佳。
目前,基於提示的系統嘗試使用自我調試、測試生成和反思來解決多步任務,但改進幅度有限。有些方法訓練獎勵模型,例如 CodeRL 用於修正錯誤,ARCHER 用於結構化決策,而其他方法則使用蒙地卡羅樹搜索 (Monte Carlo Tree Search, MCTS),但需要過多的計算。基於驗證器的方法,如「逐步驗證」和 AlphaCode,幫助找出錯誤或創建測試案例,但有些模型僅依賴語法檢查,這對於正確訓練來說是不夠的。分數限制了訓練步驟,而 RISE 使用複雜的修正,使學習效率低下。像 FireAct、LEAP 這樣的微調代理和基於反饋的模型,如 RL4VLM 和 GLAM,試圖提高性能。然而,當前技術要麼無法在多步驟中正確地細化代碼,要麼過於不穩定且效率低下。
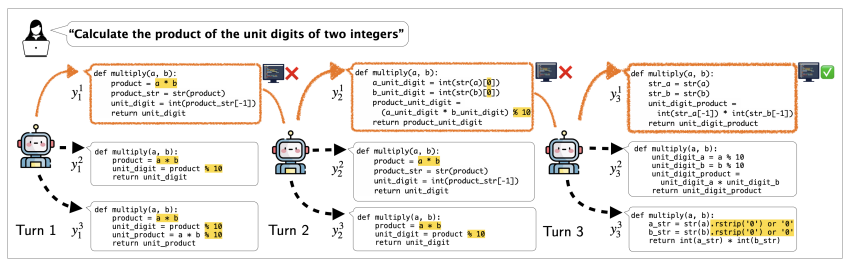
為了解決這些問題,研究人員提出了 µCODE,一種多回合代碼生成方法,通過執行反饋來改進。現有方法在執行錯誤和強化學習的複雜性方面面臨挑戰,但 µCODE 通過遵循專家迭代框架和本地搜索專家來克服這些挑戰。一個驗證器評估代碼質量,而生成器則從最佳解決方案中學習,通過多次迭代來細化其輸出。在推理過程中,最佳 N 搜索策略幫助根據執行結果生成和改進代碼,確保更好的性能。
該框架首先通過監督學習訓練驗證器,以評分代碼片段,使評估更可靠。二元交叉熵預測正確性,而布拉德利-泰瑞 (Bradley-Terry) 排名解決方案以便更好地選擇。然後,生成器通過用專家選擇的解決方案重新標記過去的輸出來進行迭代學習,從而提高準確性。在推理過程中產生多個解決方案,驗證器選擇最佳方案,並不斷細化輸出,直到所有測試通過。通過將代碼生成視為模仿學習問題,µCODE 消除了複雜的探索,實現了高效的優化。
研究人員通過將 µCODE 與最先進的方法進行比較,分析學習驗證器在訓練和推理過程中的影響,並評估不同的損失函數來訓練驗證器,來評估 µCODE 的有效性。生成器使用 Llama 模型進行初始化,並在 MBPP 和 HumanEval 數據集上進行實驗。訓練是在 MBPP 的訓練集上進行的,並在其測試集和 HumanEval 上進行評估。比較包括單回合和多回合基準,如 STaR 和 Multi–STaR,其中微調基於正確生成的解決方案。性能使用最佳 N (BoN) 準確性進行測量,驗證器在每個回合對候選解決方案進行排名。

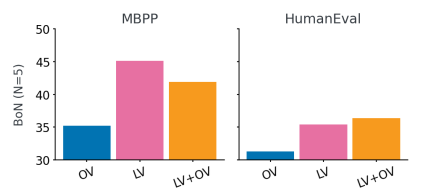
結果顯示,多回合方法的表現優於單回合方法,突顯了執行反饋的好處。µCODE 的表現超過 Multi-STaR,在 HumanEval 上實現了 1.9% 的改進,使用的是 1B 模型。最佳搜索進一步提升了性能,µCODE 在貪婪解碼上顯示出 12.8% 的增益。學習驗證器 (LV) 改善了訓練結果,超過了僅使用的預測驗證器 (OV)。進一步分析顯示,學習驗證器在推理過程中幫助選擇更好的解決方案,特別是在缺乏公共測試的情況下。推理時間的擴展顯示,在一定數量的候選解決方案之後,性能增益逐漸減少。將公共測試結果與學習驗證器分數結合的分層驗證策略 (PT+LV) 提供了最高的性能,顯示了驗證器在消除錯誤解決方案和進行迭代預測方面的有效性。
總結來說,提出的 µCODE 框架提供了一種可擴展的多回合代碼生成方法,使用單步獎勵和學習驗證器進行迭代改進。結果顯示,µCODE 的表現優於基於預測的方式,生成了更精確的代碼。儘管受到模型大小、數據集大小和 Python 專注的限制,但它可以成為未來工作的堅實基準。擴大訓練數據、擴展到更大的模型以及應用於多種編程語言可以進一步提高其有效性。
查看論文和 GitHub 頁面。所有對這項研究的讚譽都歸功於這個項目的研究人員。此外,隨時在 Twitter 上關注我們,並且不要忘記加入我們的 80,000 多名機器學習 SubReddit。
🚨 介紹 Parlant:一個以 LLM 為首的對話式 AI 框架,旨在為開發人員提供對其 AI 客戶服務代理的控制和精確度,利用行為指導和運行時監督。🔧 🎛️ 它使用易於使用的命令行介面 (CLI) 📟 和 Python 和 TypeScript 的原生客戶端 SDK 📦 操作。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}