
和REWARDAGENT:一種結合人類偏好和可驗證正確性的混合AI方法,用於可靠的LLM訓練")

大型語言模型(LLMs)依賴強化學習技術來提升回應生成的能力。其中一個關鍵的發展方面是獎勵模型,它幫助訓練模型更好地符合人類的期望。獎勵模型根據人類的偏好來評估回應,但現有的方法往往受到主觀性和事實正確性的限制。這可能導致模型的表現不佳,因為模型可能會優先考慮流暢性而非準確性。透過可驗證的正確性信號來改善獎勵模型,可以幫助提升LLMs在現實應用中的可靠性。
當前獎勵模型系統的一個主要挑戰是它們過度依賴人類的偏好,而這些偏好本質上是主觀的,容易受到偏見的影響。這些模型偏好冗長的回應或具有吸引力的風格元素,而不是客觀正確的答案。傳統獎勵模型中缺乏系統性的驗證機制,限制了它們確保正確性的能力,使其容易受到錯誤資訊的影響。此外,指令遵循的限制經常被忽視,導致輸出未能滿足精確的用戶需求。解決這些問題對於提高AI生成回應的穩健性和可靠性至關重要。
傳統的獎勵模型專注於基於偏好的強化學習,例如帶有人類反饋的強化學習(RLHF)。雖然RLHF增強了模型的對齊性,但並未納入結構化的正確性驗證。一些現有模型試圖根據一致性和流暢性來評估回應,但缺乏驗證事實準確性或遵循指令的強大機制。雖然已經探索了基於規則的驗證等替代方法,但由於計算挑戰,這些方法並未廣泛整合。這些限制突顯了需要一個獎勵模型系統,將人類偏好與可驗證的正確性信號結合,以確保高質量的語言模型輸出。
來自清華大學的研究人員提出了代理獎勵模型(ARM),這是一種新穎的獎勵系統,將傳統的基於偏好的獎勵模型與可驗證的正確性信號整合。該方法引入了一個名為REWARDAGENT的獎勵代理,通過將人類偏好信號與正確性驗證結合,增強了獎勵的可靠性。這個系統確保LLMs生成的回應既符合用戶的偏好,又事實上是準確的。通過整合事實驗證和指令遵循評估,ARM提供了一個更穩健的獎勵模型框架,減少主觀偏見,改善模型對齊性。
REWARDAGENT系統由三個核心模組組成。路由器分析用戶指令,以確定根據任務需求應啟用哪些驗證代理。驗證代理在兩個關鍵方面評估回應:事實正確性和遵循硬性約束。事實代理使用參數知識和外部來源交叉檢查信息,確保回應是良好形成且事實上是正確的。指令遵循代理通過解析特定指令並根據預定規則驗證回應,確保遵循長度、格式和內容的約束。最後一個模組,評判者,整合正確性信號和偏好分數,以計算整體獎勵分數,平衡主觀的人類反饋與客觀的驗證。這種架構使系統能夠根據不同任務動態選擇最合適的評估標準,確保靈活性和準確性。
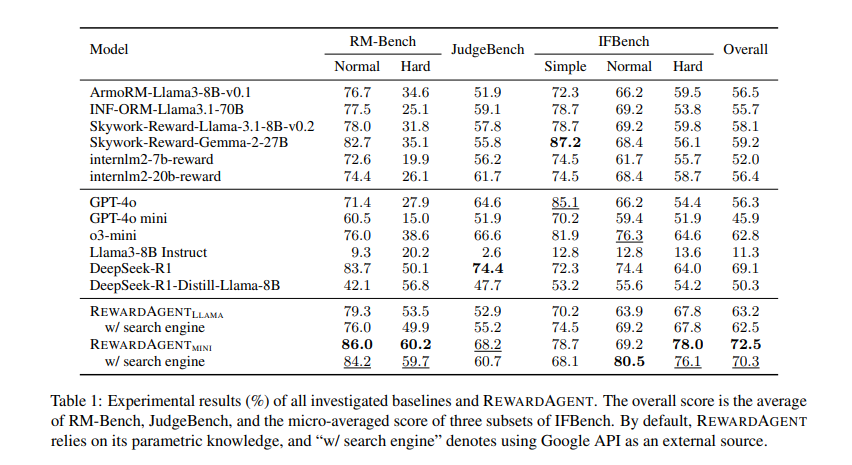
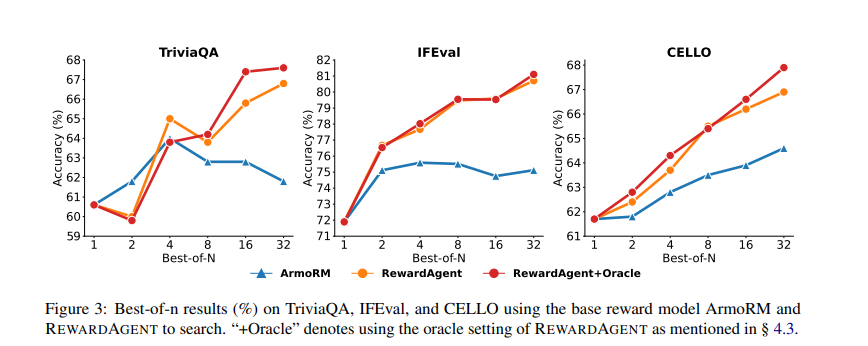
廣泛的實驗顯示,REWARDAGENT顯著優於傳統的獎勵模型。它在RM-Bench、JudgeBench和IFBench等基準上進行評估,在選擇事實和遵循約束的回應方面表現出色。在RM-Bench中,該模型在使用搜索引擎時達到了76.0%的準確率,而不使用時則為79.3%,而傳統獎勵模型的準確率僅為71.4%。該系統進一步應用於現實世界的最佳n搜索任務,改善了多個數據集(包括TriviaQA、IFEval和CELLO)的回應選擇準確性。在TriviaQA中,REWARDAGENT的準確率達到68%,超過了基礎獎勵模型ArmoRM。此外,該模型被用來構建直接偏好優化(DPO)訓練的偏好對,使用REWARDAGENT生成的偏好對訓練的LLMs表現優於使用傳統標註訓練的模型。具體而言,使用這種方法訓練的模型在基於事實的問答和遵循指令的任務中顯示出改進,證明了其在優化LLM對齊方面的有效性。
這項研究解決了獎勵模型中的一個關鍵限制,通過將正確性驗證與人類偏好評分整合在一起。REWARDAGENT增強了獎勵模型的可靠性,使LLM的回應更加準確且遵循指令。這種方法為進一步研究納入其他可驗證的正確性信號鋪平了道路,最終有助於開發更值得信賴和更具能力的AI系統。未來的工作可以擴展驗證代理的範圍,以涵蓋更複雜的正確性維度,確保獎勵模型隨著AI驅動應用需求的增加而不斷發展。
查看論文和GitHub頁面。這項研究的所有功勞都歸於這個項目的研究人員。此外,隨時在Twitter上關注我們,並別忘了加入我們的80k+ ML SubReddit。
🚨 推薦閱讀 – LG AI研究發布NEXUS:一個先進的系統,整合代理AI系統和數據合規標準,以解決AI數據集中的法律問題。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!






?")

{kind=link}