


大型強化學習(RL)訓練語言模型以解決推理任務已成為掌握複雜問題解決技能的一種有前景的技術。目前,像是 OpenAI 的 o1 和 DeepSeek 的 R1-Zero 等方法,已展示出顯著的訓練時間擴展現象。這兩個模型的基準表現和回應長度隨著訓練計算的增加而穩定上升,沒有任何飽和的跡象。受到這些進展的啟發,本文的研究人員探索了這種新的擴展現象,直接在基礎模型上進行大型 RL 訓練,並將這種方法稱為 Reasoner-Zero 訓練。
來自 StepFun 和清華大學的研究人員提出了 Open-Reasoner-Zero(ORZ),這是一個開源的大型推理導向 RL 訓練實現,專為語言模型設計。這代表著在讓更廣泛的研究社群能夠接觸到先進的 RL 訓練技術方面的一個重大進展。ORZ 在可驗證的獎勵下增強了多樣的推理技能,包括算術、邏輯、編程和常識推理任務。它通過全面的訓練策略解決了訓練穩定性、回應長度優化和基準表現提升等關鍵挑戰。與之前提供有限實施細節的方法不同,ORZ 提供了其方法論和最佳實踐的詳細見解。
ORZ 框架使用 Qwen2.5-{7B, 32B} 作為基礎模型,並實施直接的大型 RL 訓練,而不需要初步的微調步驟。該系統利用了標準 PPO 算法的擴展版本,專門針對推理導向任務進行優化。訓練數據集由精心策劃的問題-答案對組成,重點關注 STEM、數學和多樣的推理任務。架構包含一個專門的提示模板,旨在增強推理計算能力。實施基於 OpenRLHF,具有顯著的改進,包括靈活的訓練器、GPU 協同生成和先進的卸載-加載支持機制,以實現高效的大型訓練。
訓練結果顯示,Open-Reasoner-Zero 在多個指標上對 7B 和 32B 變體的表現都有顯著提升。訓練曲線顯示獎勵指標和回應長度的穩定增強,並且出現了顯著的「階段時刻」現象,表明推理能力的突然提升。在回應長度擴展與 DeepSeek-R1-Zero 的比較中,Open-Reasoner-Zero-32B 模型在訓練步驟僅為 1/5.8 的情況下,達到了與 DeepSeek-R1-Zero(671B MoE)相當的回應長度。這種效率驗證了簡約方法在大型 RL 訓練中的有效性。
主要實驗結果顯示,Open-Reasoner-Zero 在多個評估指標上表現優異,特別是在 32B 配置中。它在 GPQA DIAMOND 基準上相比 DeepSeek-R1-Zero-Qwen2.5-32B 獲得了更好的結果,訓練步驟僅需 1/30,展現出驚人的訓練效率。此外,7B 變體展現出有趣的學習動態,準確性穩定提高,回應長度增長模式劇烈。在評估過程中觀察到一種獨特的「階段時刻」現象,特徵是獎勵和回應長度的突然增加,特別在 GPQA DIAMOND 和 AIME2024 基準中尤為明顯。
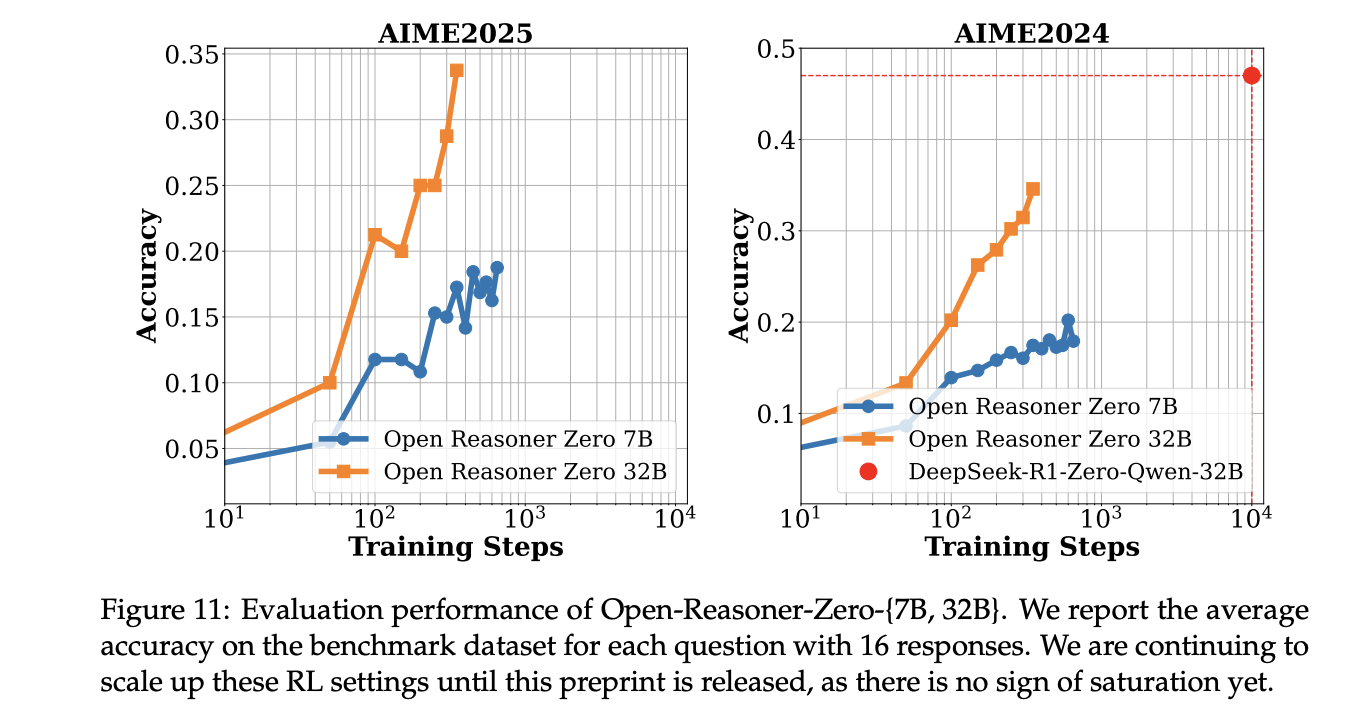
在這篇論文中,研究人員介紹了 Open-Reasoner-Zero,這代表著在民主化大型推理導向 RL 訓練語言模型方面的一個重要里程碑。研究顯示,使用普通的 PPO 結合 GAE 和基於規則的獎勵函數的簡化方法可以達到與更複雜系統相當的結果。成功的實施不需要 KL 正則化,證明了為了獲得強大的推理能力,可能不需要複雜的架構修改。通過開源完整的訓練流程並分享詳細見解,這項工作為未來在擴展語言模型推理能力的研究奠定了基礎,這僅僅是 AI 發展中新擴展趨勢的開始。
查看論文和 GitHub 頁面。所有的研究成果都歸功於這個項目的研究人員。此外,隨時歡迎在 Twitter 上關注我們,別忘了加入我們的 80k+ 機器學習 SubReddit。
🚨 推薦閱讀 – LG AI 研究發布 NEXUS:一個先進的系統,整合代理 AI 系統和數據合規標準,以解決 AI 數據集中的法律問題
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}