


之前我們討論了如何將強化學習應用於常微分方程(ODEs),透過在健身房中整合ODEs。ODEs是一種強大的工具,可以描述各種系統,但僅限於單一變數。偏微分方程(PDEs)則是涉及多個變數的微分方程,能涵蓋更廣泛和更複雜的系統。通常,ODEs是PDEs的特例或特殊假設。
PDEs包括麥克斯威爾方程(Maxwell’s Equations,控制電和磁)、納維-斯托克斯方程(Navier-Stokes equations,控制流體流動,如飛機、引擎、血液等)以及玻爾茲曼方程(Boltzmann equation,熱力學)。PDEs可以描述如柔性結構、電力網、製造或生物學中的流行病模型等系統。它們能夠表現出高度複雜的行為;納維-斯托克斯方程描述了急流中的漩渦。這些方程捕捉和揭示現實世界系統更複雜行為的能力,使它們成為重要的研究主題,無論是在描述系統還是分析已知方程以發現新知識方面。整個領域(如流體動力學、電動力學、結構力學)可以專注於研究單一組PDEs。
這種複雜性增加了分析和控制的難度;PDEs所捕捉的系統比ODEs更難以分析和控制。ODEs也被描述為集中參數系統,描述它們的各種參數和變數被“集中”到一個離散點(或對於耦合的ODE系統,少數幾個點)。PDEs則是分佈參數系統,跟蹤整個空間和時間的行為。換句話說,ODE的狀態空間是相對較少的變數,例如時間和特定點的幾個系統測量。對於PDE/分佈參數系統,狀態空間的大小可以接近無限維度,或者在計算中被離散化為每個時間步驟的數百萬個點。集中參數系統根據少數幾個傳感器控制引擎的溫度,而PDE/分佈參數系統則管理整個引擎的溫度動態。
與ODEs類似,許多PDEs必須通過建模和模擬來分析(除了特殊情況)。然而,由於維度更高,這種建模變得更加複雜。許多ODEs可以通過MATLAB的ODE45或SciPy的solve_ivp等算法的簡單應用來解決。PDEs則在網格或網狀結構上建模,PDE在網格的每個點上被簡化為代數方程(例如通過泰勒級數展開)。網格生成是一個獨立的領域,既是科學也是藝術,理想(或可用)的網格可以根據問題的幾何形狀和物理特性有很大差異。網格(因此問題的狀態空間)可以有數百萬個點,計算時間可能需要幾天或幾周,而PDE求解器通常是商業軟件,價格高達數萬美元。
控制PDEs比控制ODEs面臨更大的挑戰。拉普拉斯變換是許多經典控制理論的基礎,是一種一維變換。雖然在PDE控制理論方面已有一些進展,但該領域並不像ODE/集中系統那樣全面。對於PDEs,即使是基本的可控性或可觀察性評估也變得困難,因為評估的狀態空間增長了幾個數量級,且較少的PDE有解析解。出於必要,我們會遇到設計問題,例如需要控制或觀察域的哪一部分?其餘的域可以處於任意狀態嗎?控制器需要在哪個子集上運作?由於控制理論中的關鍵工具尚未發展成熟,並且出現了新問題,應用機器學習成為理解和控制PDE系統的重要研究領域。
鑒於PDEs的重要性,研究人員已經開始開發控制策略。例如,Glowinski等人從高級函數分析中開發了一種基於分析伴隨的方法,依賴於系統的模擬。其他方法,如Kirsten Morris所討論的,則應用估算來降低PDE的階數,以便促進更傳統的控制方法。Botteghi和Fasel已經開始將機器學習應用於這些系統的控制(注意,這只是研究的一個非常簡短的概述)。在這裡,我們將在兩個PDE控制問題上應用強化學習。擴散方程是一個簡單的線性二階PDE,具有已知的解析解。Kuramoto–Sivashinsky(K-S)方程是一個更複雜的四階非線性方程,用於模擬火焰前的穩定性。
對於這兩個方程,我們使用一個簡單的小正方形網格域。我們的目標是在域中間的一條線的目標區域中達到正弦波形,通過控制左右兩側的輸入來實現。控制的輸入參數是目標區域的值和輸入控制點的{x,y}坐標。訓練算法需要通過時間建模系統的發展,並使用控制輸入。正如上面所討論的,這需要一個網格,在每個點上解決方程,然後在每個時間步驟中進行迭代。我使用py-pde包來創建強化學習者的訓練環境(感謝這個包的開發者提供的及時反饋和幫助!)。在py-pde環境中,方法與強化學習的常規過程相同:特定算法發展出控制器策略的猜測。該控制器策略在小的離散時間步驟中應用,並根據系統的當前狀態提供控制輸入,以獲得某種獎勵(在這種情況下,是目標和當前分佈之間的均方根差)。
與之前的情況不同,我僅展示基因編程控制器的結果。我開發了代碼以應用軟性演員評論家(SAC)算法,作為AWS Sagemaker上的容器執行。然而,完全執行需要約50小時,我不想花那麼多錢!我尋找減少計算時間的方法,但最終因時間限制而放棄;這篇文章已經因為我的工作、軍事預備役、假期的家庭訪問、社區和教會的參與而拖延了很久,還不想讓我的妻子獨自照顧我們的寶寶!
首先,我們將討論擴散方程:
其中x是一個二維笛卡爾向量,∆是拉普拉斯算子。正如提到的,這是一個簡單的二階(第二導數)線性偏微分方程,涉及時間和二維空間。μ是擴散係數,決定影響在系統中傳播的速度。擴散方程傾向於在邊界上擴散(洗掉!)影響,並表現出穩定的動態。PDE的實現如下所示,包括網格、方程、邊界條件、初始條件和目標分佈:
from pde import Diffusion, CartesianGrid, ScalarField, DiffusionPDE, pde
grid = pde.CartesianGrid([[0, 1], [0, 1]], [20, 20], periodic=[False, True])
state = ScalarField.random_uniform(grid, 0.0, 0.2)
bc_left={"value": 0}
bc_right={"value": 0}
bc_x=[bc_left, bc_right]
bc_y="periodic"
#bc_x="periodic"
eq = DiffusionPDE(diffusivity=.1, bc=[bc_x, bc_y])
solver=pde.ExplicitSolver(eq, scheme="euler", adaptive = True)
#result = eq.solve(state, t_range=dt, adaptive=True, tracker=None)
stepper=solver.make_stepper(state, dt=1e-3)
target = 1.*np.sin(2*grid.axes_coords[1]*3.14159265)
這個問題對擴散係數和域大小非常敏感;這兩者之間的不匹配會導致控制輸入在到達目標區域之前被洗掉,除非計算的模擬時間較長。控制輸入每0.1時間步驟更新一次,直到結束時間T=15。
由於py-pde包的架構,控制是應用於邊界內的一列。將py-pde包結構化以在每個時間步驟更新邊界條件會導致內存洩漏,py-pde的開發者建議使用一個步進函數作為解決方案,這不允許更新邊界條件。這意味著結果並不完全符合物理現實,但確實展示了使用強化學習進行PDE控制的基本原則。
基因編程算法在約30次迭代後,最終獎勵(中央列所有20個點的均方誤差總和)達到了約2.0。結果如下所示,目標和實現的分佈在目標區域內。

現在來看更有趣和複雜的K-S方程:
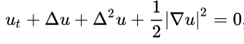
與擴散方程不同,K-S方程展現了豐富的動態(正如描述火焰行為的方程所應有的!)。解可能包括穩定的平衡或行進波,但隨著域大小的增加,所有解最終都會變得混亂。PDE的實現如下代碼:
grid = pde.CartesianGrid([[0, 10], [0, 10]], [20, 20], periodic=[True, True])
state = ScalarField.random_uniform(grid, 0.0, 0.5)
bc_y="periodic"
bc_x="periodic"
eq = PDE({"u": "-gradient_squared(u) / 2 - laplace(u + laplace(u))"}, bc=[bc_x, bc_y])
solver=pde.ExplicitSolver(eq, scheme="euler", adaptive = True)
stepper=solver.make_stepper(state, dt=1e-3)
target=1.*np.sin(0.25*grid.axes_coords[1]*3.14159265)
控制輸入限制在+/-5。K-S方程自然不穩定;如果域中的任何點超過+/-30,迭代將終止,並因導致系統發散而獲得一個大的負獎勵。在py-pde中對K-S方程的實驗顯示對域大小和網格點數的強敏感性。該方程運行了T=35,並在dt=0.1時進行控制和獎勵更新。
對於每個方程,基因編程算法在找到解的過程中比擴散方程更困難。當解變得視覺上接近時,我選擇手動停止執行;再次強調,我們在這裡尋找一般原則。對於這個更複雜的系統,控制器的效果更好——可能是因為K-S方程的動態性,控制器能夠產生更大的影響。然而,在評估不同運行時間的解時,我發現它並不穩定;算法學會在特定時間到達目標分佈,而不是在該解上穩定。算法收斂到以下解,但如後續時間步驟所示,該解不穩定,並隨著時間步驟的增加而開始發散。
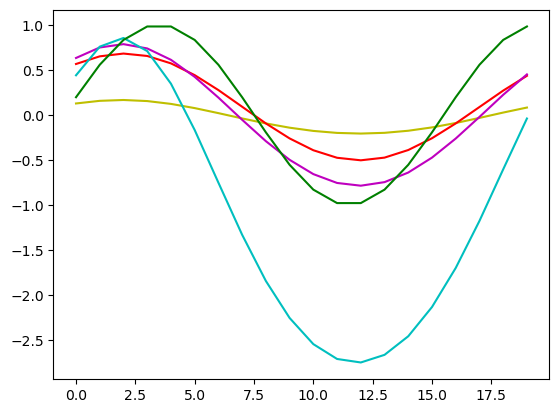
對獎勵函數的仔細調整將有助於獲得更長時間保持的解,強調了正確獎勵函數的重要性。此外,在所有這些情況下,我們並沒有得到完美的解;但特別是對於K-S方程,我們獲得了相對較少努力的合理解,與非強化學習方法相比。
基因編程解決更複雜的問題需要更長的時間,並且在處理大型輸入變數集時遇到困難。要使用更大的輸入集,生成的方程變得更長,這使得其不易解釋且計算速度較慢。解方程的項數比ODE系統中的十幾個多得多。神經網絡方法可以更輕鬆地處理大型輸入變數集,因為輸入變數僅直接影響輸入層的大小。此外,我懷疑神經網絡能夠更好地處理更複雜和更大的問題,這在之前的帖子中已經討論過。因此,我為py-pde擴散方程開發了健身房,這可以根據py-pde文檔輕鬆適應其他PDEs。這些健身房可以與不同的基於神經網絡的強化學習方法一起使用,例如我開發的SAC算法(如前所述,運行但需要時間)。
對基因編程方法也可以進行調整。例如,輸入的向量表示可以減少解方程的大小。Duriez等人提出使用拉普拉斯變換將導數和積分引入基因編程方程,擴大它們可以探索的函數空間。
解決更複雜問題的能力非常重要。正如上面所討論的,PDEs可以描述各種複雜的現象。目前,控制這些系統通常意味著集中參數。這樣做會忽略動態,因此我們最終會與這些系統對抗,而不是與它們合作。控制或管理這些系統的努力意味著更高的控制成本、錯過效率和增加失敗(小或災難性)的風險。更好地理解和控制PDE系統的替代方案可以在工程領域解鎖重大收益,這些領域的邊際改進已經成為標準,例如交通、供應鏈和核聚變,因為這些系統表現為高維分佈參數系統。它們非常複雜,具有非線性和突現現象,但擁有大量可用數據集——這對於機器學習來說是理想的,可以突破當前在理解和優化方面的障礙。
目前,我只是對將機器學習應用於控制PDEs進行了非常基本的探討。控制問題的後續研究不僅包括不同的系統,還包括優化控制應用於域中的位置、實驗減少觀察空間的階數以及優化控制以簡化或降低控制成本。除了提高控制效率,正如Brunton和Kutz所討論的,機器學習還可以用於推導複雜物理系統的數據驅動模型,並確定減少狀態空間大小的模型,這可能更易於通過傳統或機器學習方法進行分析和控制。機器學習和PDEs是一個令人興奮的研究領域,我鼓勵你去看看專業人士在做什麼!
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}