


大型語言模型(LLMs)透過處理大量數據集來生成連貫的輸出,並專注於改善推理的思路鏈(CoT)。這種方法使模型能夠將複雜的問題分解成一系列步驟,模擬人類的邏輯推理。生成結構化的推理回應一直是一個主要挑戰,通常需要大量的計算資源和大規模數據集來達到最佳性能。最近的努力旨在提高LLMs的效率,確保它們在保持高推理準確度的同時,所需的數據更少。
改善LLM推理的一個主要困難是訓練它們生成長的CoT回應,並具備結構化的自我反思、驗證和回溯。雖然現有模型已顯示出進展,但訓練過程通常需要在大量數據集上進行昂貴的微調。此外,大多數專有模型保持其方法的閉源,這使得更廣泛的可及性受到限制。對於能夠保留推理能力的數據高效訓練技術的需求日益增加,促使研究人員探索新的方法,以優化性能而不造成過高的計算成本。了解LLMs如何能夠有效地獲得結構化推理,並使用更少的訓練樣本,對未來的進展至關重要。
傳統的改善LLM推理的方法依賴於完全監督的微調(SFT)和像低秩適應(LoRA)這樣的參數高效技術。這些技術幫助模型在不需要對龐大數據集進行全面重新訓練的情況下,精煉其推理過程。包括OpenAI的o1-preview和DeepSeek R1在內的幾個模型在邏輯一致性方面取得了進展,但仍然需要大量的訓練數據。
來自加州大學伯克利分校的研究團隊提出了一種新穎的訓練方法,旨在以最少的數據增強LLM推理。他們並不依賴數以百萬計的訓練樣本,而是實施了一種僅使用17,000個CoT範例的微調方法。該團隊將他們的方法應用於Qwen2.5-32B-Instruct模型,利用SFT和LoRA微調來實現顯著的性能提升。他們的方法強調優化推理步驟的結構完整性,而不是內容本身。通過精煉邏輯一致性並最小化不必要的計算開銷,他們成功地訓練LLMs以更有效的方式進行推理,同時使用的數據樣本顯著減少。該團隊的方法還提高了成本效率,使其適用於更廣泛的應用,而不需要專有數據集。
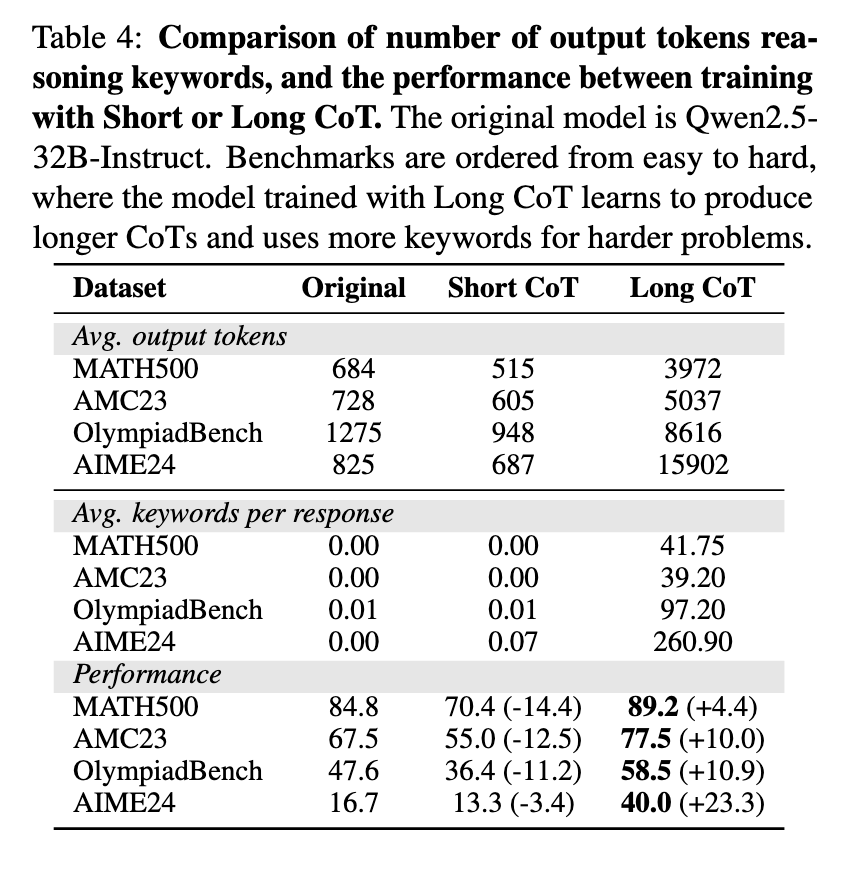
這項研究顯示,CoT的結構在提升LLM推理性能方面扮演著關鍵角色。實驗顯示,改變訓練數據的邏輯結構會顯著影響模型的準確性,而改變單個推理步驟的影響則微乎其微。團隊進行了控制試驗,隨機打亂、刪除或插入推理步驟,以觀察其對性能的影響。結果顯示,破壞CoT的邏輯順序會顯著降低準確性,而保持其結構並維持最佳推理能力則至關重要。LoRA微調使模型能夠更新不到5%的參數,提供了一種高效的替代方案,無需全面微調,同時保持競爭性能。
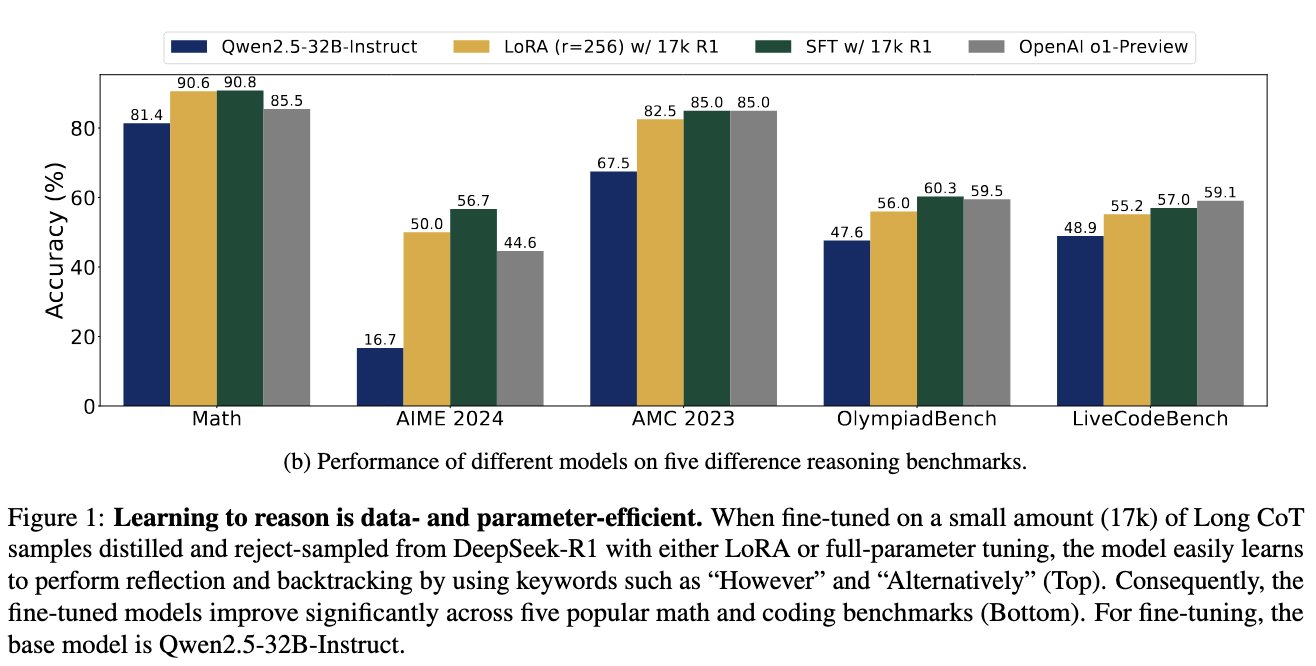
性能評估顯示推理能力有顯著改善。使用17,000個CoT樣本訓練的Qwen2.5-32B-Instruct模型在AIME 2024上達到了56.7%的準確率,提升了40.0%。該模型在LiveCodeBench上得分57.0%,反映出8.1%的增長。在Math-500上,它達到了90.8%,比之前的基準提高了6.0%。同樣,在AMC 2023上達到85.0%(+17.5%),在OlympiadBench上達到60.3%(+12.7%)。這些結果顯示,高效的微調技術使LLMs能夠達到與專有模型如OpenAI的o1-preview相當的競爭結果,後者在AIME 2024上得分44.6%,在LiveCodeBench上得分59.1%。這些發現強調了結構化推理訓練使模型在不需要過多數據的情況下提升性能的可能性。
這項研究突顯了在提高LLM推理效率方面的一項重大突破。通過將重點從對大規模數據的依賴轉向結構完整性,研究人員開發了一種訓練方法,確保在最小計算資源下仍能保持強大的邏輯一致性。這種方法減少了對龐大數據集的依賴,同時保持了穩健的推理能力,使LLMs更具可及性和可擴展性。這項研究所獲得的見解為未來模型的優化鋪平了道路,顯示結構化微調策略能有效提升LLM推理,而不妨礙效率。這一發展標誌著使複雜的AI推理模型更實用於廣泛使用的一步。
查看論文和GitHub頁面。這項研究的所有功勞都歸於這個項目的研究人員。此外,隨時在Twitter上關注我們,並別忘了加入我們的75k+ ML SubReddit。
🚨 推薦的開源AI平台:‘IntellAgent是一個開源的多代理框架,用於評估複雜的對話AI系統’(推廣)
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}