


機器透過訓練大量數據集來學習如何連結圖像和文字,更多的數據能幫助模型識別模式並提高準確性。視覺語言模型 (VLMs) 依賴這些數據集來執行像是圖像標題和視覺問題回答等任務。問題是,將數據集增加到 1000 億個範例是否會顯著提高準確性、文化多樣性,以及對資源不足語言的支持。超過 100 億的擴展速度已經放緩,並且對是否會有進一步的好處產生懷疑。如此龐大的數據也帶來了質量控制問題、偏見和計算限制。
目前,視覺語言模型依賴於像是概念標題 (Conceptual Captions) 和 LAION 等龐大數據集,這些數據集包含數百萬到數十億的圖像-文字對。這些數據集使得零樣本分類和圖像標題成為可能,但它們的進展已經放緩到約 100 億對。這一限制減少了進一步提高模型準確性、包容性和多語言理解的可能性。現有的方法基於網路爬蟲數據,這會導致低質量樣本、語言偏見和多元文化的代表性不足。進一步擴展的效率在這一點上是值得懷疑的,這使得僅僅增加數據集大小是否能帶來實質性改善成為問題。
為了減少視覺語言模型在文化多樣性和多語言性方面的限制,來自 Google Deepmind 的研究人員提出了 WebLI-100B,這是一個包含 1000 億圖像-文字對的數據集,這是之前數據集的十倍。這個數據集捕捉了稀有的文化概念,並改善了模型在資源不足語言和多樣化表現等較少探索領域的表現。與之前的數據集不同,WebLI-100B 專注於擴展數據,而不是依賴於重度過濾,這通常會刪除重要的文化細節。這個框架涉及在 WebLI-100B 數據集的不同子集 (1B、10B 和 100B) 上進行預訓練,以分析數據擴展的影響。使用完整數據集訓練的模型在文化和多語言任務上表現優於使用較小數據集訓練的模型,即使使用相同的計算資源。這個數據集保持了語言和文化元素的廣泛代表性,使其更具包容性。
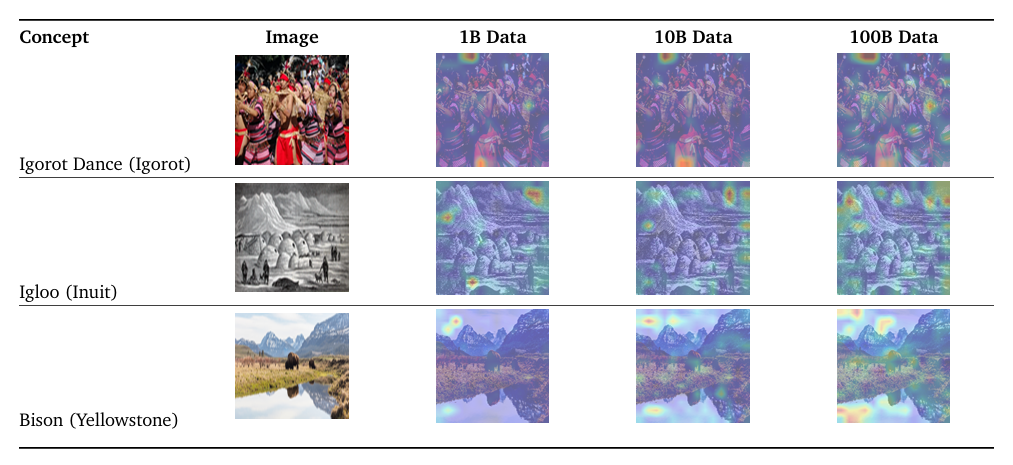
研究人員創建了一個質量過濾的 5B 數據集和一個語言重平衡版本,以增加資源不足語言的樣本量。他們使用 SigLIP 模型,在不同的數據集大小 (1B、10B 和 100B) 上進行訓練,使用 ViT 架構和對比學習方法。評估涵蓋了零樣本和少樣本分類任務,如 ImageNet、CIFAR–100 和 COCO Captions,以及文化多樣性基準,如 Dollar Street 和 GeoDE,還有使用 Crossmodal-3600 的多語言檢索。結果顯示,將數據集大小從 10B 增加到 100B 對西方中心的基準影響不大,但在文化多樣性任務和資源不足語言檢索上有改善。偏見分析顯示,儘管性能差異隨著多樣性增長而改善,但性別相關的代表性和聯想偏見仍然存在。最後,研究人員使用 PaliGemma 評估模型在生成任務上的可轉移性,測試了凍結和未凍結設置在下游視覺語言應用中的表現。
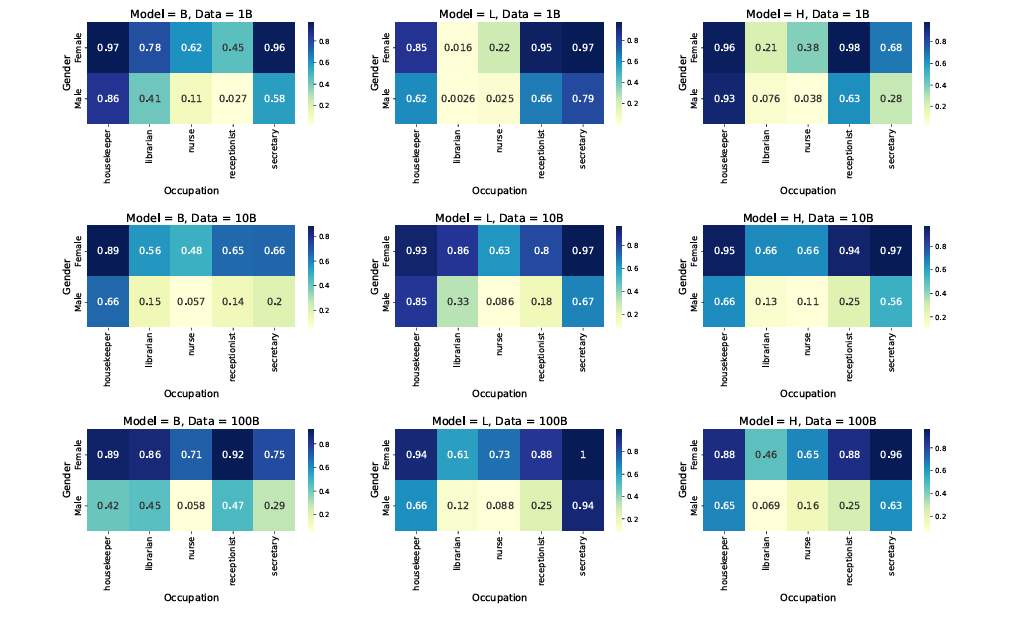
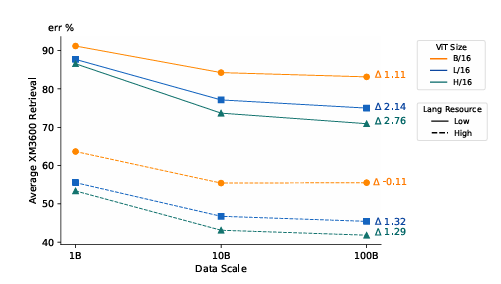
總結來說,將視覺語言預訓練數據集擴展到 1000 億圖像-文字對,提高了包容性,增強了文化多樣性和多語言性,並減少了不同子群體之間的性能差距,儘管傳統基準顯示增長有限。雖然像 CLIP 這樣的質量過濾器提高了標準任務的性能,但它們往往會降低數據多樣性。這項工作可以作為未來研究的參考,促進創建保持多樣性的過濾算法和促進包容性的訓練策略,而不需要額外的數據,並為未來在平衡性能、多樣性和公平性方面的改進提供資訊。
查看論文。這項研究的所有功勞都歸於這個項目的研究人員。此外,隨時在 Twitter 上關注我們,別忘了加入我們的 75k+ 機器學習 SubReddit。
🚨 推薦的開源 AI 平台:‘IntellAgent 是一個開源的多代理框架,用於評估複雜的對話 AI 系統’ (推廣)
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}