


DeepSeek Janus-Pro 是由 DeepSeek 開發的一個開源多模態人工智慧模型,旨在將視覺和語言處理能力整合在一個統一的架構中。
它使用 SigLIP-L 視覺編碼器,能夠實現從文本提示生成圖像和全面理解圖像的功能。
在本地運行它可以確保隱私、安全控制,並且反應速度更快,而不需要依賴雲端解決方案。
在這篇指南中,我們將一步一步教你如何在你的電腦上安裝和使用 DeepSeek Janus-Pro,涵蓋安裝、配置和最佳實踐,以最大化其潛力。
什麼是 DeepSeek Janus 系列?
DeepSeek Janus 系列是一組先進的多模態人工智慧模型,旨在無縫處理和生成文本和視覺數據。
系列中的每個模型都在前一個模型的基礎上進行改進,提高了效率、準確性和圖像生成質量。以下是三個模型的簡介:
1. Janus

Janus 是該系列的基礎,擁有統一的變壓器架構,使其能夠有效處理語言和視覺任務。它使用自回歸框架,意味著它一步一步預測序列,適合用於圖像標題生成、基於文本的圖像檢索和多模態推理等任務。
2. JanusFlow

JanusFlow 在 Janus 的基礎上進一步擴展,引入了基於流的修正技術,增強了其圖像生成能力。這使得生成的視覺輸出比前一代更平滑、更連貫。該模型優化了穩定性和高品質渲染,使其成為現有文本到圖像模型的強勁競爭者。
3. Janus-Pro
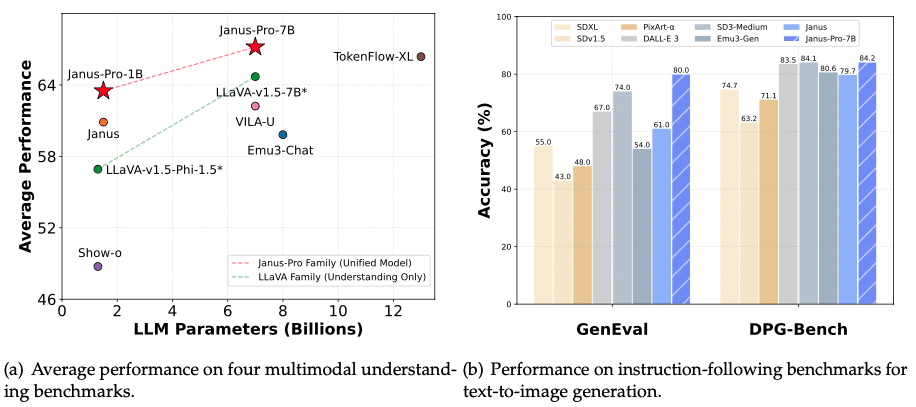
該系列中最先進的模型 Janus-Pro,專為高性能的多模態人工智慧應用而設計。它的特點包括:
- 擴展的訓練數據集,提高文本和圖像的理解能力。
- 優化的推理效率,實現更快的反應時間。
- 優越的圖像生成,經常在基準測試中超越 DALL-E 3 和 Stable Diffusion。
DeepSeek Janus-Pro 安裝步驟指南
1. 系統要求
在安裝之前,確保你的系統滿足以下要求:
硬體要求:
- GPU:NVIDIA GPU,至少 16GB VRAM(例如 RTX 3090、RTX 4090),以確保流暢性能。
- RAM:至少 16GB(建議 32GB 以獲得最佳性能)。
- 存儲:至少 20GB 的可用空間,用於模型權重和依賴項。
- CPU:現代多核心處理器(建議使用 Intel i7/AMD Ryzen 7 或更高版本)。
軟體要求:
- 操作系統:Windows 10/11(64 位元)。
- Python:版本 3.8 或更高(建議使用 3.10+)。
- CUDA 工具包:用於 GPU 加速(確保與你的 GPU 驅動程式相容)。
- Microsoft Visual C++ Build Tools:用於編譯某些 Python 套件。
2. 安裝必要的軟體和依賴項
步驟 1:安裝 Python
從官方網站下載 Python 3.10+。
在安裝過程中,勾選「將 Python 添加到 PATH」的選項,然後點擊安裝。
使用以下命令驗證安裝:
步驟 2:安裝 CUDA 工具包(適用於 NVIDIA GPU)
從 NVIDIA 的網站下載 CUDA 工具包。
安裝時,確保它與你的 GPU 驅動版本相符。
步驟 3:安裝 Microsoft Visual C++ Build Tools
3. 設置虛擬環境
為了避免與其他 Python 專案發生衝突,創建一個虛擬環境。
– 打開命令提示字元,並導航到你希望的專案目錄:
– 創建虛擬環境:
– 啟動虛擬環境:
(你會看到 (janus_env) 出現在命令行之前,表示它已被啟動。)
4. 安裝所需的 Python 套件
– 首先升級 pip:
現在,安裝所需的依賴項。
– 安裝支持 CUDA 的 PyTorch(用於 GPU 加速):
(將 cu118 替換為你的 CUDA 版本,例如,對於 CUDA 12.1,使用 cu121。)
– 安裝 Hugging Face Transformers 庫:
– (可選)安裝 SentencePiece 和其他分詞工具:
5. 下載並加載 DeepSeek Janus-Pro 7B 模型
我們將使用 Hugging Face Transformers 下載並加載模型。
– 創建一個 Python 腳本(例如 download_model.py),並添加以下代碼:
model_name = “deepseek-ai/Janus-Pro-7B”
# 加載分詞器和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
print(“模型和分詞器下載成功!”)
– 運行腳本以下載模型:
這將自動將 Janus-Pro 7B 模型下載到你的本地計算機。
6. 在本地運行 DeepSeek Janus-Pro 7B
現在,讓我們通過生成對提示的回應來測試模型。
– 創建另一個 Python 腳本(例如 run_janus.py),並添加:
model_name = “deepseek-ai/Janus-Pro-7B”
# 加載分詞器和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# 輸入提示
input_text = “描述一個擁有 AI 驅動基礎設施的未來城市。”
inputs = tokenizer(input_text, return_tensors=”pt”)
# 生成回應
outputs = model.generate(**inputs, max_length=100)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(“AI 回應:”, response)
運行腳本:
模型將處理輸入並根據 DeepSeek Janus-Pro 的能力生成 AI 生成的回應。
示例:使用 DeepSeek Janus-Pro 增強圖像描述
現在,讓我們使用 DeepSeek Janus-Pro 7B 來改進標題,使其更詳細和吸引人。
步驟 1:安裝並加載 Janus-Pro
步驟 2:生成增強的描述
# 加載 DeepSeek Janus-Pro 7B
model_name = “deepseek-ai/Janus-Pro-7B”
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# 生成增強的描述
input_text = f”改進這個圖像描述:'{caption}’。使其更具吸引力和詳細。”
inputs = tokenizer(input_text, return_tensors=”pt”)
outputs = model.generate(**inputs, max_length=150)
enhanced_caption = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(“增強的標題:”, enhanced_caption)
示例輸出
輸入圖像

BLIP 生成的標題
「海面上美麗的日落,波浪拍打著海岸。」
DeepSeek Janus-Pro 增強的標題
夕陽在橙色、粉色和紫色的迷人混合中落下,映照在平靜的海浪上,輕輕親吻著金色的海岸。遠處的帆船剪影為這個寧靜的場景增添了一絲冒險的色彩。」
在 DeepSeek Janus-Pro 7B 中優化性能
DeepSeek Janus-Pro 7B 是一個強大的模型,但通過優化推理速度、降低內存使用和改善回應質量,可以顯著提高其可用性。以下是實現這些目標的關鍵策略。
1. 使用 GPU 加速提高推理速度
使用 GPU(支持 NVIDIA CUDA)可以大幅提高推理速度,相比於 CPU 執行。
– 啟用 GPU 支持(使用 PyTorch 和 CUDA)
首先,確保 PyTorch 能夠檢測到你的 GPU:
print(“GPU 可用:”, torch.cuda.is_available())
print(“GPU 名稱:”, torch.cuda.get_device_name(0) if torch.cuda.is_available() else “無”)
如果在 CPU 上運行,請切換到 GPU:
model.to(device)
– 使用 Flash Attention 提高推理速度
Flash Attention 優化了大型模型的內存使用。通過以下方式安裝:
然後,在加載模型時啟用它:
model_name = “deepseek-ai/Janus-Pro-7B”
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, attn_implementation=”flash_attention_2″).to(“cuda”)
2. 降低內存消耗(使用量化)
量化通過將權重從 FP32 轉換為 INT8/4 位精度,減少模型的內存佔用,使其更容易在消費者 GPU 上運行。
– 安裝 BitsandBytes 以支持 4 位和 8 位量化
– 使用 4 位量化加載 Janus-Pro
quant_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=quant_config).to(“cuda”)
量化的好處:
- 將 VRAM 使用量從 30GB+ 降低到 8GB-12GB(在 RTX 3090/4090 上運行)。
- 使中檔 GPU(如 RTX 3060,12GB)能夠進行推理。
調整參數以改善回應生成
調整參數可以改善回應質量,平衡創造力、連貫性和準確性。
1. 調整溫度和 Top-k 抽樣
溫度(0.2–1.0):較低的值 = 更具事實性的回應;較高的值 = 創造性。
Top-k 抽樣(Top 40-100):限制詞彙選擇以減少隨機性。
inputs = tokenizer(input_text, return_tensors=”pt”).to(“cuda”)
output = model.generate(**inputs, max_length=300, temperature=0.7, top_k=50, top_p=0.9)
print(tokenizer.decode(output[0], skip_special_tokens=True))
對於事實性答案,使用較低的溫度(0.2-0.5),top_k=40;對於創意寫作,使用較高的溫度(0.7-1.0),top_k=100。
故障排除常見問題
即使安裝正確,用戶也可能會遇到與硬體、相容性或性能相關的錯誤。以下是解決這些問題的方法。
1. 安裝錯誤及修復
錯誤:pip install deepseek 失敗
修復:使用 pip install transformers torch 代替。
錯誤:torch.cuda.is_available() = False
修復:安裝與 CUDA 相容的 PyTorch 版本:
2. 模型無法加載或運行緩慢
問題:模型在 CPU 上加載太慢
修復:使用 GPU 或以 8 位/4 位模式加載模型:
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=quant_config).to(“cuda”)
問題:在低 VRAM GPU 上內存不足(OOM)
修復:減少序列長度並使用 4 位量化。
3. 與操作系統或硬體的相容性問題
錯誤:torch: 無法分配內存
修復:增加交換內存(Linux/macOS):
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile
錯誤:模型在 Windows WSL 上失敗
修復:在本地 Linux 中運行或使用 WSL 2 進行 CUDA。
與其他本地 AI 模型的比較
另請參閱:哪個是最佳的?DeepSeek vs. ChatGPT vs. Perplexity vs. Gemini
結論
DeepSeek Janus-Pro 提供了一種強大的方法來在本地運行先進的 AI 模型,通過 GPU 加速、量化和微調參數來優化性能。無論你是在構建 AI 應用程序還是實驗大型語言模型,掌握這些技術都能提高效率和可擴展性。
要深入了解 AI 和機器學習,Great Learning 的人工智慧課程提供專家主導的培訓,涵蓋模型部署、優化和實際應用,幫助你在 AI 革命中保持領先。
另請參閱:
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}