


編輯備註:這篇文章最初於2023年3月13日發表,已進行更新。
在1956年,邁爾斯·戴維斯五重奏(Miles Davis Quintet)正在錄音室為Prestige Records錄製數十首曲子,麥克風已經開啟,錄音也在進行中。
當一位工程師詢問下一首歌曲的標題時,戴維斯回答說:“我會先演奏,然後再告訴你這是什麼。”
就像這位多產的爵士小號手和作曲家一樣,研究人員也在快速生成人工智慧(AI)模型,探索新的架構和應用案例。根據斯坦福人本中心人工智慧研究所(Stanford Institute for Human-Centered Artificial Intelligence)2024年的AI指數報告,2023年發表了149個基礎模型,這是2022年發表數量的兩倍多。
他們表示,變壓器模型(transformer models)、大型語言模型(LLMs)、視覺語言模型(VLMs)和其他正在構建的神經網絡都是他們稱之為基礎模型(foundation models)的重要新類別的一部分。
基礎模型的定義
基礎模型是一種人工智慧神經網絡,通過大量原始數據進行訓練,通常使用無監督學習,能夠適應完成廣泛的任務。
有兩個重要概念幫助定義這個總類別:數據收集變得更容易,機會如同地平線般廣闊。
沒有標籤,機會無限
基礎模型通常從未標記的數據集中學習,這樣可以節省手動描述每個項目的時間和費用。
早期的神經網絡是針對特定任務進行精細調整的。通過少量的微調,基礎模型可以處理從翻譯文本到分析醫學影像,再到執行基於代理的行為等各種工作。
斯坦福中心的主任佩西·梁(Percy Liang)在基礎模型的首次研討會開幕演講中表示:“我認為我們只揭示了現有基礎模型能力的一小部分,更不用說未來的模型了。”
人工智慧的出現與同質化
在那次演講中,梁創造了兩個術語來描述基礎模型:
出現(Emergence)指的是仍在發現的人工智慧特徵,例如基礎模型中的許多新興技能。他稱AI算法和模型架構的融合為同質化(homogenization),這是一種幫助形成基礎模型的趨勢。(見下圖)
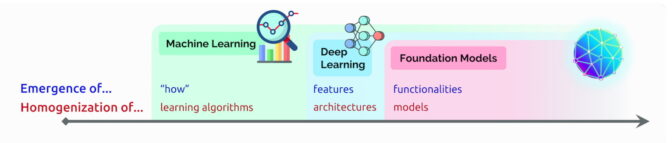 這個領域仍在快速發展。
這個領域仍在快速發展。
在這個團體定義基礎模型的一年後,其他科技觀察者創造了一個相關術語——生成式人工智慧(generative AI)。這是一個總稱,涵蓋變壓器、大型語言模型、擴散模型和其他神經網絡,因為它們能創造文本、圖像、音樂、軟體、視頻等,吸引了人們的想像。
生成式人工智慧有潛力產生數兆美元的經濟價值,這是風險投資公司紅杉資本(Sequoia Capital)的高管在最近的一個AI播客中分享的觀點。
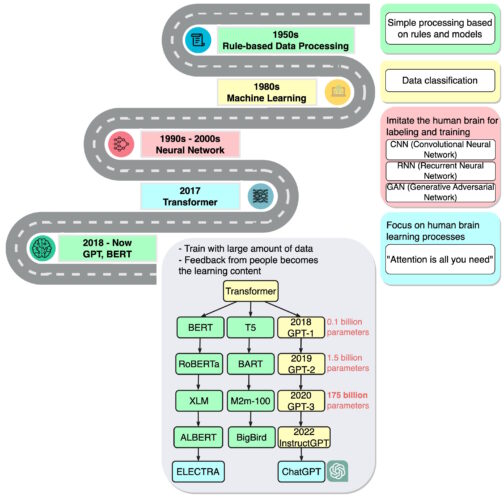
基礎模型的簡史
“我們正處於一個簡單方法如神經網絡帶來新能力爆炸的時代,”曾在Google Brain擔任高級研究科學家的企業家阿希什·瓦斯瓦尼(Ashish Vaswani)表示,他主導了2017年關於變壓器的開創性論文。
這項工作啟發了研究人員創建BERT和其他大型語言模型,使2018年成為自然語言處理的“分水嶺時刻”,一份關於人工智慧的報告在那年年底如此評價。
Google將BERT作為開源軟體發布,催生了一系列後續模型,並引發了建立越來越大、更強大的LLMs的競賽。然後,它將這項技術應用於其搜索引擎,使用戶可以用簡單的句子提問。
在2020年,OpenAI的研究人員宣布了另一個里程碑式的變壓器,GPT-3。幾周內,人們開始使用它創作詩歌、程式、歌曲、網站等。
研究人員寫道:“語言模型對社會有廣泛的有益應用。”
他們的工作還顯示了這些模型的龐大和計算密集性。GPT-3在近一兆個詞的數據集上進行訓練,擁有驚人的1750億個參數,這是衡量神經網絡能力和複雜度的關鍵指標。2024年,Google發布了Gemini Ultra,這是一個最先進的基礎模型,需要50億個petaflops的計算能力。
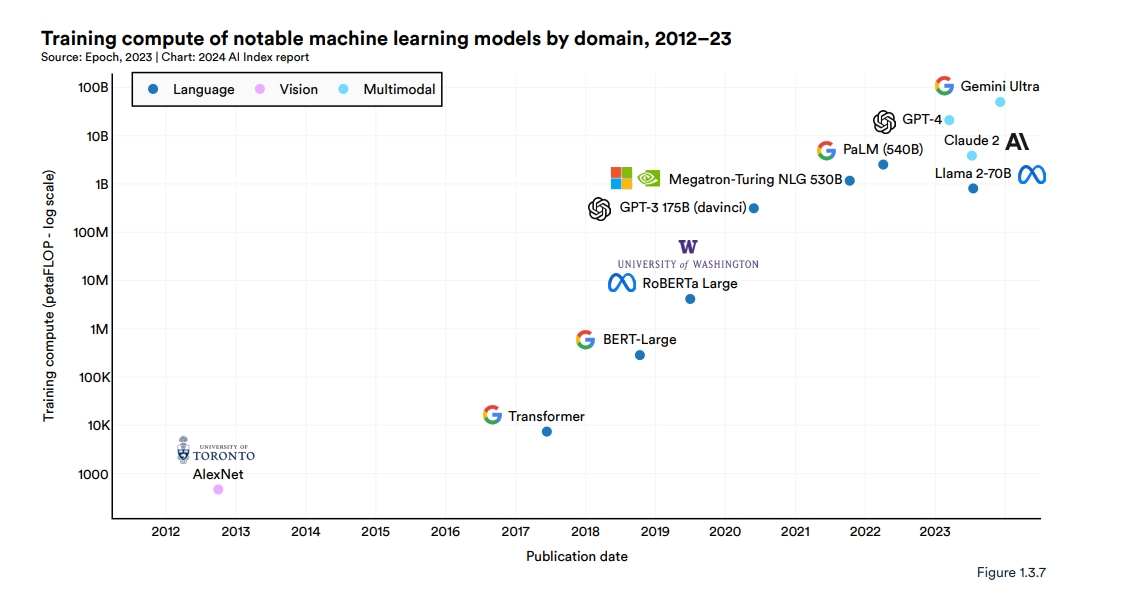
梁在一次播客中提到:“我只記得對它能做的事情感到驚訝。”
最新版本的ChatGPT——在10,000個NVIDIA GPU上進行訓練——更加引人入勝,僅在兩個月內就吸引了超過1億用戶。它的發布被稱為人工智慧的iPhone時刻,因為它幫助了許多人看到如何使用這項技術。
多模態的發展
基礎模型也擴展到處理和生成多種數據類型或模態,例如文本、圖像、音頻和視頻。視覺語言模型(VLMs)是一種多模態模型,可以理解視頻、圖像和文本輸入,同時生成文本或視覺輸出。
Cosmos Nemotron 34B是一個領先的VLM,訓練於355,000個視頻和2.8百萬個圖像,能夠查詢和總結來自物理或虛擬世界的圖像和視頻。
從文本到圖像
在ChatGPT首次亮相的同時,另一類神經網絡,稱為擴散模型,開始受到關注。它們將文本描述轉換為藝術圖像的能力吸引了許多用戶,創造出在社交媒體上迅速傳播的驚人圖像。
第一篇描述擴散模型的論文在2015年發表,當時並未引起太大關注。但像變壓器一樣,這一新技術很快引起了熱潮。
Midjourney的CEO大衛·霍茲(David Holz)在推特上透露,他的基於擴散的文本到圖像服務擁有超過440萬用戶。他在一次採訪中表示,為了服務這些用戶,需要超過10,000個NVIDIA GPU,主要用於AI推理(需要訂閱)。
朝向理解物理世界的模型
人工智慧的下一個前沿是物理AI,這使得自主機器如機器人和自駕車能夠與現實世界互動。
自主車輛或機器人的AI性能需要廣泛的訓練和測試。為了確保物理AI系統的安全,開發者需要在大量數據上進行訓練和測試,這可能是昂貴且耗時的。
世界基礎模型可以模擬現實環境,並根據文本、圖像或視頻輸入預測準確的結果,提供了一個有前景的解決方案。
物理AI開發團隊正在使用NVIDIA Cosmos世界基礎模型,這是一套在2000萬小時的駕駛和機器人數據上進行訓練的預訓練自回歸和擴散模型,配合NVIDIA Omniverse平台生成大量可控的基於物理的合成數據。Cosmos世界基礎模型在2025年CES上獲得了最佳AI和最佳整體獎項,這些開放模型可以根據下游用例進行定制,或使用特定任務的數據提高精度。
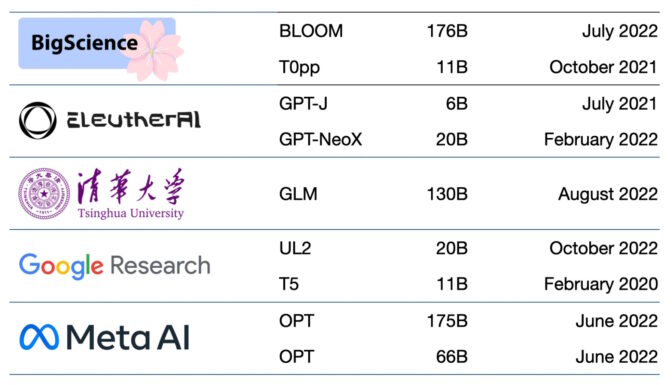
數十個模型在使用中
目前已有數百個基礎模型可用。一篇論文對超過50個主要變壓器模型進行了分類和列舉(見下圖)。
斯坦福團隊對30個基礎模型進行了基準測試,指出該領域發展迅速,他們未能評估一些新的和突出的模型。
初創公司NLP Cloud是NVIDIA Inception計劃的一部分,該計劃支持尖端初創企業,表示它在商業產品中使用了大約25個大型語言模型,服務於航空公司、藥房和其他用戶。專家預計,越來越多的模型將在Hugging Face的模型中心等網站上開放源碼。
基礎模型也在不斷變得更大和更複雜。
這就是為什麼許多企業已經在定制預訓練的基礎模型,以加速他們進入人工智慧的旅程,而不是從頭開始建立新的模型,使用像NVIDIA AI基礎模型這樣的在線服務。
生成式人工智慧的準確性和可靠性正在提高,這得益於檢索增強生成(retrieval-augmented generation,簡稱RAG)等技術,這使得基礎模型能夠訪問外部資源,如企業知識庫。
商業的AI基礎
另一個新框架NVIDIA NeMo框架旨在讓任何企業創建自己的十億或千億參數的變壓器,以支持自定義聊天機器人、個人助理和其他AI應用。
它創建了5300億參數的Megatron-Turing自然語言生成模型(MT-NLG),該模型為TJ,玩具詹森(Toy Jensen)虛擬形象提供了部分NVIDIA GTC去年的主題演講。
基礎模型——連接到像NVIDIA Omniverse這樣的3D平台——將是簡化元宇宙(metaverse)開發的關鍵,元宇宙是互聯網的3D演變。這些模型將為娛樂和工業用戶的應用和資產提供支持。
工廠和倉庫已經在數位雙胞胎(digital twins)中應用基礎模型,這是幫助尋找更高效工作方式的真實模擬。
基礎模型可以簡化訓練自主車輛和協助人類的機器人在工廠和物流中心的工作。它們還通過創建現實環境來幫助訓練自主車輛,如下圖所示。
基礎模型的新用途每天都在出現,應用它們的挑戰也在增加。
幾篇關於基礎和生成式AI模型的論文描述了風險,例如:
放大訓練模型所用的大型數據集中隱含的偏見,
在圖像或視頻中引入不準確或誤導性的信息,以及
侵犯現有作品的知識產權。
斯坦福的基礎模型論文指出:“考慮到未來的AI系統可能會高度依賴基礎模型,我們作為一個社區,必須共同努力制定更嚴格的基礎模型原則和負責任的開發和部署指導。”
當前的安全措施想法包括過濾提示及其輸出、即時重新校準模型和清理大型數據集。
NVIDIA的應用深度學習研究副總裁布萊恩·卡坦札羅(Bryan Catanzaro)表示:“這些是我們作為研究社區正在努力解決的問題。為了讓這些模型真正廣泛部署,我們必須在安全性上投入大量資源。”
這是人工智慧研究人員和開發者在創造未來時所耕耘的另一個領域。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}