


大型語言模型 (LLMs) 在數學、科學研究和軟體工程等複雜問題的解決上展現了高超的能力。思考鏈 (CoT) 提示在引導模型通過中間推理步驟達成結論中扮演了重要角色。強化學習 (RL) 是另一個關鍵組成部分,使模型能夠進行結構化推理,讓模型能有效識別和修正錯誤。儘管有這些進展,延長 CoT 的長度同時保持準確性仍然是一個挑戰,特別是在結構化推理至關重要的專業領域中。
提升 LLMs 推理能力的一個關鍵問題在於生成長且結構化的思考鏈。現有模型在需要迭代推理的高複雜度任務中表現不佳,例如博士級的科學問題解決和競賽數學。僅僅擴大模型的大小和訓練數據並不保證能改善 CoT 的能力。此外,基於 RL 的訓練需要精確的獎勵設計,因為不當的獎勵機制可能導致模型學習出反效果的行為。這項研究旨在識別影響 CoT 出現的基本因素,並設計最佳的訓練策略,以穩定和改善長鏈推理。
之前,研究人員已經採用監督微調 (SFT) 和強化學習來增強 LLMs 的 CoT 推理。SFT 通常用於用結構化推理範例初始化模型,而 RL 則用於微調和擴展推理能力。然而,傳統的 RL 方法在增加 CoT 長度時缺乏穩定性,經常導致推理質量不一致。可驗證的獎勵信號,例如真實準確性,對於防止模型進行獎勵駭客行為至關重要,這種行為是指模型學會優化獎勵而不是真正提升推理表現。儘管有這些努力,目前的訓練方法缺乏系統性的方法來有效擴展和穩定長 CoT。
來自卡內基梅隆大學 (Carnegie Mellon University) 和 IN.AI 的研究人員提出了一個綜合框架,以分析和優化 LLMs 中的長 CoT 推理。他們的研究重點在於確定長鏈推理的基本機制,並實驗各種訓練方法以評估其影響。團隊系統性地測試了 SFT 和 RL 技術,強調了結構化獎勵設計的重要性。他們開發了一種新穎的餘弦長度縮放獎勵,並加入重複懲罰,以鼓勵模型改進推理策略,例如分支和回溯,從而導致更有效的問題解決過程。此外,研究人員探索了將網路提取的解決方案作為可驗證的獎勵信號,以增強學習過程,特別是在 STEM 問題解決等分佈外 (OOD) 任務中。
這項訓練方法涉及對不同基礎模型的廣泛實驗,包括 Llama-3.1-8B 和 Qwen2.5-7B-Math,分別代表通用模型和數學專用模型。研究人員使用了來自 MATH 的 7,500 個訓練樣本提示數據集,以確保獲得可驗證的真實解決方案。最初的 SFT 訓練為長 CoT 的發展奠定了基礎,隨後進行了 RL 優化。團隊使用基於規則的驗證器,將生成的回應與正確答案進行比較,以確保學習過程的穩定性。他們引入了一種重複懲罰機制,以進一步完善獎勵設計,抑制模型產生冗餘推理路徑,同時激勵有效的問題解決。團隊還分析了從網路語料庫提取的數據,評估了噪音但多樣的監督信號在完善 CoT 長度縮放中的潛力。

研究結果揭示了長 CoT 推理的幾個關鍵見解。使用長 CoT SFT 訓練的模型在準確性上始終優於使用短 CoT SFT 初始化的模型。在 MATH-500 基準測試中,長 CoT SFT 模型的準確性顯著提高,超過 70%,而短 CoT SFT 模型則停滯在 55% 以下。RL 微調進一步增強了長 CoT 模型,提供了額外 3% 的絕對準確性增益。引入的餘弦長度縮放獎勵在穩定推理軌跡方面證明了其有效性,防止了過度或不結構化的 CoT 增長。此外,納入過濾的網路提取解決方案的模型在 OOD 基準測試中顯示出改進的泛化能力,例如 AIME 2024 和 TheoremQA,準確性增益達到 15-50%。研究還確認了核心推理技能,如錯誤驗證和修正,固有地存在於基礎模型中,但有效的 RL 訓練對於有效強化這些能力是必要的。
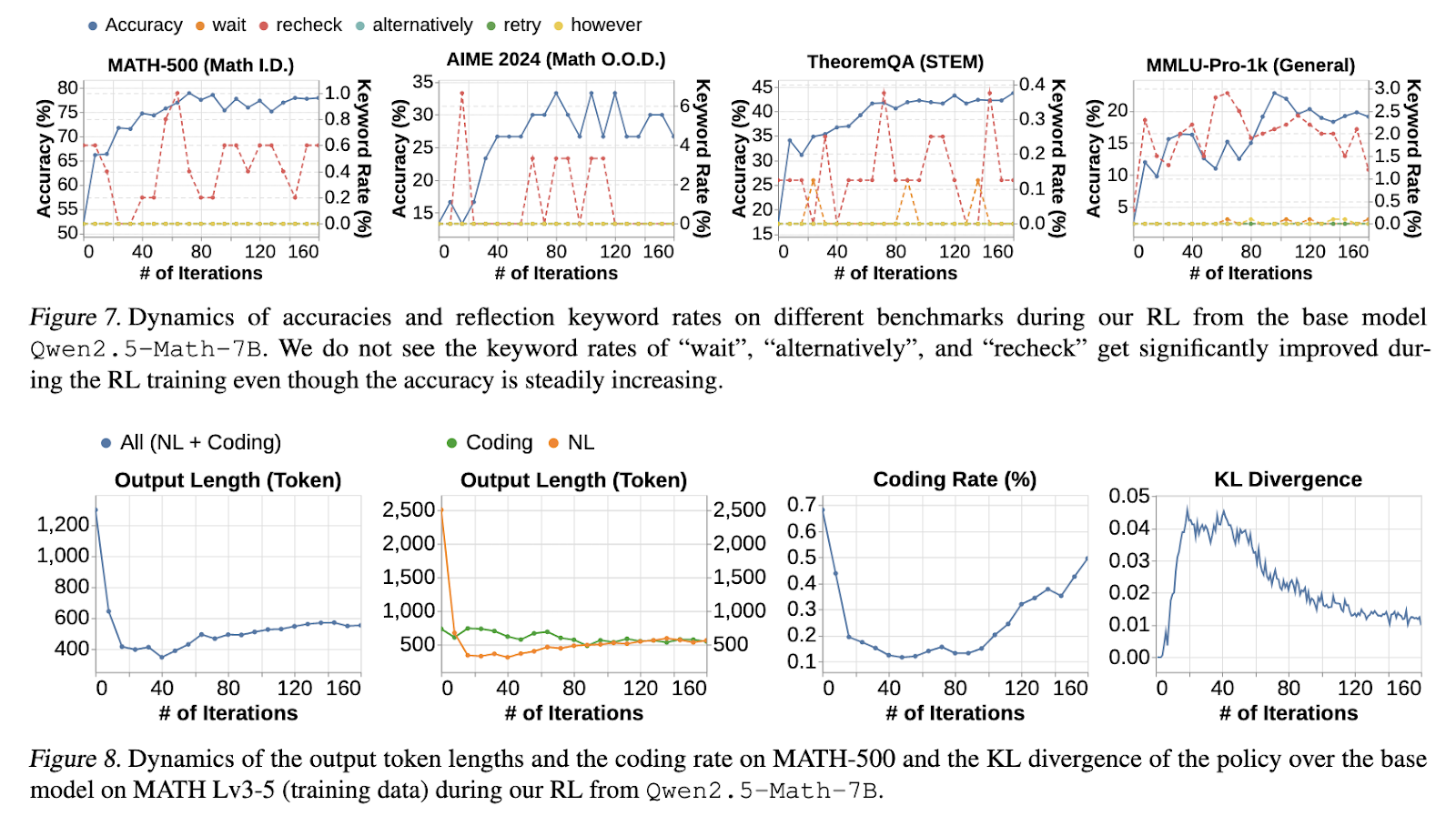
這項研究顯著推進了對 LLMs 中長 CoT 推理的理解和優化。研究人員成功識別了增強結構化推理的關鍵訓練因素,強調了監督微調、可驗證的獎勵信號和精心設計的強化學習技術的重要性。研究結果突顯了進一步研究的潛力,以完善 RL 方法,優化獎勵設計機制,並利用多樣的數據來源來增強模型的推理能力。這項研究的貢獻為未來開發具有強大、可解釋和可擴展推理能力的 AI 模型提供了寶貴的見解。
查看論文。所有對這項研究的讚譽都歸功於這個項目的研究人員。此外,別忘了在 Twitter 上關注我們,並加入我們的 Telegram 頻道和 LinkedIn 群組。也別忘了加入我們的 75k+ ML SubReddit。
🚨 推薦的開源 AI 平台:‘IntellAgent 是一個開源的多代理框架,用於評估複雜的對話 AI 系統’ (推廣)
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}