
:增強大型語言模型推理的AI框架")

大型語言模型(LLMs)已經徹底改變了人工智慧,展現出在文本生成和問題解決方面的卓越能力。然而,它們在默認的「快速思考」方法上仍然存在一個重要的限制——根據單一查詢生成輸出,而不進行反覆的修正。雖然最近的「慢思考」方法,如思路鏈提示(chain-of-thought prompting),將問題分解為更小的步驟,但它們仍然受到靜態初始知識的限制,無法在推理過程中動態整合新信息。在需要即時知識更新的複雜任務中,例如多跳問題回答或自適應代碼生成,這一差距變得更加明顯。
目前提升LLM推理能力的方法主要分為兩類。檢索增強生成(RAG)系統預先加載外部知識,但常常引入無關信息,影響效率和準確性。基於樹的搜索算法,如蒙特卡羅樹搜索(Monte Carlo Tree Search, MCTS),能夠結構化地探索推理路徑,但缺乏整合上下文知識的機制。例如,雖然LATS(基於LLM的MCTS)引入了評估和反思階段,但仍然在模型的初始知識邊界內運作。這些方法在平衡探索廣度、上下文相關性和計算效率方面面臨挑戰,常常產生過於廣泛或信息不足的回答。
在這篇論文中,來自奇虎360(Qihoo 360)數位安全小組的研究團隊提出了聯想思維鏈(Chain-of-Associated-Thoughts, CoAT)框架,以解決這些限制,並引入了兩個關鍵創新。首先,聯想記憶機制使得在推理過程中能夠動態整合知識,模仿人類的認知聯想。與靜態的RAG方法不同,CoAT在特定推理步驟中激活知識檢索——就像數學家在證明中只在需要時回憶相關定理一樣。其次,優化的MCTS算法通過一個新穎的四階段循環來整合這一聯想過程:選擇、與知識聯想的擴展、質量評估和價值反向傳播。這創造了一個反饋循環,使每個推理步驟都能觸發針對性的知識更新,如原始實現的圖4所示。
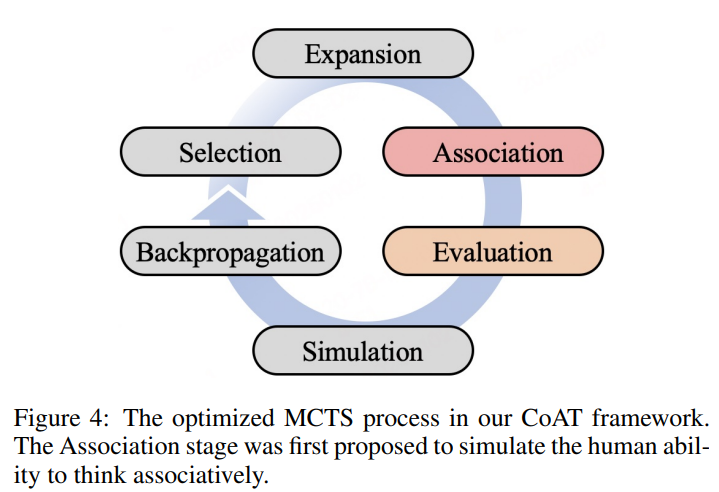
CoAT的核心是一種雙流推理架構。在處理查詢時,系統同時通過MCTS樹探索可能的推理路徑,同時維持一個聯想記憶庫。搜索樹中的每個節點(代表一個推理步驟)生成內容(G(n))、相關知識(AM(n)),並為答案質量(Fg)和知識相關性(Fa)分配分數,β控制它們的相對重要性。這確保了聯想與不斷演變的推理過程緊密相連,而不會引入無關的信息。
CoAT的性能評估顯示其優於現有的推理增強技術。該框架在各種任務中進行了質量和數量的基準測試。質量評估涉及複雜的查詢回答,CoAT展示了比基準模型(如Qwen2.5-32B和ChatGPT)更豐富和全面的回答。值得注意的是,它引入了其他推理類別,如倫理和法規考量,而這在其他模型中是缺失的。數量評估主要在兩個領域進行:知識密集型問題回答和代碼生成。在檢索增強生成(RAG)任務中,CoAT與NativeRAG、IRCoT、HippoRAG、LATS和KAG在HotpotQA和2WikiMultiHopQA數據集上進行了比較。精確匹配(Exact Match, EM)和F1分數等指標確認了CoAT的優越性能,展示了其生成精確且上下文相關的回答的能力。在代碼生成中,CoAT增強的模型在HumanEval、MBPP和HumanEval-X等數據集上超越了微調的對應模型(Qwen2.5-Coder-7B-Instruct、Qwen2.5-Coder-14B-Instruct),突顯了其對特定領域推理任務的適應性。
這項工作為LLM推理建立了一種新範式,通過整合動態知識聯想與結構化搜索。與之前的靜態增強方法不同,CoAT的即時記憶更新使得上下文感知的推理能夠適應新出現的信息需求。MCTS優化和雙內容評估的技術創新為將外部知識系統與現代LLM結合提供了一個藍圖。雖然目前的實現依賴於預定義的外部知識,但該架構自然支持與新興工具(如LLM代理和即時網頁搜索)的即插即用整合。這些進展表明,人工智慧推理的下一個前沿可能在於動態交織內部計算與針對性外部知識檢索的系統——就像人類專家在複雜問題解決過程中查閱參考資料一樣。
查看論文。這項研究的所有功勞都歸功於這個項目的研究人員。此外,別忘了在Twitter上關注我們,加入我們的Telegram頻道和LinkedIn小組。還有,記得加入我們的75k+機器學習SubReddit。
🚨 推薦的開源人工智慧平台:「IntellAgent是一個開源的多代理框架,用於評估複雜的對話人工智慧系統」(推廣)
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}