
:一種增強大型語言模型多樣性的創新優化方法")

大型語言模型(LLMs)在人工智慧領域取得了很大的進展,並被廣泛應用在許多不同的地方。雖然它們幾乎可以完美模擬人類語言,但在回應的多樣性上卻有些不足。這個限制在需要創造力的任務中尤其明顯,例如生成合成數據和講故事,這些任務需要多樣的輸出來保持相關性和吸引力。
優化語言模型的一個主要挑戰是,由於偏好訓練技術,回應的多樣性降低。像是從人類反饋中進行強化學習(RLHF)和直接偏好優化(DPO)等後訓練方法,往往會將概率集中在少數幾個高獎勵的回應上。這導致模型對不同的提示生成重複的輸出,限制了它們在創意應用中的適應性。多樣性的下降妨礙了語言模型在需要廣泛輸出的領域中有效運作的潛力。
過去的偏好優化方法主要強調將模型與高品質的人類偏好對齊。監督式微調和RLHF技術雖然有效改善模型的對齊,但無意中導致了回應的同質化。直接偏好優化(DPO)選擇高獎勵的回應,同時丟棄低品質的回應,這加強了模型生成可預測輸出的傾向。為了應對這個問題,調整取樣溫度或應用KL散度正則化等方法未能在不影響輸出質量的情況下顯著提高多樣性。
來自Meta、紐約大學和蘇黎世聯邦理工學院的研究人員提出了一種新技術,稱為多樣性偏好優化(DivPO),旨在提高回應的多樣性,同時保持高品質。與傳統的優化方法不同,DivPO根據質量和多樣性選擇偏好對。這確保模型生成的輸出不僅與人類對齊,還具有多樣性,使其在創意和數據驅動的應用中更有效。

DivPO的運作方式是針對給定的提示取樣多個回應,並使用獎勵模型對它們進行評分。它不僅選擇單一的最高獎勵回應,而是選擇最具多樣性和高品質的回應作為首選輸出。同時,選擇不符合質量標準的最少變化回應作為被拒絕的輸出。這種對比優化策略使DivPO能夠學習更廣泛的回應分佈,同時確保每個輸出都保持高品質標準。該方法系統性地評估每個回應的獨特性,考慮了多種多樣性標準,包括模型概率、單詞頻率和基於LLM的多樣性判斷。
進行了大量實驗來驗證DivPO的有效性,重點放在結構化角色生成和開放式創意寫作任務上。結果顯示,DivPO顯著提高了多樣性,而不犧牲質量。與標準的偏好優化方法相比,DivPO使角色屬性多樣性增加了45.6%,故事多樣性提高了74.6%。實驗還顯示,DivPO防止模型生成少數回應的情況,確保生成屬性的分佈更均勻。一個重要的觀察是,使用DivPO訓練的模型在多樣性評估中始終超過基準模型,同時保持高質量,這是由ArmoRM獎勵模型評估的。
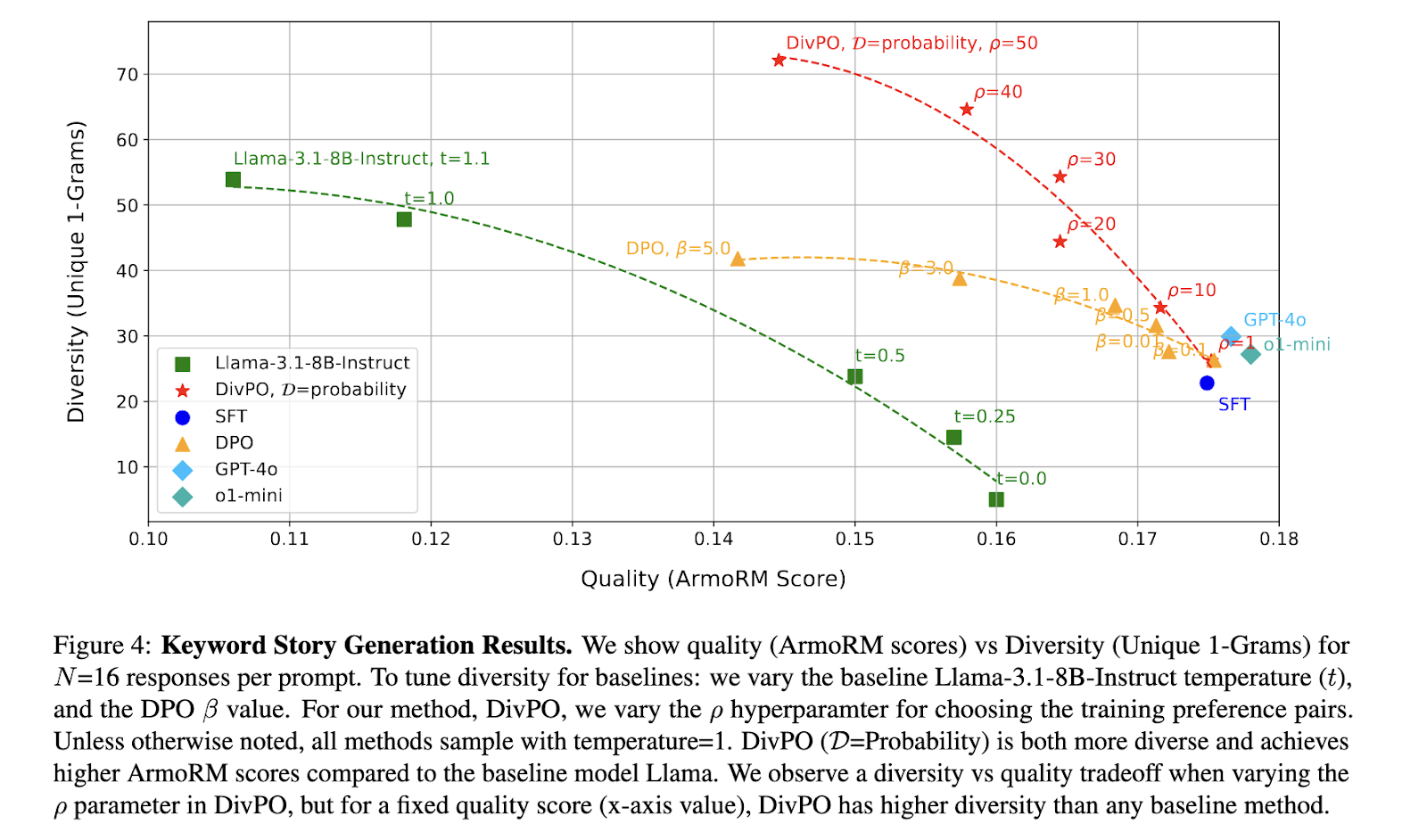
對角色生成的進一步分析顯示,傳統的微調模型,例如Llama-3.1-8B-Instruct,未能生成多樣的角色屬性,經常重複有限的名字。DivPO通過擴大生成的屬性範圍來解決這個問題,導致更平衡和具代表性的輸出分佈。結構化角色生成任務顯示,使用字詞頻率標準的在線DivPO相比基準模型提高了30.07%的多樣性,同時保持了相似的回應質量。類似地,基於關鍵字的創意寫作任務顯示出顯著的改進,DivPO在多樣性上提高了13.6%,在質量上提高了39.6%,相對於標準的偏好優化模型。
這些發現證實了偏好優化方法本質上會降低多樣性,這對於設計用於開放式任務的語言模型來說是一個挑戰。DivPO通過引入多樣性意識的選擇標準,有效地緩解了這個問題,使語言模型能夠保持高品質的回應而不限制變異性。通過平衡多樣性和對齊,DivPO增強了LLMs在多個領域的適應性和實用性,確保它們在創意、分析和合成數據生成應用中仍然有用。DivPO的引入標誌著偏好優化的一個重要進展,為語言模型中長期存在的回應崩潰問題提供了一個實用的解決方案。
查看論文。所有的研究成果都歸功於這個項目的研究人員。此外,別忘了在Twitter上關注我們,並加入我們的Telegram頻道和LinkedIn小組。也別忘了加入我們的75k+ ML SubReddit。
🚨 Marktechpost邀請AI公司/初創企業/團體合作,參加即將推出的AI雜誌,主題為「開源AI在生產中的應用」和「代理AI」。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}