
")

編輯備註:這篇文章最初於2023年11月15日發布,現已更新。
要了解生成式人工智慧的最新進展,想像一下法庭的場景。
法官根據對法律的一般理解來聽取和裁決案件。有時候,一些案件,例如醫療疏失訴訟或勞動爭議,則需要特別的專業知識,因此法官會派法庭書記去法律圖書館,尋找可以引用的先例和具體案例。
像一位優秀的法官,大型語言模型 (LLMs) 能夠回答各種人類的問題。但為了提供權威的答案——這些答案基於具體的法庭程序或類似的案例——模型需要提供這些信息。
人工智慧的法庭書記是一個叫做檢索增強生成 (Retrieval-Augmented Generation, RAG) 的過程。
為什麼叫做「RAG」
2020年提出這個術語的主要作者帕特里克·劉易斯 (Patrick Lewis) 為這個不太好聽的縮寫感到抱歉,這個縮寫現在描述了一系列在數百篇論文和數十個商業服務中使用的方法,他相信這些方法代表了生成式人工智慧的未來。
劉易斯在新加坡的一次訪談中表示:「如果我們知道我們的工作會變得如此普遍,我們肯定會對這個名字多花點心思。」
他說:「我們一直計劃要有一個聽起來更好的名字,但當寫論文的時候,沒有人有更好的主意。」劉易斯現在在人工智慧初創公司 Cohere 領導一個 RAG 團隊。
那麼,什麼是檢索增強生成 (RAG)?
檢索增強生成是一種技術,用於通過從特定和相關的數據來源獲取信息來提高生成式人工智慧模型的準確性和可靠性。
換句話說,它填補了大型語言模型 (LLMs) 工作中的一個空白。在內部,LLMs 是神經網絡,通常根據它們包含的參數數量來衡量。LLM 的參數基本上代表了人類使用單詞形成句子的普遍模式。
這種深刻的理解,有時稱為參數化知識,使 LLMs 在回答一般提示時非常有用。然而,這並不適合那些想要深入了解特定類型信息的用戶。
結合內部和外部資源
劉易斯和他的同事們開發了檢索增強生成,以將生成式人工智慧服務與外部資源連接起來,特別是那些包含最新技術細節的資源。
這篇論文的共同作者來自前 Facebook 人工智慧研究所(現在是 Meta AI)、倫敦大學學院和紐約大學,將 RAG 稱為「通用的微調配方」,因為幾乎任何 LLM 都可以使用它來連接幾乎任何外部資源。
建立用戶信任
檢索增強生成為模型提供了可以引用的來源,就像研究論文中的註腳一樣,這樣用戶就可以檢查任何聲明。這樣可以建立信任。
此外,這項技術還可以幫助模型澄清用戶查詢中的模糊性。它還減少了模型給出非常合理但不正確答案的可能性,這種現象被稱為幻覺。
RAG 的另一個優勢是相對簡單。劉易斯和三位共同作者在一篇博客中表示,開發人員只需五行代碼就可以實現這個過程。
這使得這種方法比使用額外數據集重新訓練模型更快且成本更低。而且,它允許用戶隨時熱插拔新的資源。
人們如何使用 RAG
通過檢索增強生成,用戶基本上可以與數據庫進行對話,開啟新的體驗。這意味著 RAG 的應用可能是可用數據集數量的多倍。
例如,補充醫療索引的生成式人工智慧模型可以成為醫生或護士的好助手。金融分析師則可以受益於與市場數據相連的助手。
事實上,幾乎任何企業都可以將其技術或政策手冊、視頻或日誌轉換為稱為知識庫的資源,這些資源可以增強 LLMs。這些來源可以支持客戶或現場支持、員工培訓和開發者生產力等用例。
這種廣泛的潛力是為什麼包括 AWS、IBM、Glean、Google、Microsoft、NVIDIA、Oracle 和 Pinecone 等公司正在採用 RAG。
開始使用檢索增強生成
NVIDIA 的 RAG 人工智慧藍圖幫助開發人員建立管道,將其人工智慧應用程序連接到企業數據,使用行業領先的技術。這個參考架構為開發人員提供了建立可擴展和可定制的檢索管道的基礎,這些管道能夠提供高準確性和高吞吐量。
這個藍圖可以直接使用,或與其他 NVIDIA 藍圖結合,用於包括數位人類和人工智慧助手在內的高級用例。例如,人工智慧助手的藍圖使組織能夠構建可以快速擴展其客戶服務操作的人工智慧代理,結合生成式人工智慧和 RAG。
此外,開發人員和 IT 團隊可以嘗試免費的 NVIDIA LaunchPad 實驗室,該實驗室用於構建帶有 RAG 的人工智慧聊天機器人,能夠從企業數據中提供快速和準確的響應。
所有這些資源都使用 NVIDIA NeMo Retriever,這提供了領先的大規模檢索準確性,以及 NVIDIA NIM 微服務,簡化了在雲端、數據中心和工作站之間的安全、高性能人工智慧部署。這些都是 NVIDIA 人工智慧企業軟體平台的一部分,用於加速人工智慧的開發和部署。
要獲得 RAG 工作流程的最佳性能,需要大量的內存和計算能力來移動和處理數據。NVIDIA GH200 Grace Hopper 超級芯片擁有 288GB 的快速 HBM3e 內存和 8 petaflops 的計算能力,非常理想——它可以提供比使用 CPU 快 150 倍的速度。
一旦公司熟悉了 RAG,他們可以將各種現成或自定義的 LLM 與內部或外部知識庫結合,創建各種助手來幫助他們的員工和客戶。
RAG 不需要數據中心。得益於 NVIDIA 軟體,LLMs 現在可以在 Windows PC 上運行,這使得用戶即使在筆記本電腦上也能訪問各種應用程序。
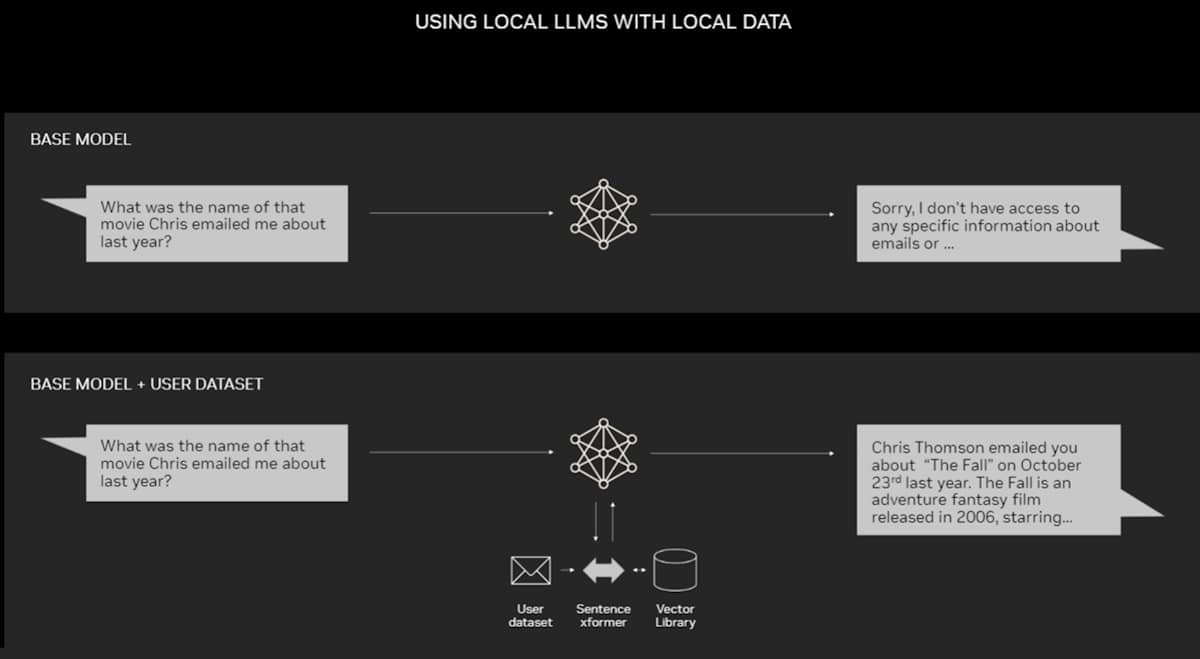
配備 NVIDIA RTX GPU 的 PC 現在可以在本地運行一些人工智慧模型。通過在 PC 上使用 RAG,用戶可以鏈接到私有知識來源——無論是電子郵件、筆記還是文章——以改善響應。用戶可以放心,他們的數據來源、提示和響應都保持私密和安全。
最近的一篇博客提供了使用 TensorRT-LLM 加速 RAG 的示例,以快速獲得更好的結果。
RAG 的歷史
這項技術的根源可以追溯到1970年代初期。當時,信息檢索的研究人員原型化了他們所稱的問答系統,這些應用程序使用自然語言處理 (NLP) 來訪問文本,最初集中在狹窄的主題上,例如棒球。
這種文本挖掘背後的概念多年來保持相對穩定。但驅動它們的機器學習引擎已經顯著增長,提高了它們的實用性和受歡迎程度。
在1990年代中期,Ask Jeeves 服務(現在的 Ask.com)以其穿著得體的侍者吉祥物普及了問答功能。IBM 的 Watson 在2011年成為電視名人,因為它在《危險邊緣!》遊戲節目中輕鬆擊敗了兩位人類冠軍。
如今,LLMs 正在將問答系統提升到全新的水平。
來自倫敦實驗室的見解
這篇具有開創性的2020年論文出現在劉易斯在倫敦大學學院攻讀 NLP 博士學位的時候,並且在 Meta 的一個新的倫敦人工智慧實驗室工作。團隊正在尋找將更多知識打包進 LLM 參數的方法,並使用他們開發的基準來衡量進展。
基於早期的方法,並受到 Google 研究人員的一篇論文的啟發,該小組「有這種令人信服的願景,想要建立一個中間有檢索索引的訓練系統,這樣它就可以學習並生成你想要的任何文本輸出。」劉易斯回憶道。

當劉易斯將另一個 Meta 團隊的有前景的檢索系統接入進行中的工作時,第一個結果出乎意料地令人印象深刻。
他說:「我向我的主管展示,他說,‘哇,抓住這次勝利。這種事情並不常發生,因為這些工作流程第一次設置正確可能很困難。’」
劉易斯還感謝了來自紐約大學和 Facebook 人工智慧研究所的團隊成員伊桑·佩雷斯 (Ethan Perez) 和杜維·基拉 (Douwe Kiela) 的重要貢獻。
當工作完成時,這項在 NVIDIA GPU 集群上運行的工作展示了如何使生成式人工智慧模型更具權威性和可信度。此後,這項工作被數百篇論文引用,擴展了這些概念,並持續成為一個活躍的研究領域。
檢索增強生成的運作方式
在高層次上,檢索增強生成的運作方式如下。
當用戶向 LLM 提出問題時,人工智慧模型會將查詢發送到另一個模型,該模型將其轉換為數字格式,以便機器可以讀取。查詢的數字版本有時稱為嵌入 (embedding) 或向量 (vector)。
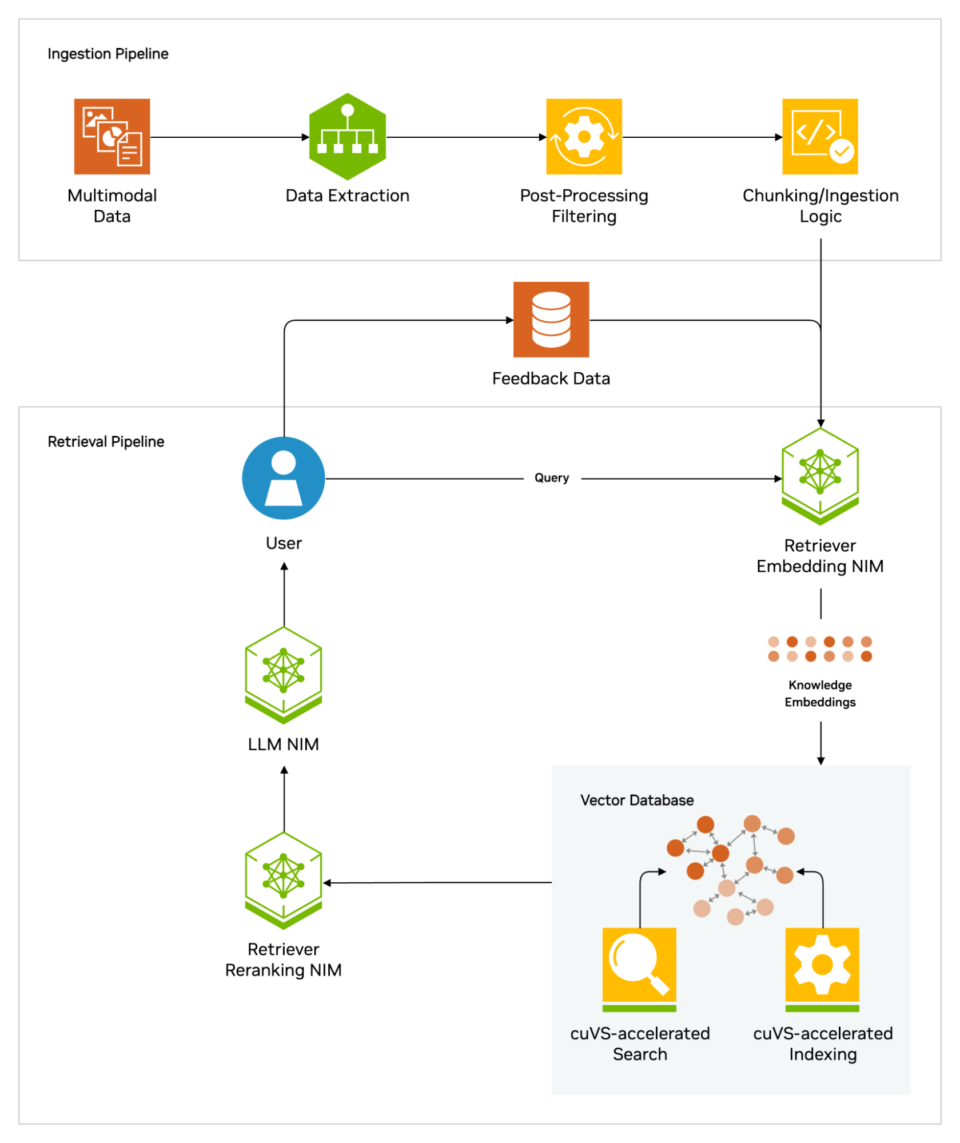
然後,嵌入模型將這些數值與可用知識庫中的機器可讀索引中的向量進行比較。當它找到匹配或多個匹配時,它檢索相關數據,將其轉換為人類可讀的文字,並將其傳回給 LLM。
最後,LLM 將檢索到的文字與其對查詢的回應結合,形成最終答案,並可能引用嵌入模型找到的來源。
保持來源的最新性
在背景中,嵌入模型不斷創建和更新機器可讀索引,有時稱為向量數據庫,隨著新和更新的知識庫的出現。
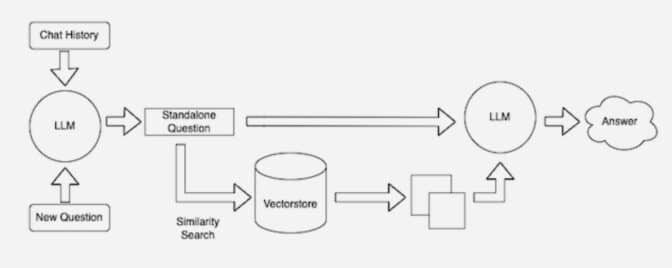
許多開發人員發現,LangChain 這個開源庫在將 LLM、嵌入模型和知識庫鏈接在一起時特別有用。NVIDIA 在其檢索增強生成的參考架構中使用 LangChain。
LangChain 社區提供了對 RAG 過程的描述。
生成式人工智慧的未來在於代理人工智慧——在這種情況下,LLMs 和知識庫被動態協調,以創建自主助手。這些由人工智慧驅動的代理可以增強決策能力,適應複雜任務,並為用戶提供權威且可驗證的結果。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}