


現代的人工智慧(AI)系統在訓練後,常常依賴一些技術來調整基礎模型,以適應特定的任務,這些技術包括監督式微調(SFT)和強化學習(RL)。不過,有一個重要的問題尚未解決:這些方法是否幫助模型記住訓練數據,還是能夠適應新的情境?這個區別對於建立能夠應對現實世界變化的穩健AI系統非常重要。
之前的研究表明,SFT可能會導致模型過度擬合訓練數據,使其在面對新的任務變體時變得脆弱。例如,一個經過SFT調整的模型可能在使用特定牌值的算術問題上表現良好(例如,將‘J’視為11),但如果規則改變(例如,‘J’變成10),它就會失敗。同樣,RL依賴獎勵信號,可能會鼓勵靈活的問題解決方式,或強化狹隘的策略。然而,現有的評估常常混淆記憶和真正的概括能力,讓實踐者不確定應該優先考慮哪種方法。在香港大學(HKU)、加州大學伯克利分校(UC Berkeley)、谷歌深度學習(Google DeepMind)和紐約大學(NYU)的一篇最新論文中,研究人員比較了SFT和RL如何影響模型適應未見的基於規則和視覺挑戰的能力。
他們提出在控制環境中測試概括能力,以將記憶與概括區分開來。研究人員設計了兩個任務:GeneralPoints(算術推理)和V-IRL(視覺導航)。這兩個任務都包括分佈內(ID)訓練數據和分佈外(OOD)變體,以測試適應能力:
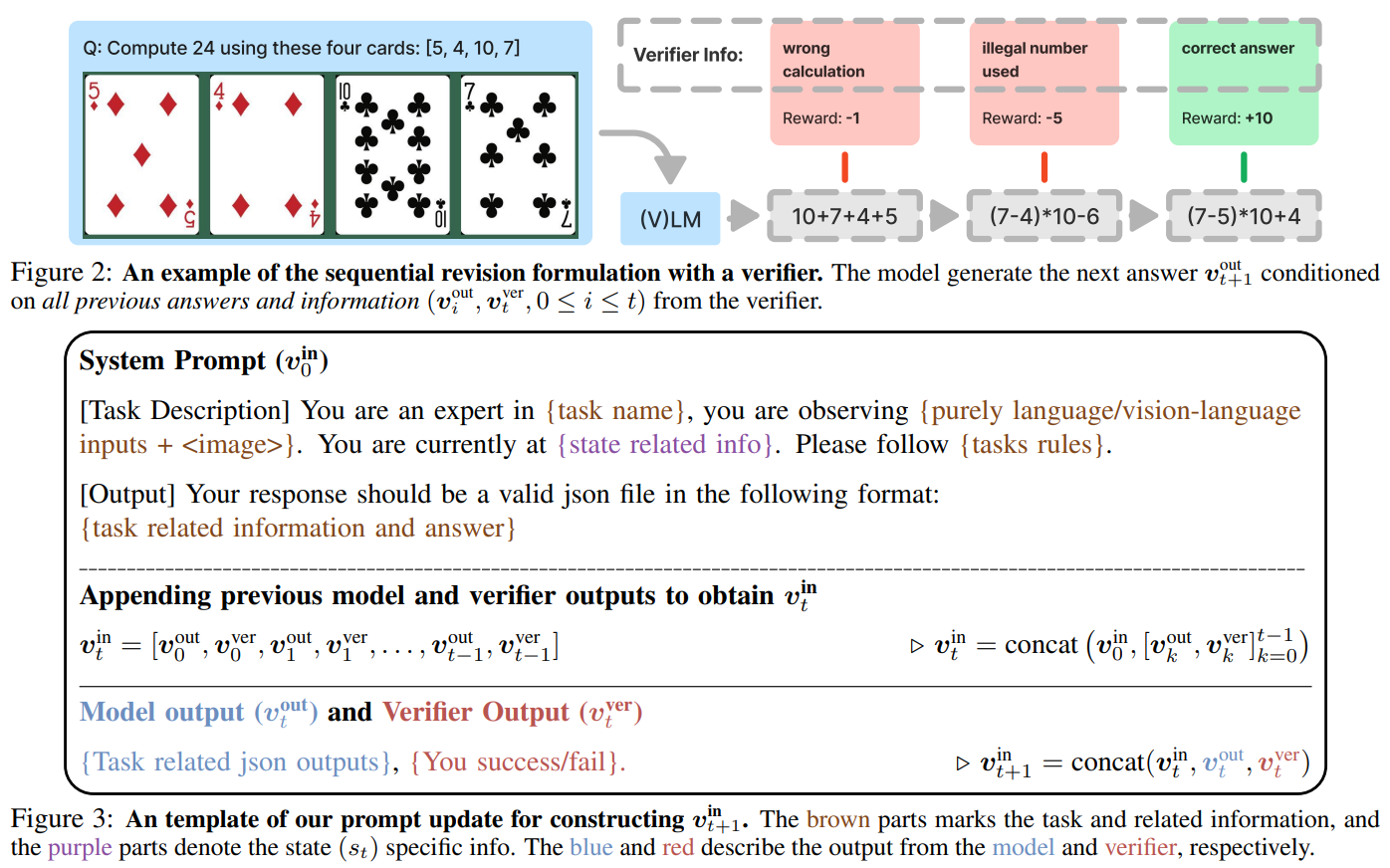
基於規則的概括(GeneralPoints,如圖3所示):
任務:使用四個數字創建等於24的方程式,數字來自撲克牌。
變體:改變牌值規則(例如,‘J’ = 11 vs. ‘J’ = 10)或牌的顏色(紅色 vs. 藍色)。
目標:確定模型是否學習算術原則或記住特定規則。
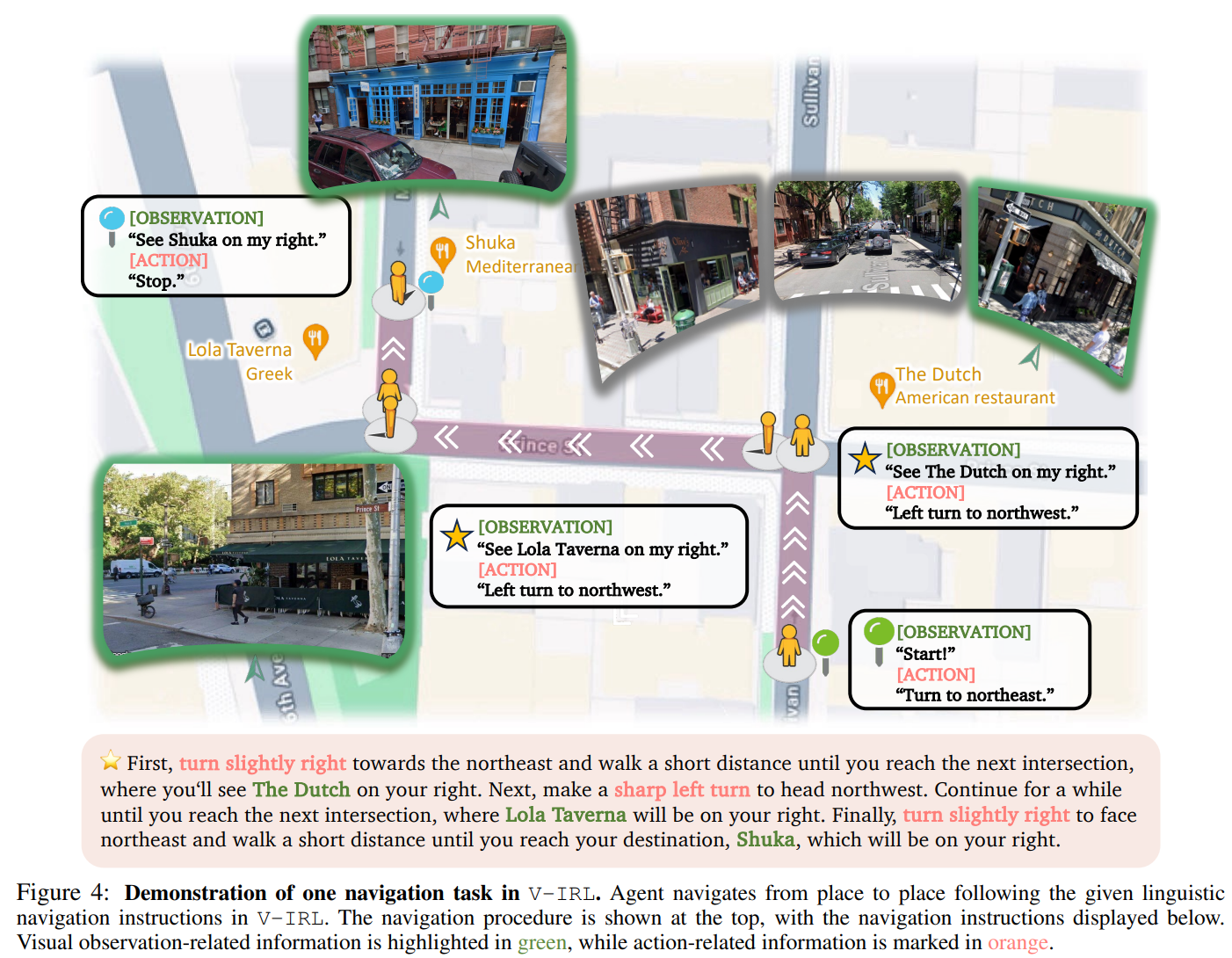
視覺概括(V-IRL,如圖4所示):
任務:使用視覺地標導航到目標位置。
變體:切換行動空間(絕對方向如“北” vs. 相對指令如“左轉”)或在未見過的城市中測試。
目標:評估空間推理能力,獨立於記憶的地標。
在實驗中,這項研究使用Llama-3.2-Vision-11B作為基礎模型,首先應用SFT(標準做法),然後進行RL。關鍵實驗測量在每個訓練階段後,模型在OOD任務上的表現。現在讓我們討論一些論文中的重要見解:
SFT和RL在學習機制上有何不同?
SFT的記憶偏差:SFT訓練模型複製標記數據中的正確回應。雖然這對於ID任務有效,但這種方法鼓勵模式匹配。例如,如果在GeneralPoints中訓練紅牌,模型會將顏色與特定數字分配聯繫起來。當在藍牌上測試時(OOD),性能會大幅下降,因為它記住了顏色和數字的關聯,而不是算術邏輯。同樣,在V-IRL中,SFT模型記住地標序列,但在新的城市佈局中卻表現不佳。
RL的概括能力:RL優化獎勵最大化,這迫使模型理解任務結構。在GeneralPoints中,經過RL訓練的模型通過關注算術關係來適應新的牌規,而不是固定的值。在V-IRL中,RL代理學習空間關係(例如,“左轉”意味著旋轉90度),而不是記住轉向序列。這使它們對視覺變化(例如不熟悉的地標)具有韌性。
另一個重要的見解是,RL受益於驗證迭代——在單一訓練步驟中多次嘗試解決任務。更多的迭代(例如,10次 vs. 1次)使模型能夠探索多樣的策略,在某些情況下提高OOD性能達+5.99%。
在性能評估中,RL在兩個任務中始終優於SFT,如圖5和6所示:
基於規則的任務:
RL提高了OOD準確率+3.5%(GP-L)和+11.0%(V-IRL-L),而SFT則分別下降-8.1%和-79.5%。
例如:當牌規從‘J=11’改為‘J=10’時,RL模型使用新值調整方程,而SFT模型則重複使用無效的記憶解法。
視覺任務:
RL提升了OOD性能+17.6%(GP-VL)和+61.1%(V-IRL-VL),而SFT則下降-9.9%和-5.6%。
在V-IRL中,RL代理通過識別空間模式導航未見過的城市,而SFT因依賴記憶地標而失敗。
這項研究還表明,SFT對於初始化模型以進行RL是必要的。沒有SFT,RL會遇到困難,因為基礎模型缺乏基本的指令跟隨能力。然而,過度調整的SFT檢查點會損害RL的適應能力,RL在過度SFT後無法恢復OOD性能。然而,研究人員澄清,他們的發現——特定於Llama-3.2基礎模型——與早期的研究(如DeepSeekAI等,2025年)並不矛盾,後者提出在使用替代基礎架構時,可以省略SFT以進行下游RL訓練。
總結來說,這項研究顯示出明確的權衡:SFT擅長擬合訓練數據,但在分佈變化下表現不佳,而RL則優先考慮可適應的、可概括的策略。對於實踐者來說,這意味著RL應該在SFT之後進行,但僅限於模型達到基本任務能力之前。過度依賴SFT可能會“鎖定”記憶模式,限制RL探索新解決方案的能力。然而,RL也不是萬能的;它需要仔細調整(例如,驗證步驟)和均衡的初始化。
查看這篇論文。這項研究的所有功勞都歸於這個項目的研究人員。此外,別忘了在Twitter上關注我們,加入我們的Telegram頻道和LinkedIn小組。還有,別忘了加入我們的70k+機器學習SubReddit。
🚨 介紹IntellAgent:一個開源的多代理框架,用於評估複雜的對話AI系統(推廣)
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}