


知識追蹤 (Knowledge Tracing, KT) 在智慧輔導系統 (Intelligent Tutoring Systems, ITS) 中扮演著重要的角色,透過模擬學生的知識狀態並預測他們未來的表現。傳統的知識追蹤模型,例如貝葉斯知識追蹤 (Bayesian Knowledge Tracing, BKT) 和早期的深度學習模型如深度知識追蹤 (Deep Knowledge Tracing, DKT),已經證明在學習學生互動方面是有效的。然而,最近深度序列知識追蹤模型的進展,例如注意力知識追蹤 (Attentive Knowledge Tracing, AKT),越來越重視預測表現,而非實用性和全面的知識建模。這些模型常常面臨基本挑戰,包括有限的平行計算效率、修改儲存知識的困難,以及儲存容量的限制。此外,許多深度知識追蹤模型依賴未來的互動,而這在現實應用中通常無法獲得,限制了它們的可用性。解決這些挑戰對於提升知識追蹤模型在大型教育系統中的可擴展性、可解釋性和有效性至關重要。
現有的知識追蹤模型利用基於深度學習的架構來預測學生的表現,例如 DKT 利用長短期記憶 (Long Short-Term Memory, LSTM) 網絡來學習學習的動態。雖然基於注意力的模型如 AKB 使用注意力機制來改善長期依賴性,但它們需要未來的反應作為輸入,這使得它們在現實場景中無法應用。深度序列模型也面臨平行化和記憶問題,這降低了它們在處理大型數據集時的效率。其他方法,包括基於圖的和增強記憶的模型,通常不具可解釋性,這意味著它們無法提供有用的見解來了解學生的學習過程。這些不足之處造成了理論突破與實際應用之間的差距,迫切需要一個更具可擴展性、可解釋性和高效的知識追蹤模型。
來自浙江大學的研究人員提出了 DKT2,一種新型的基於深度學習的知識追蹤框架,利用 xLSTM 架構來克服之前方法的限制。DKT2 與早期模型的不同之處在於它使用 Rasch 模型來改善輸入表示,並結合項目反應理論 (Item Response Theory, IRT) 以增強可解釋性。透過識別熟悉和不熟悉的知識,DKT2 提供了更好的學生學習狀態表示。xLSTM 的使用解決了經典 LSTM 的限制,通過可修訂的儲存決策、增加的記憶容量和完全的平行化,實現了更大的可擴展性和效率。這項創新使得模型在提供比其對手更好的預測準確性時,仍能保持強大的應用性。
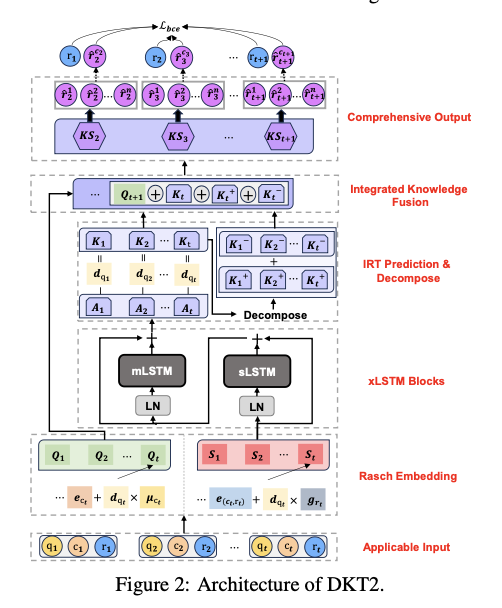
DKT2 採用系統化的學習流程,使用 Rasch 嵌入來記錄學生與問題的互動,並包括難度等級以改善輸入表示。xLSTM 區塊使用 sLSTM 和 mLSTM 來促進更好的記憶保留、平行化優化和動態知識更新。IRT 預測和知識分解模組將熟悉和不熟悉的知識分開,以實現更具可解釋性的知識追蹤。整合知識融合將歷史知識狀態和預測問題融合,創建學生學習進度的全面概覽。該模型使用二元交叉熵損失進行訓練,並在三個大型數據集上進行評估——Assist17、EdNet 和 Comp,確保在現實 ITS 應用中的穩健性。
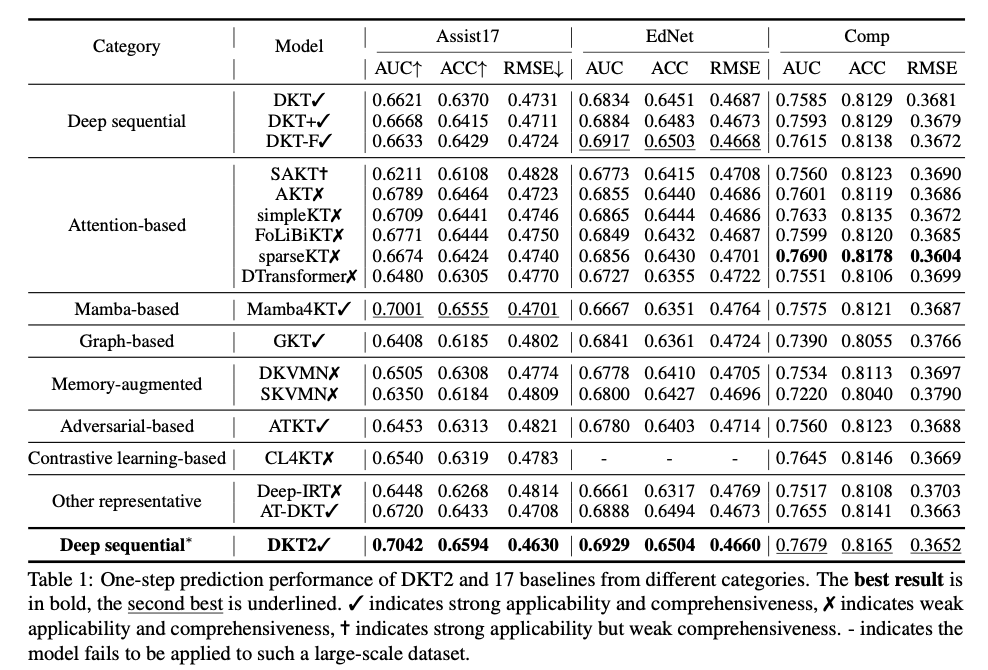
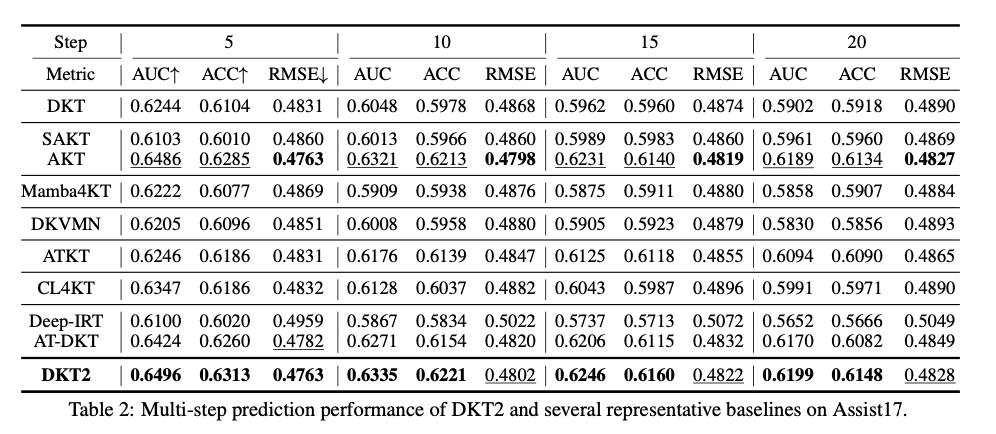
在三個大型數據集上的廣泛實驗顯示,DKT2 在多個預測任務中始終超越 17 個基準模型,包括一步、跨步和變歷史長度的預測。與深度序列模型如 DKT 和基於注意力的模型如 AKT 相比,它實現了更高的準確性、AUC 和更低的 RMSE。xLSTM 的整合增強了平行化和記憶容量,減少了多步預測中的錯誤累積,而 Rasch 模型和 IRT 通過有效區分熟悉和不熟悉的知識來提高可解釋性。消融研究確認 DK2 的每個組件對其卓越性能的貢獻,特別是 mLSTM,這對於大型數據集的可擴展性至關重要。這些結果確立了 DKT2 作為現實智慧輔導系統的穩健和可應用解決方案。
DKT2 是知識追蹤的一項突破,通過結合 xLSTM、Rasch 模型和 IRT,實現了預測準確性與現實可用性之間的完美平衡。透過可解釋的知識狀態生成和平行化、節省記憶的學習方法,該方法保證了在 ITS 應用中的可擴展性和改善的個性化。未來的工作方向包括擴展 DKT2 在超大型數據集上的應用性,以及改善其多概念預測能力,以更好地支持自適應學習系統。
查看論文。所有的研究功勞都歸於這個項目的研究人員。此外,別忘了在 Twitter 上關注我們,加入我們的 Telegram 頻道和 LinkedIn 群組。還有,別忘了加入我們的 70k+ 機器學習 SubReddit。
🚨 介紹 IntellAgent:一個開源的多代理框架,用於評估複雜的對話式人工智慧系統 (Promoted)
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}