
:一種旨在提升大型語言模型(LLMs)效率的新穎後訓練量化方法")

後訓練量化(Post-training quantization, PTQ)專注於減少大型語言模型(Large Language Models, LLMs)的大小並提高速度,讓它們在現實世界中更實用。這些模型需要大量數據,但在量化過程中,數據分佈的極度偏斜和高度異質性會帶來相當大的困難。這將不可避免地擴大量化範圍,導致大多數值的表達不夠準確,並降低模型的整體精度。雖然PTQ方法旨在解決這些問題,但在有效分配數據到整個量化空間方面仍然面臨挑戰,限制了優化的潛力,並妨礙了在資源有限的環境中更廣泛的應用。
目前大型語言模型(LLMs)的後訓練量化(PTQ)方法主要集中在僅量化權重和權重-激活量化。僅量化權重的方法,如GPTQ、AWQ和OWQ,試圖通過最小化量化誤差或處理激活異常來減少內存使用,但未能完全優化所有值的精度。像QuIP和QuIP#這樣的技術使用隨機矩陣和向量量化,但在處理極端數據分佈方面仍然有限。權重-激活量化旨在通過量化權重和激活來加快推理速度。然而,像SmoothQuant、ZeroQuant和QuaRot這樣的方法在管理激活異常的主導地位時面臨挑戰,導致大多數值出現錯誤。總體而言,這些方法依賴於啟發式方法,未能在整個量化空間中優化數據分佈,這限制了性能和效率。
為了解決啟發式後訓練量化(PTQ)方法的局限性以及缺乏評估量化效率的指標,來自Houmo AI、南京大學和東南大學的研究人員提出了量化空間利用率(Quantization Space Utilization Rate, QSUR)概念。QSUR衡量權重和激活分佈在量化空間中的有效利用程度,提供了一個量化的基礎來評估和改進PTQ方法。該指標利用統計特性,如特徵值分解和置信橢圓,來計算權重和激活分佈的超體積。QSUR分析顯示線性和旋轉變換如何影響量化效率,特定技術可減少通道間差異並最小化異常值,以提高性能。
研究人員提出了OSTQuant框架,結合了正交和縮放變換來優化大型語言模型的權重和激活分佈。這種方法整合了可學習的對角縮放和正交矩陣的等效變換對,保證計算效率的同時保持量化時的等效性。它在不妨礙原始網絡推理輸出的情況下減少過擬合。OSTQuant使用區塊間學習來在LLM區塊之間全局傳播變換,並採用權重異常最小化初始化(Weight Outlier Minimization Initialization, WOMI)技術進行有效初始化。該方法實現了更高的QSUR,減少了運行時開銷,並提高了LLMs的量化性能。
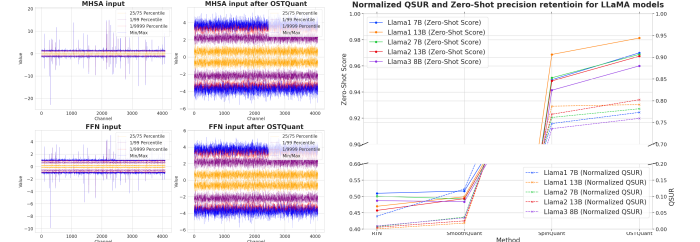
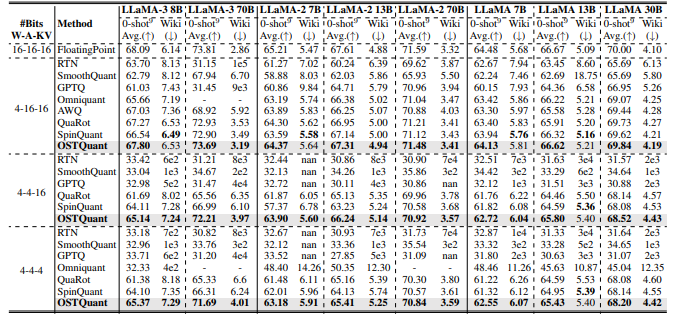
為了進行評估,研究人員將OSTQuant應用於LLaMA系列(LLaMA-1、LLaMA-2和LLaMA-3),並使用WikiText2和九個零樣本任務來評估性能。與SmoothQuant、GPTQ、Quarot和SpinQuant等方法相比,OSTQuant始終表現更佳,在4-16-16設置下達到至少99.5%的浮點精度,顯著縮小了性能差距。LLaMA-3-8B在零樣本任務中僅下降了0.29點,而其他方法的損失超過1.55點。在更困難的情況下,OSTQuant優於SpinQuant,LLaMA-2 7B在4-4-16設置中增長了最多6.53點。KL-Top損失函數提供了更好的語義擬合並減少了噪音,從而提高了性能並將W4A4KV4中的差距降低了32%。這些結果顯示OSTQuant在處理異常值和確保分佈更無偏方面更為有效。

最後,所提出的方法基於QSUR指標和KL-Top損失函數優化了量化空間中的數據分佈,提高了大型語言模型的性能。在低校準數據的情況下,與現有的量化技術相比,它減少了噪音並保持了語義的豐富性,在多個基準中實現了高性能。這個框架可以作為未來工作的基礎,啟動一個將對完善量化技術和提高模型在資源有限環境中高計算效率的應用至關重要的過程。
查看論文。這項研究的所有功勞都歸於這個項目的研究人員。此外,別忘了在Twitter上關注我們,加入我們的Telegram頻道和LinkedIn小組。還有,別忘了加入我們的70k+ ML SubReddit。
🚨 [推薦閱讀] Nebius AI Studio擴展視覺模型、新語言模型、嵌入和LoRA(推廣)
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}