


人工智慧的研究在推理和理解複雜任務方面經歷了重大的發展。最具創新性的進展是大型語言模型 (LLMs) 和多模態大型語言模型 (MLLMs)。這些系統能夠處理文本和視覺數據,使它們能夠分析複雜的任務。與傳統的方法不同,傳統方法主要依賴語言進行推理,而多模態系統則試圖通過結合文本推理和視覺思維來模仿人類的認知,因此能更有效地解決各種挑戰。
目前的問題是,這些模型無法在動態環境中將文本和視覺推理連結在一起。專為推理而開發的模型在基於文本或圖像的輸入上表現良好,但在同時處理兩者時卻無法執行。像迷宮導航或解釋動態佈局這樣的空間推理任務在這些模型中顯示出弱點。這些模型無法滿足綜合推理能力的需求。因此,這限制了模型的適應性和解釋性,特別是在需要理解和操作視覺模式以及用文字給出的指示的任務中。
為了解決這些問題,提出了幾種方法。鏈式思考 (CoT) 提示通過生成逐步的文本痕跡來改善推理。這本質上是基於文本的,無法處理需要空間理解的任務。其他方法則是通過外部工具如圖像標題生成或場景圖生成來進行視覺輸入,允許模型處理視覺和文本數據。雖然這些方法在某種程度上有效,但它們過於依賴單獨的視覺模塊,使其在複雜任務中不夠靈活,容易出錯。
來自微軟研究院 (Microsoft Research)、劍橋大學 (University of Cambridge) 和中國科學院 (Chinese Academy of Sciences) 的研究人員提出了多模態思維可視化 (MVoT) 框架,以解決這些限制。這種新穎的推理範式使模型能夠生成與文字推理交錯的視覺推理痕跡,提供了一種綜合的多模態推理方法。MVoT 將視覺思維能力直接嵌入模型的架構中,從而消除了對外部工具的依賴,使其成為解決複雜推理任務的更具凝聚力的解決方案。

研究人員使用 Chameleon-7B,一種針對多模態推理任務進行微調的自回歸 MLLM,實施了 MVoT。這種方法涉及令牌差異損失,以縮小文本和圖像令牌化過程之間的表示差距,從而輸出高質量的視覺效果。MVoT 通過逐步創建文字和視覺推理痕跡來處理多模態輸入。例如,在迷宮導航等空間任務中,模型生成與推理步驟相對應的中間視覺化,增強了其可解釋性和性能。這種原生的視覺推理能力嵌入框架中,使其更接近人類認知,從而提供了一種更直觀的方法來理解和解決複雜任務。
MVoT 在多個空間推理任務的廣泛實驗中超越了最先進的模型,包括迷宮 (MAZE)、迷你行為 (MINI BEHAVIOR) 和冰凍湖 (FROZEN LAKE)。該框架在迷宮導航任務中達到了 92.95% 的高準確率,超過了傳統的 CoT 方法。在需要理解與空間佈局互動的 MINI BEHAVIOR 任務中,MVoT 達到了 95.14% 的準確率,顯示出其在動態環境中的適用性。在以細緻空間細節著稱的 FROZEN LAKE 任務中,MVoT 的穩健性達到了 85.60% 的準確率,超越了 CoT 和其他基準。MVoT 在挑戰性場景中持續改善,特別是涉及複雜視覺模式和空間推理的任務。
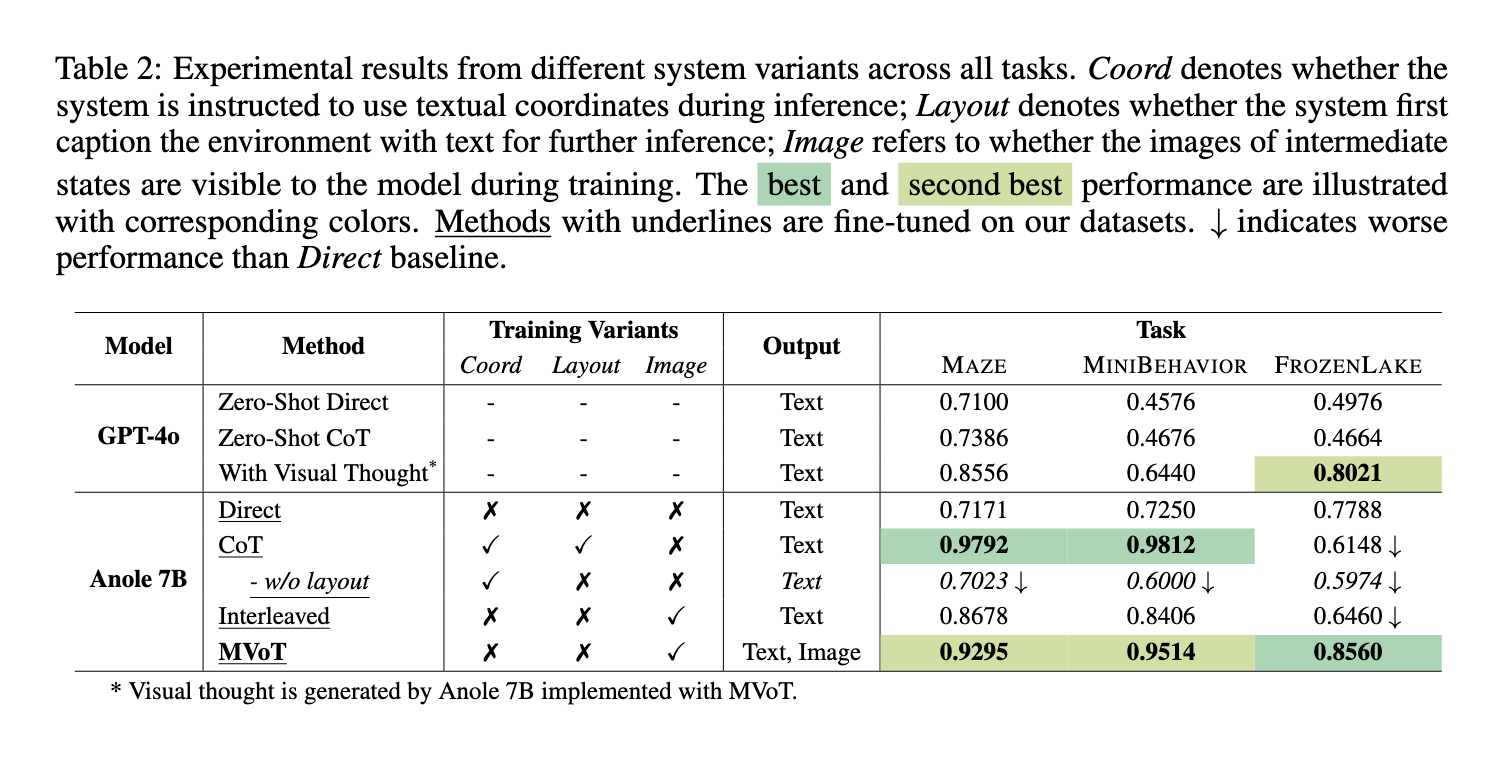
除了性能指標外,MVoT 還通過生成視覺思維痕跡來改善可解釋性,這些痕跡補充了文字推理。這種能力使用戶能夠直觀地跟隨模型的推理過程,使其更容易理解和驗證結論。與僅基於文本描述的 CoT 不同,MVoT 的多模態推理方法減少了由於文本表示不佳而造成的錯誤。例如,在 FROZEN LAKE 任務中,MVoT 在環境複雜性增加的情況下保持穩定的性能,從而展示了其穩健性和可靠性。

因此,這項研究通過將文本和視覺整合到推理任務中,重新定義了人工智慧的推理能力。使用令牌差異損失確保視覺推理與文本處理無縫對接。這將彌補當前方法中的關鍵差距。卓越的性能和更好的可解釋性將使 MVoT 成為多模態推理的一個里程碑,為現實場景中的更複雜和挑戰性的人工智慧系統開啟大門。
查看論文。這項研究的所有榮譽都歸於這個項目的研究人員。此外,別忘了在 Twitter 上關注我們,加入我們的 Telegram 頻道和 LinkedIn 群組。別忘了加入我們的 65k+ ML SubReddit。
🚨 推薦開源平台:Parlant 是一個改變 AI 代理在面對客戶場景中做決策方式的框架。(廣告)
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!







")
{kind=link}