


開發有效的多模態人工智慧系統以應用於真實世界需要處理多樣化的任務,例如細緻的識別、視覺定位、推理和多步驟問題解決。目前的開源多模態語言模型在這些領域上表現不佳,尤其是在涉及外部工具的任務,例如光學字符識別 (OCR) 或數學計算。這些限制主要是因為現有的數據集偏向單步驟,無法提供多步推理和邏輯行動鏈的連貫框架。克服這些挑戰對於在複雜層面上釋放多模態人工智慧的真正潛力至關重要。
目前的多模態模型通常依賴於指令調整,使用直接答案的數據集或少量示例提示的方法。像 GPT-4 這樣的專有系統已經展示了有效地通過 CoTA 鏈進行推理的能力。同時,開源模型面臨著數據集不足和工具整合的挑戰。早期的努力,例如 LLaVa-Plus 和 Visual Program Distillation,也受到小數據集規模、低質量訓練數據和專注於簡單問答任務的限制,使它們無法應對更複雜的多模態問題,這些問題需要更複雜的推理和工具應用。
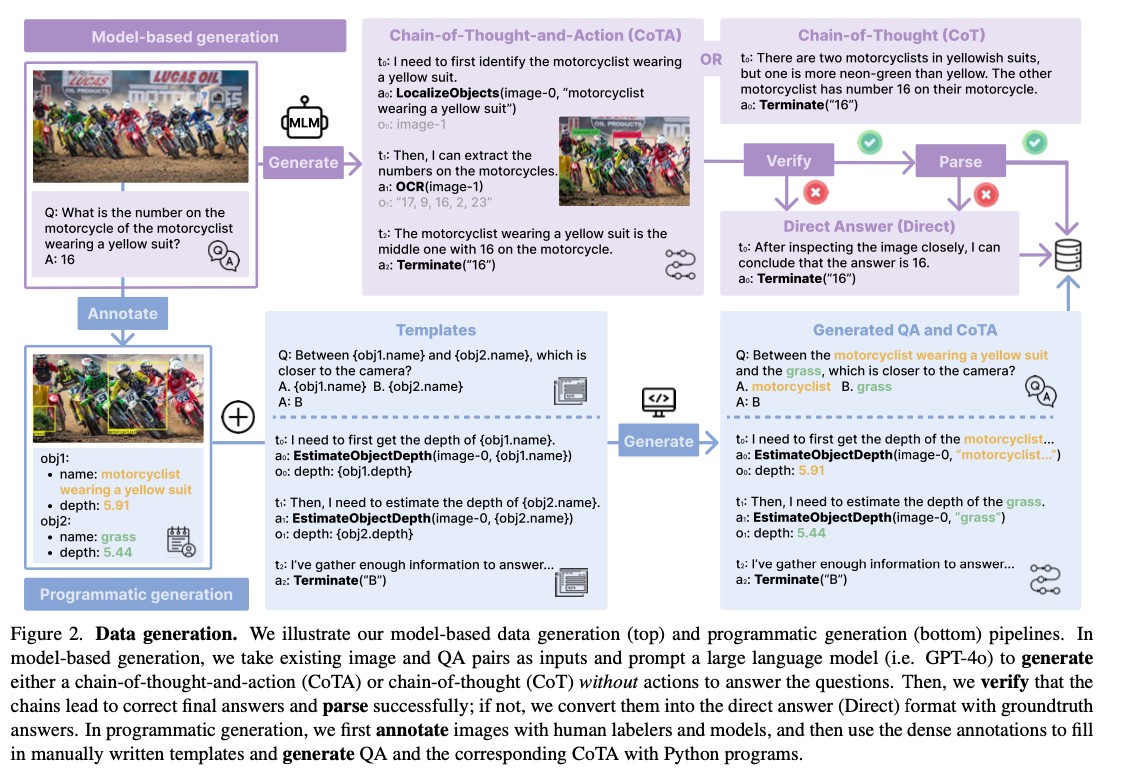
來自華盛頓大學和 Salesforce Research 的研究人員開發了 TACO,一個創新的框架,用於使用合成 CoTA 數據集訓練多模態行動模型。這項工作引入了幾個關鍵的進展,以解決先前方法的限制。首先,使用 GPT-4 和 Python 程式生成了超過 180 萬條數據,而經過嚴格篩選技術整理出 293K 的高質量示例,這些示例確保了多樣化的推理和行動序列,對於多模態學習至關重要。其次,TACO 包含了一組強大的 15 種工具,包括 OCR、物體定位和數學解決方案,使模型能夠有效處理複雜任務。第三,先進的篩選和數據混合技術進一步優化了數據集,強調推理與行動的整合,促進了更優越的學習成果。這個框架重新詮釋了多模態學習,使模型能夠產生連貫的多步推理,同時無縫整合行動,從而為複雜場景的性能建立了新的基準。
TACO 的開發涉及在一個精心策劃的 CoTA 數據集上進行訓練,該數據集包含來自 31 個不同來源的 293K 實例,包括 Visual Genome。這些數據集包含了數學推理、光學字符識別和詳細的視覺理解等多種任務。它是高度異質的,提供的工具包括物體定位和基於語言的解決方案,允許進行多種推理和行動任務。訓練架構結合了 LLaMA3 作為語言基礎,CLIP 作為視覺編碼器,從而建立了一個強大的多模態框架。微調過程中確立了超參數調整,專注於降低學習率和增加訓練的輪次,以確保模型能夠充分解決複雜的多模態挑戰。
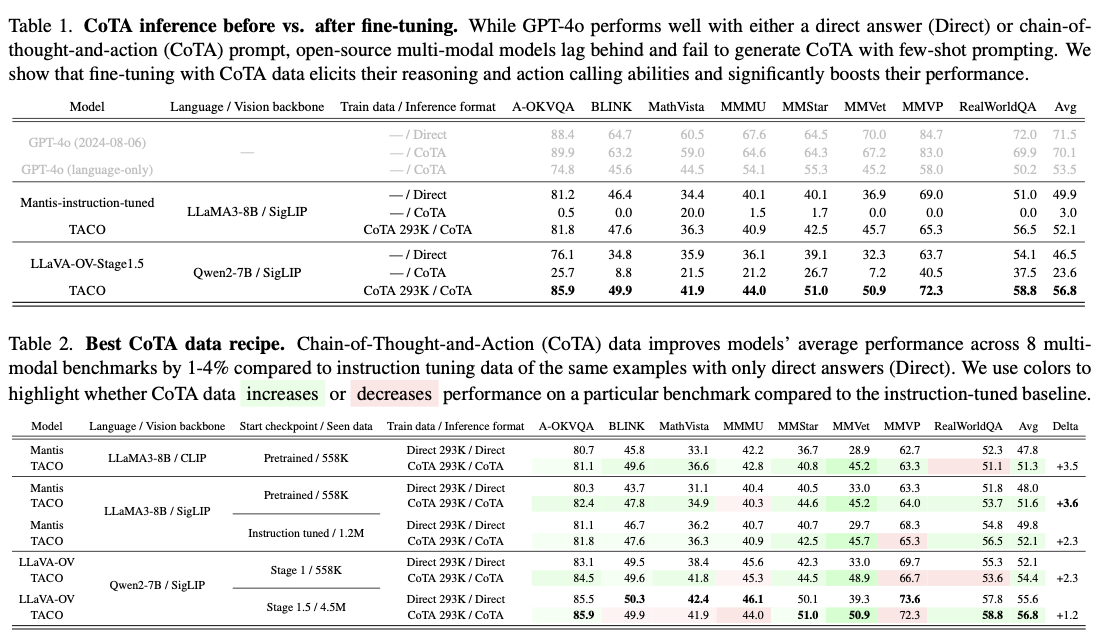
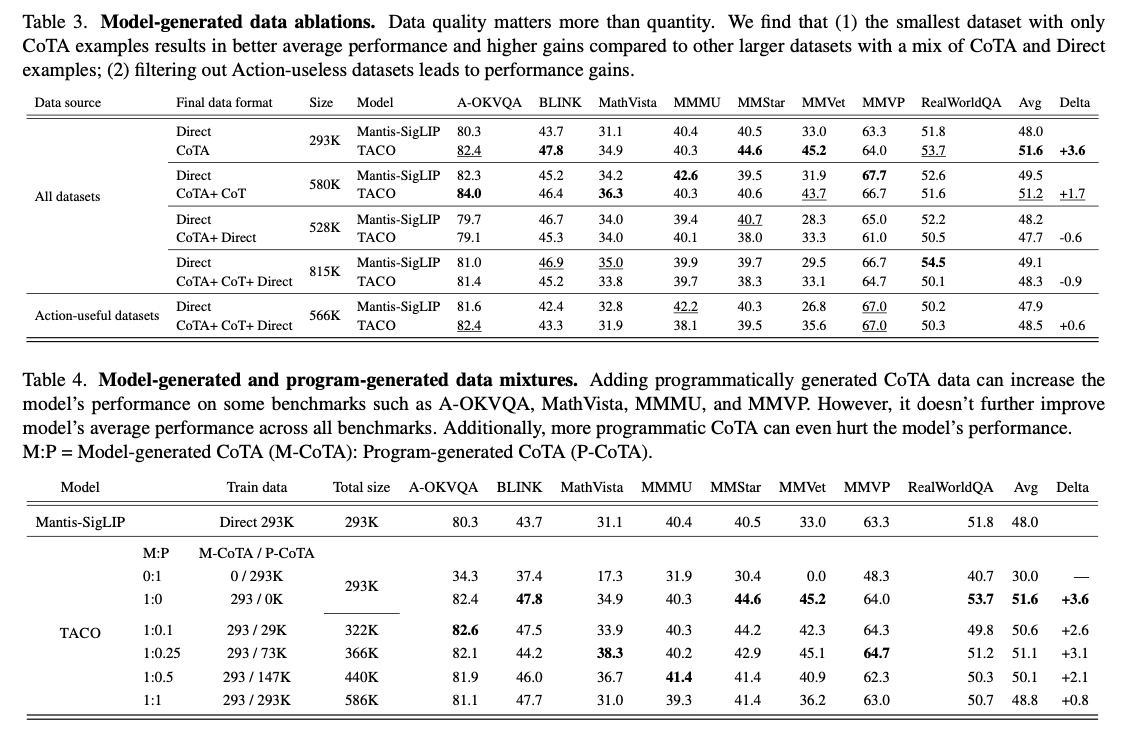
TACO 在八個基準測試中的表現顯示了它對推進多模態推理能力的重大影響。該系統在指令調整的基準上平均提高了 3.6% 的準確率,在涉及 OCR 和數學推理的 MMVet 任務中,增幅高達 15%。值得注意的是,高質量的 293K CoTA 數據集的表現超過了更大但質量較低的數據集,突顯了針對性數據策劃的重要性。通過超參數策略的調整,包括視覺編碼器的調整和學習率的優化,進一步提高了性能。表 2:結果顯示 TACO 在基準測試中的表現優異,尤其在涉及推理和行動整合的複雜任務中表現更佳。

TACO 引入了一種新的多模態行動建模方法,有效地解決了推理和基於工具的行動的重大缺陷,通過高質量的合成數據集和創新的訓練方法。這項研究克服了傳統指令調整模型的限制,其發展有望改變從視覺問答到複雜多步推理任務的真實應用場景。
查看論文、GitHub 頁面和項目頁面。這項研究的所有榮譽都歸於這個項目的研究人員。此外,別忘了在 Twitter 上關注我們,加入我們的 Telegram 頻道和 LinkedIn 群組。也別忘了加入我們的 65K+ 機器學習 SubReddit。
🚨 免費即將舉行的人工智慧網路研討會 (2025 年 1 月 15 日):使用合成數據和評估智能提升 LLM 準確性——加入這個網路研討會,獲取提升 LLM 模型性能和準確性的可行見解,同時保護數據隱私。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}