


大型語言模型(LLMs)徹底改變了生成式人工智慧,展現出驚人的能力,能夠產生類似人類的回應。然而,這些模型面臨一個重要挑戰,稱為「幻覺」,也就是生成不正確或不相關資訊的傾向。這個問題在一些高風險的應用中,如醫療評估、保險索賠處理和自主決策系統,可能會帶來重大風險,因為這些情況下準確性至關重要。幻覺問題不僅存在於文本模型中,還擴展到處理圖像和文本查詢的視覺語言模型(VLMs)。儘管已經開發出如 LLaVA、InstructBLIP 和 VILA 等強大的 VLMs,但這些系統在根據圖像輸入和用戶查詢生成準確回應方面仍然面臨挑戰。
現有研究提出了幾種方法來解決語言模型中的幻覺問題。對於基於文本的系統,FactScore 通過將長句子拆分為基本單位來提高準確性,以便更好地進行驗證。Lookback Lens 則開發了一種注意力得分分析方法來檢測上下文幻覺,而 MARS 則實施了一個加權系統,專注於關鍵陳述組件。針對 RAG 系統,RAGAS 和 LlamaIndex 作為評估工具出現,其中 RAGAS 專注於使用人類評估者來評估回應的準確性和相關性,而 LlamaIndex 則利用 GPT-4 進行忠實度評估。然而,現有的研究並未提供專門針對多模態 RAG 系統的幻覺得分,這些系統的上下文包含多個多模態數據。
來自馬里蘭大學(University of Maryland)、公園校區(College Park, MD)和 NEC 實驗室美國(NEC Laboratories America, Princeton, NJ)的研究人員提出了 RAG-check,這是一種綜合方法,用於評估多模態 RAG 系統。它由三個關鍵組件組成,旨在評估相關性和準確性。第一個組件涉及一個神經網絡,評估每個檢索到的數據片段與用戶查詢的相關性。第二個組件實施一種算法,將 RAG 輸出分段並分類為可評分(客觀)和不可評分(主觀)範圍。第三個組件利用另一個神經網絡,根據原始上下文評估客觀範圍的正確性,這些上下文可以包括通過 VLMs 轉換為文本格式的文本和圖像。
RAG-check 架構使用兩個主要評估指標:相關性得分(Relevancy Score, RS)和正確性得分(Correctness Score, CS),來評估 RAG 系統性能的不同方面。為了評估選擇機制,系統分析了在 1,000 個問題的測試集上檢索到的前 5 張圖像的相關性得分,提供了不同檢索方法有效性的見解。在上下文生成方面,該架構允許靈活整合各種模型組合,可以是獨立的 VLMs(如 LLaVA 或 GPT-4)和 LLMs(如 LLAMA 或 GPT-3.5),或統一的多模態語言模型(MLLMs)如 GPT-4。這種靈活性使得能夠全面評估不同模型架構及其對回應生成質量的影響。
評估結果顯示,不同 RAG 系統配置之間的性能差異顯著。當使用 CLIP 模型作為視覺編碼器並使用餘弦相似度進行圖像選擇時,平均相關性得分範圍為 30% 到 41%。然而,實施 RS 模型進行查詢-圖像對評估時,相關性得分顯著提高至 71% 到 89.5%,但在使用 A100 GPU 時,計算需求增加了 35 倍。GPT-4o 成為上下文生成和錯誤率的最佳配置,表現超過其他設置 20%。其餘 RAG 配置的性能相當,準確率介於 60% 到 68% 之間。
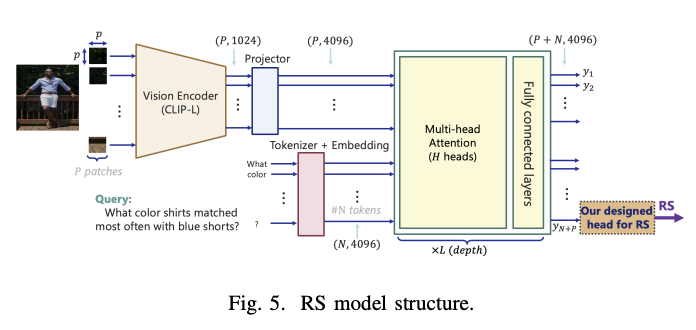
總結來說,研究人員提出了 RAG-check,這是一個新穎的評估框架,用於多模態 RAG 系統,以解決在多個圖像和文本輸入中檢測幻覺的關鍵挑戰。該框架的三個組件架構,包括相關性評分、範圍分類和正確性評估,顯示出性能評估的顯著改進。結果顯示,雖然 RS 模型將相關性得分從 41% 大幅提升至 89.5%,但這也伴隨著計算成本的增加。在測試的各種配置中,GPT-4o 成為上下文生成的最有效模型,突顯了統一多模態語言模型在提高 RAG 系統準確性和可靠性方面的潛力。
查看論文。這項研究的所有功勞都歸於這個項目的研究人員。此外,別忘了在 Twitter 上關注我們,加入我們的 Telegram 頻道和 LinkedIn 群組。還有,不要忘記加入我們的 65k+ 機器學習 SubReddit。
🚨 免費即將舉行的人工智慧網路研討會(2025 年 1 月 15 日):透過合成數據和評估智慧提升 LLM 準確性——加入這個網路研討會,獲取提升 LLM 模型性能和準確性的可行見解,同時保護數據隱私。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}