


數學推理是人工智慧的基礎,對於算術、幾何和競賽級的問題非常重要。最近,大型語言模型 (LLMs) 成為非常有用的推理工具,展現出逐步推理的能力,並能對複雜任務提供清晰的解釋。然而,隨著這些模型的成功,所需的計算資源越來越難以支持,這使得在受限環境中部署它們變得困難。
研究人員面臨的直接挑戰是降低 LLMs 的計算和記憶需求,而不影響性能。數學推理是一個很大的挑戰,因為它需要保持準確性和邏輯一致性,否則許多技術可能會妥協這些目標。將模型擴展到現實使用受到這些限制的嚴重影響。
目前針對這一挑戰的方法包括修剪、知識蒸餾和量化。量化是將模型權重和激活轉換為低位格式的過程,確實有助於減少記憶消耗,同時提高計算效率。然而,它對需要逐步推理的任務的影響尚不清楚,特別是在數學領域。大多數現有方法無法捕捉效率與推理準確性之間的微妙權衡。
來自香港理工大學、南方科技大學、清華大學、武漢大學和香港大學的一組研究人員開發了一個系統框架,研究量化對數學推理的影響。他們使用了幾種量化技術,如 GPTQ 和 SmoothQuant,來結合和評估這兩種技術對推理的影響。團隊專注於 MATH 基準,這需要逐步解決問題,並分析這些方法在不同精度水平下造成的性能下降。
研究人員使用了一種方法,涉及用結構化標記和註釋來訓練模型。這些標記包括特殊標記來定義推理步驟,確保模型即使在量化下也能保留中間步驟。為了減少對模型的架構變更,同時應用類似 LoRA 的微調技術,這種適應性方法在實施和量化模型中平衡了效率和準確性的權衡。因此,它為模型提供了邏輯一致性。同樣,PRM800K 數據集的步驟級正確性也被視為訓練數據,以使模型學會重現細緻的推理步驟。
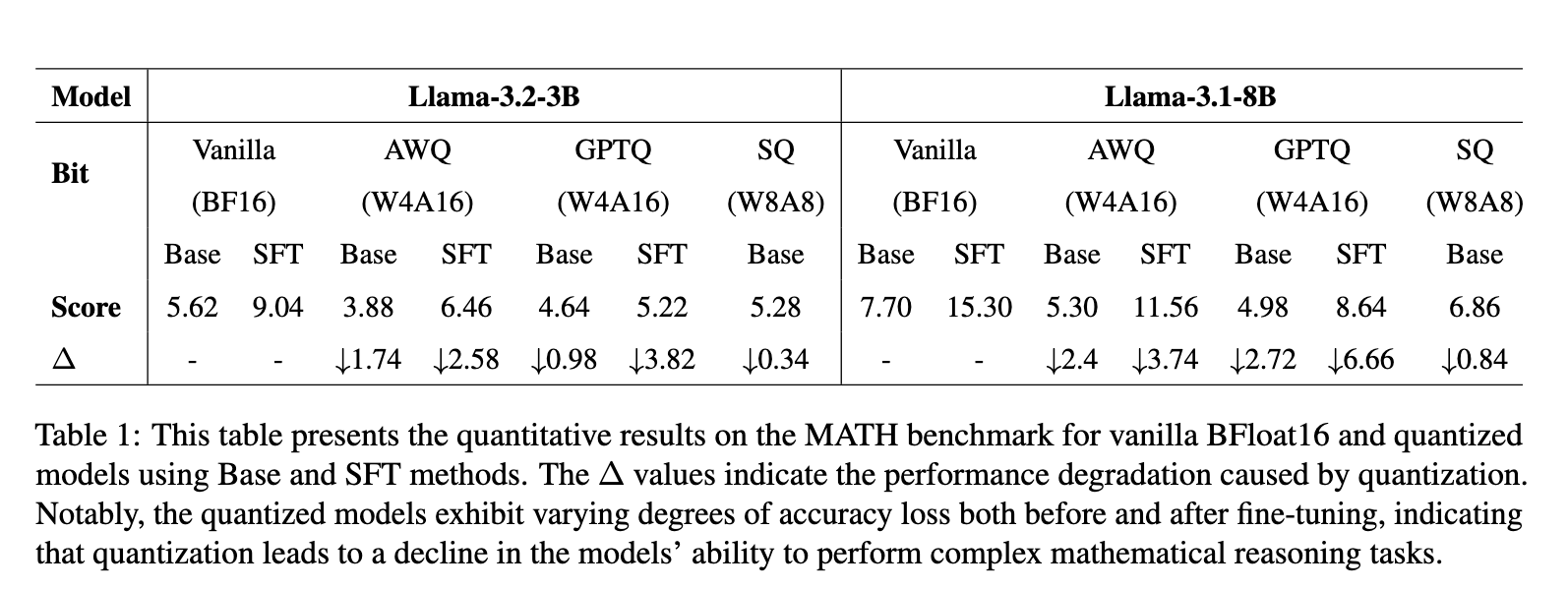
深入的性能分析揭示了量化模型的關鍵缺陷。量化對計算密集型任務的影響很大,不同配置下性能大幅下降。例如,Llama-3.2-3B 模型的準確性下降,分數從全精度的 5.62 降至 GPTQ 量化的 3.88 和 SmoothQuant 的 4.64。Llama-3.1-8B 模型的性能損失較小,分數從全精度的 15.30 降至 GPTQ 的 11.56 和 SmoothQuant 的 13.56。SmoothQuant 在所有測試的方法中顯示出最高的穩健性,表現優於 GPTQ 和 AWQ。結果突顯了低位格式中的一些挑戰,特別是在保持數值計算精度和邏輯一致性方面。
這項研究的結果清楚地顯示了量化 LLMs 中計算效率和推理準確性之間的權衡。儘管像 SmoothQuant 這樣的技術有助於減輕一些性能下降,但保持高保真推理的挑戰仍然很大。研究人員通過引入結構化註釋和微調方法,為在資源有限的環境中優化 LLMs 提供了寶貴的見解。這些發現對於在實際應用中部署 LLMs 至關重要,提供了一條平衡效率與推理能力的途徑。
總之,這項研究解決了理解量化對數學推理影響的關鍵空白。這裡提出的方法和框架指出了現有量化技術的一些不足,並提供了可行的策略來克服這些問題。這些進展為更高效和更有能力的人工智慧系統開辟了道路,縮小了理論潛力與現實應用之間的差距。
查看論文。這項研究的所有功勞都歸於這個項目的研究人員。此外,別忘了在 Twitter 上關注我們,加入我們的 Telegram 頻道和 LinkedIn 群組。還有,別忘了加入我們的 60k+ ML SubReddit。
🚨 免費即將舉行的 AI 網路研討會 (2025年1月15日):使用合成數據和評估智慧提升 LLM 準確性–加入這個研討會,獲取提升 LLM 模型性能和準確性的可行見解,同時保護數據隱私。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}