


軟體工程代理人已成為管理複雜編碼任務的重要工具,特別是在大型代碼庫中。這些代理人使用先進的語言模型來理解自然語言描述、分析代碼庫並實施修改。它們的應用包括除錯、功能開發和優化。這些系統的有效性依賴於它們處理現實挑戰的能力,例如與龐大的代碼庫互動和執行測試以驗證解決方案,使得開發這些代理人既令人興奮又具有挑戰性。
缺乏全面的訓練環境是這個領域的主要挑戰之一。許多現有的數據集和基準,如 SWE-Bench 和 R2E,要麼專注於孤立的問題,要麼依賴於不代表現實編碼任務複雜性的合成指令。例如,雖然 SWE-Bench 提供了驗證的測試案例,但其訓練數據集缺乏可執行環境和依賴配置。這種差異限制了現有基準在訓練能夠解決軟體工程細微挑戰的代理人方面的效用。
過去,解決這些挑戰的努力依賴於像 HumanEval 和 APPS 這樣的工具,這些工具支持孤立任務的評估,但未能整合代碼庫層級的複雜性。這些工具通常缺乏自然語言問題描述、可執行代碼庫和全面測試框架之間的連貫聯繫。因此,迫切需要一個平台來彌補這些差距,提供在功能和可執行環境中的現實任務。
來自加州大學伯克利分校 (UC Berkeley)、伊利諾伊大學香檳分校 (UIUC)、卡內基梅隆大學 (CMU) 和蘋果公司 (Apple Inc.) 的研究人員開發了 SWE-Gym,這是一個專為訓練軟體工程代理人而設計的新環境。SWE-Gym 整合了來自 GitHub 問題的 2,438 個 Python 任務,涵蓋 11 個代碼庫,提供預配置的可執行環境和專家驗證的測試案例。這個平台通過結合現實任務的複雜性和自動化測試機制,創造了一個更有效的語言模型訓練生態系統。
SWE-Gym 的方法專注於複製現實編碼條件。這些任務來自 GitHub 問題,並與相應的代碼庫快照和單元測試配對。每個任務的依賴項都經過精心配置,以確保可執行環境的準確性。這些配置經過約 200 小時的人類標註和 10,000 小時的 CPU 核心時間的嚴格過程進行半手動驗證,形成了一個穩健的訓練數據集。研究人員還引入了一個包含 230 個任務的子集,稱為 SWE-Gym Lite,針對更簡單和自包含的問題,便於快速原型設計和評估。
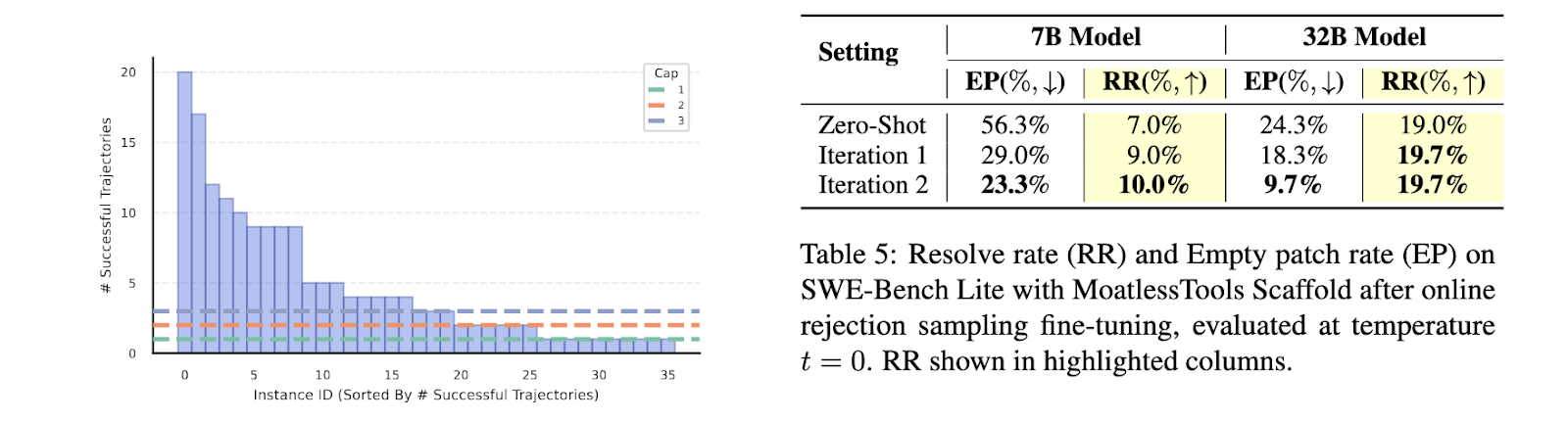
SWE-Gym 的性能評估顯示其對訓練軟體工程代理人的重大影響。使用 Qwen-2.5 Coder 模型,經過微調的代理人在 SWE-Bench 基準上解決任務的成功率顯著提高。具體而言,SWE-Bench Verified 的解決率從 20.6% 提高到 32.0%,而 SWE-Bench Lite 的解決率從 15.3% 提高到 26.0%。這些增長代表了對開放權重語言模型的先前基準的重大飛躍。此外,SWE-Gym 支持的代理人在循環卡住情況下的失敗率降低了 18.6%,並在現實環境中的任務完成率有所提高。
研究人員還通過使用在 SWE-Gym 中採樣的代理人軌跡訓練的驗證器來探索推斷時間的擴展。這種方法使代理人能夠為給定問題生成多個解決方案軌跡,並使用獎勵模型選擇最有前途的解決方案。驗證器在 SWE-Bench Verified 上達到了 32.0% 的 Best@K 分數,顯示出該環境通過可擴展計算策略提升代理人性能的能力。這些結果強調了 SWE-Gym 在提升軟體工程代理人開發和評估方面的潛力。
SWE-Gym 是推進軟體工程代理人研究的重要工具。通過解決先前基準的局限性並提供可擴展、現實的環境,為研究人員提供了開發能夠解決複雜軟體挑戰的穩健模型所需的資源。隨著其開源發布,SWE-Gym 為該領域的重大進展鋪平了道路,為軟體工程代理人的訓練和評估設定了新標準。
查看論文和 GitHub。所有這項研究的功勞都歸功於這個項目的研究人員。此外,別忘了在 Twitter 上關注我們,加入我們的 Telegram 頻道和 LinkedIn 群組。還有,別忘了加入我們的 60,000 多名機器學習 SubReddit。
🚨 免費即將舉行的 AI 網路研討會 (2025 年 1 月 15 日):提升 LLM 準確性與合成數據和評估智慧–加入這個網路研討會,獲取提升 LLM 模型性能和準確性的可行見解,同時保護數據隱私。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}