


受到大腦啟發,神經網絡對於識別圖像和處理語言非常重要。這些網絡依賴於激活函數,這使它們能夠學習複雜的模式。然而,許多激活函數面臨挑戰。有些函數會遇到消失梯度的問題,這會減慢深層網絡的學習速度,而其他函數則會出現“死神經元”的情況,讓某些部分的網絡停止學習。現代的替代方案旨在解決這些問題,但通常也有效率低下或性能不一致的缺點。
目前,神經網絡中的激活函數面臨重大問題。像階梯函數和Sigmoid函數在消失梯度方面表現不佳,限制了它們在深層網絡中的有效性,而雖然tanh函數稍微改善了這一點,但也出現了其他問題。ReLU函數解決了一些梯度問題,但引入了“死ReLU”的問題,使神經元變得不活躍。像Leaky ReLU和PReLU這樣的變體試圖修復這些問題,但帶來了不一致性和正則化的挑戰。更先進的函數如ELU、SiLU和GELU改善了非線性,但增加了複雜性和偏差,而像Mish和Smish這樣的新設計只在特定情況下顯示穩定性,並未在整體情況下有效。
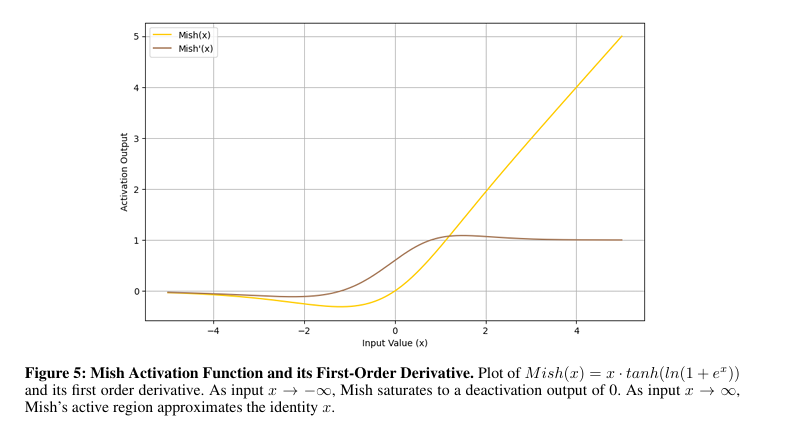
為了解決這些問題,南佛羅里達大學的研究人員提出了一種新的激活函數TeLU(x) = x · tanh(ex),這結合了ReLU的學習效率和光滑函數的穩定性及泛化能力。這個函數引入了平滑的過渡,意味著當輸入變化時,函數的輸出會逐漸改變,並且具有接近零均值的激活和穩健的梯度動態,以克服現有激活函數的一些問題。這個設計旨在在各種任務中提供一致的性能,改善收斂性,並在淺層和深層架構中增強穩定性和更好的泛化能力。
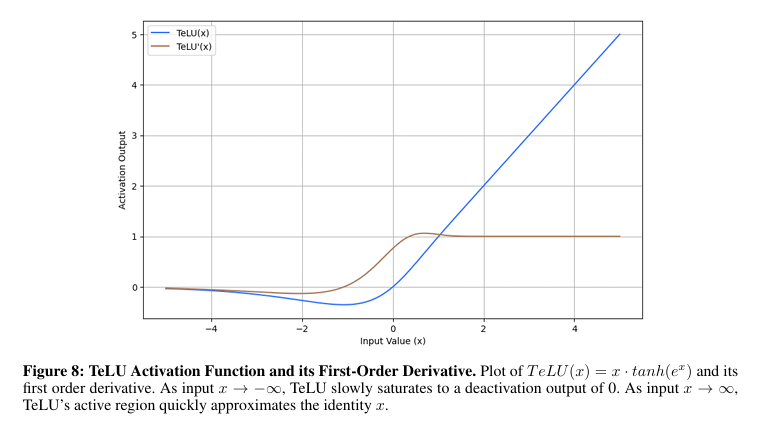
研究人員專注於增強神經網絡,同時保持計算效率。他們的目標是快速收斂算法,保持訓練過程的穩定性,並使其對未見數據的泛化能力強。這個函數在數學上是非多項式和解析的,因此可以近似任何連續的目標函數。這種方法強調改善學習的穩定性和自我正則化,同時最小化數值不穩定性。通過結合線性和非線性特性,這個框架可以支持高效學習,並幫助避免爆炸梯度等問題。

研究人員通過實驗評估了TeLU的性能,並將其與其他激活函數進行比較。結果顯示,TeLU有助於防止消失梯度問題,這對於有效訓練深層網絡非常重要。它在大型數據集上進行測試,如ImageNet和Dynamic-Pooling Transformers在Text8上,顯示出比傳統函數如ReLU更快的收斂速度和更好的準確性。實驗還顯示,TeLU在計算上是高效的,並且與基於ReLU的配置良好配合,通常會導致更好的結果。實驗確認TeLU在各種神經網絡架構和訓練方法中都穩定且表現更佳。
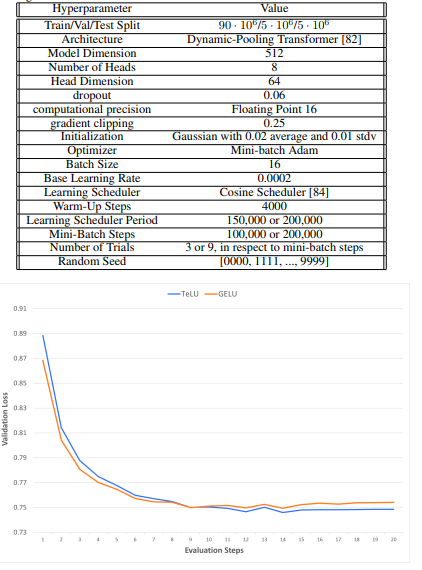
最後,研究人員提出的激活函數解決了現有激活函數的主要挑戰,通過防止消失梯度問題、提高計算效率,並在多樣的數據集和架構中顯示出更好的性能。它在ImageNet、Text8和Penn Treebank等基準測試中的成功應用,顯示出更快的收斂速度、準確性提升和深度學習模型的穩定性,使TeLU成為深度神經網絡的一個有前途的工具。此外,TeLU的性能可以作為未來研究的基準,激勵進一步開發激活函數,以實現更高的效率和可靠性,推動機器學習的進步。
查看論文。所有研究的功勞都歸於這個項目的研究人員。此外,別忘了在Twitter上關注我們,加入我們的Telegram頻道和LinkedIn小組。還有,別忘了加入我們的60k+ ML SubReddit。
🚨 免費即將舉行的AI網絡研討會(2025年1月15日):使用合成數據和評估智能提升LLM準確性——加入這個網絡研討會,獲取提升LLM模型性能和準確性的可行見解,同時保護數據隱私。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}