


FineWeb2 大幅提升了多語言的預訓練數據集,涵蓋了超過 1000 種語言,並提供高品質的數據。這個數據集使用了大約 8TB 的壓縮文本數據,包含近 3 兆個單詞,這些數據來自於 2013 到 2024 年之間的 96 次 CommonCrawl 快照。透過 datatrove 函式庫處理後,FineWeb2 在九種不同語言上表現優於 CC-100、mC4、CulturaX 和 HPLT 等已建立的數據集。詳細的實驗設置和評估可以在這個 github 倉庫中找到。
Huggingface 社群的研究人員推出了 FineWeb-C,這是一個由社群驅動的合作項目,旨在擴展 FineWeb2,創建高品質的教育內容標註,涵蓋數百種語言。這個項目讓社群成員能夠評估網頁內容的教育價值,並透過 Argilla 平台識別問題元素。達到 1,000 個標註的語言將有資格納入數據集。這個標註過程有兩個目的:識別高品質的教育內容,並改善所有語言的 LLM(大型語言模型)開發。
318 位 Hugging Face 社群成員提交了 32,863 個標註,為開發高品質的 LLM 在資源不足的語言中做出了貢獻。FineWeb-Edu 是基於原始 FineWeb 數據集建立的,並使用在 LLama3-70B-Instruct 標註上訓練的教育質量分類器來識別和保留最具教育價值的內容。這種方法已被證明成功,表現超過 FineWeb,並減少了訓練有效 LLM 所需的數據量。這個項目的目標是通過收集社群標註,將 FineWeb-Edu 的能力擴展到所有世界語言,訓練特定語言的教育質量分類器。
該項目優先考慮人類生成的標註,而非基於 LLM 的標註,特別是在資源不足的語言中,因為 LLM 的表現無法可靠地驗證。這種社群驅動的方式類似於維基百科的合作模式,強調開放存取和人工智慧技術的民主化。貢獻者參與一個更大的運動,旨在打破 AI 開發中的語言障礙,因為商業公司通常專注於盈利的語言。這個數據集的開放性質使任何人都能建立針對特定社群需求的 AI 系統,同時促進對不同語言有效方法的學習。
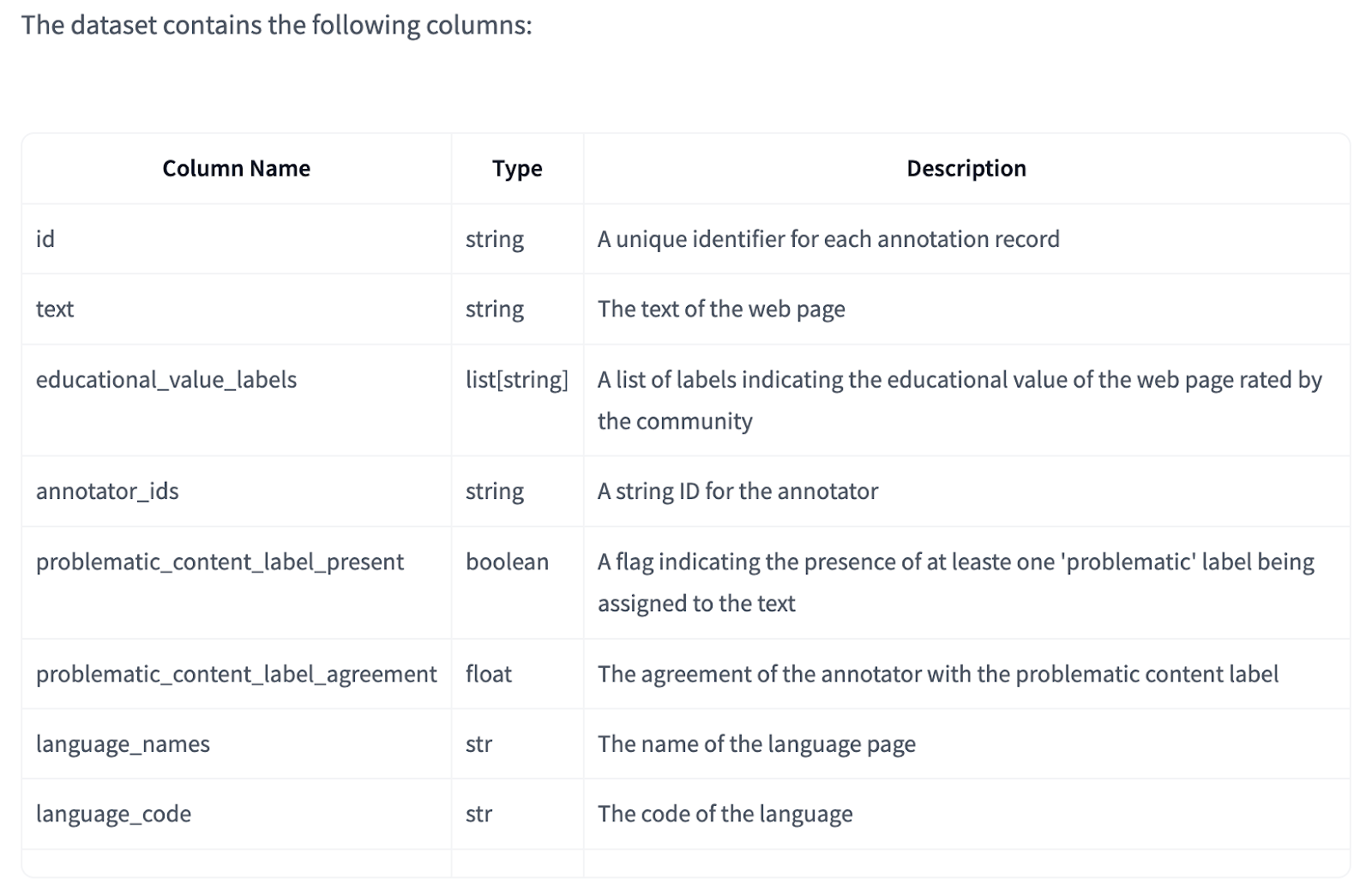
FineWeb-Edu 在某些語言的每個頁面上使用多個標註,允許靈活計算標註者的協議。質量控制措施包括計劃在標註較多的語言中增加標註重疊。數據中包含一個布林欄位 ‘problematic_content_label_present’,用於識別帶有問題內容標籤的頁面,這通常是由於錯誤的語言檢測所致。用戶可以根據個別問題標籤或標註者協議通過 ‘problematic_content_label_agreement’ 欄位過濾內容。該數據集在 ODC-By v1.0 許可證和 CommonCrawl 的使用條款下運作。
總結來說,FineWeb2 的社群驅動擴展 FineWeb-C 已經從 318 位貢獻者那裡收集了 32,863 個標註,專注於教育內容的標註。這個項目在現有數據集中表現優於使用較少訓練數據的 FineWeb-Edu 的專門教育內容分類器。與商業方法不同,這個開源倡議優先考慮人類標註而非基於 LLM 的標註,特別是在資源不足的語言中。該數據集具備強健的質量控制措施,包括多層標註和問題內容過濾,同時在 ODC-By v1.0 許可證下運作。
查看詳細資訊。所有研究的功勞都歸於這個項目的研究人員。此外,別忘了在 Twitter 上關注我們,並加入我們的 Telegram 頻道和 LinkedIn 群組。也別忘了加入我們的 60k+ ML SubReddit。
🚨 熱門消息:LG AI 研究發布 EXAONE 3.5:三個開源雙語前沿 AI 模型,提供無與倫比的指令跟隨和長上下文理解,領導全球生成 AI 的卓越……。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}