


程式碼智能正在快速成長,這主要得益於大型語言模型(LLMs)的進步。這些模型越來越多地用於自動化編程任務,例如程式碼生成、除錯和測試。LLMs具備多種語言和領域的能力,已成為推進軟體開發、數據科學和計算問題解決的重要工具。LLMs的演變正在改變我們處理和執行複雜編程任務的方式。
目前的一個重要改進領域是需要全面的基準測試,以準確反映現實世界的編程需求。現有的評估數據集,如HumanEval、MBPP和DS-1000,通常只專注於特定領域,例如高級算法或機器學習,未能捕捉到全棧編程所需的多樣性。此外,這些數據集在評估多語言和跨領域能力方面也可以更廣泛,這一缺口對有效測量和提升LLM的表現構成了重大障礙。
來自字節跳動(ByteDance)Seed和M-A-P的研究人員推出了FullStack Bench,這是一個評估LLMs在11個不同應用領域的基準,並支持16種編程語言。這個基準涵蓋了數據分析、桌面和網頁開發、機器學習以及多媒體等領域。此外,他們還開發了SandboxFusion,這是一個統一的執行環境,能夠自動化多種語言的程式碼執行和評估。這些工具旨在提供一個全面的框架,用於在現實場景中測試LLMs,並克服現有基準的限制。
FullStack Bench數據集包含3,374個問題,每個問題都有單元測試案例、參考解答,以及簡單、中等和困難的難度分類。這些問題是通過結合人類專家的知識和LLM輔助的過程來策劃的,確保了問題設計的多樣性和質量。SandboxFusion支持FullStack Bench問題的執行,通過提供安全、隔離的執行環境來滿足不同編程語言和依賴的需求。它支持23種編程語言,為在FullStack Bench之外的數據集上基準測試LLMs提供了一個可擴展和多功能的解決方案,包括流行的基準如HumanEval和MBPP。
研究人員進行了廣泛的實驗,以評估各種LLMs在FullStack Bench上的表現。結果顯示,不同領域和編程語言的表現差異明顯。例如,雖然某些模型在基本編程和數據分析能力上表現良好,但在多媒體和操作系統相關任務上卻遇到困難。主要評估指標Pass@1在不同領域之間存在變化,突顯了模型在適應多樣和複雜編程任務方面的挑戰。SandboxFusion被證明是一個強大而高效的評估工具,在支持多種編程語言和依賴方面顯著超越了現有的執行環境。
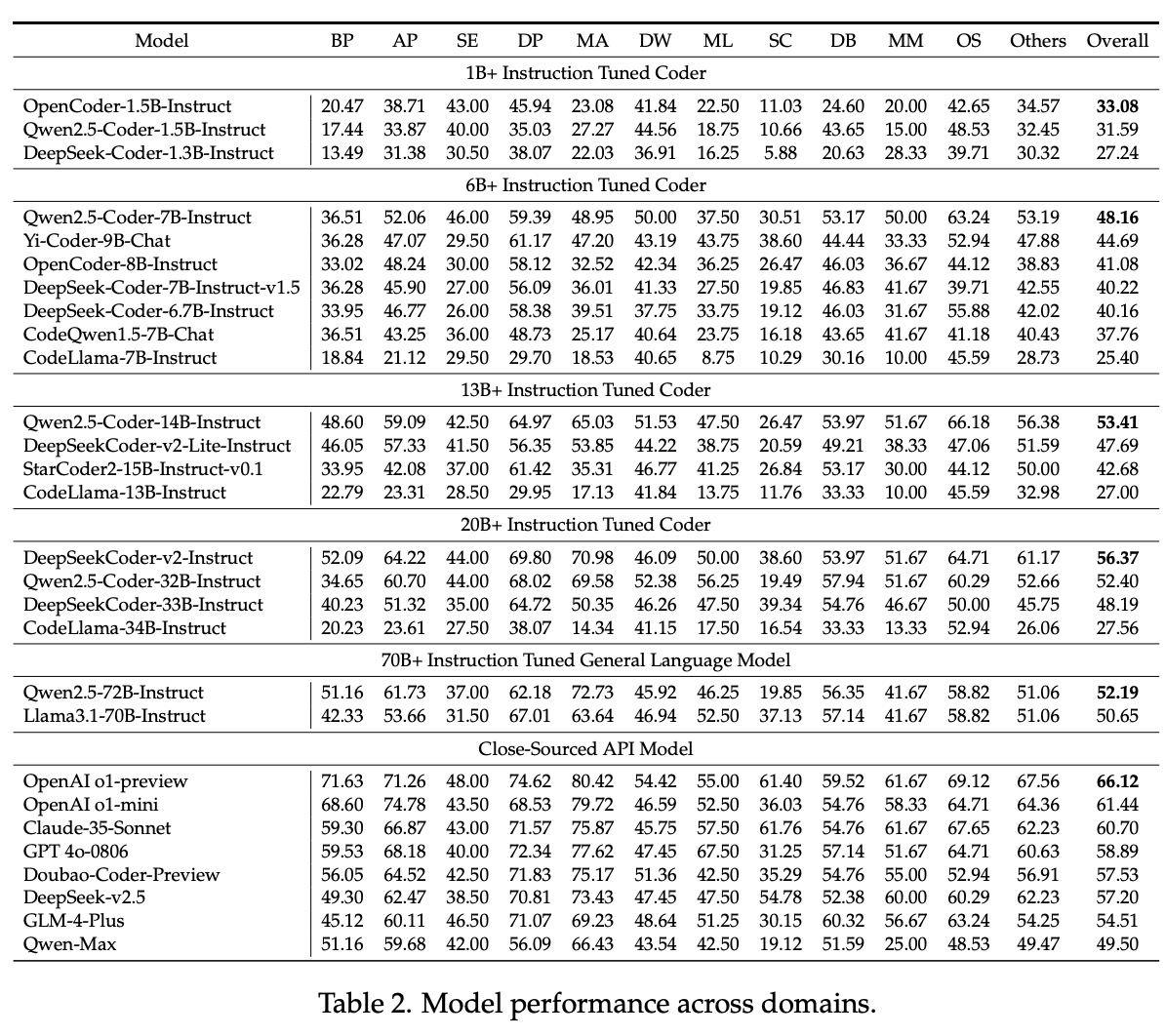
研究人員還分析了擴展法則,顯示增加參數通常會提高模型性能。然而,研究人員觀察到某些模型在更高的規模下性能下降。例如,Qwen2.5-Coder系列在14B參數時達到峰值,但在32B和72B時表現下降。這一發現強調了在優化LLM性能時平衡模型大小和效率的重要性。研究人員還觀察到程式碼編譯通過率與測試成功率之間存在正相關,強調了精確和無錯誤的程式碼生成的必要性。
FullStack Bench和SandboxFusion共同代表了評估LLMs的重要進展。通過解決現有基準的限制,這些工具使得能夠更全面地評估LLM在多樣領域和編程語言上的能力。這項研究為程式碼智能的進一步創新奠定了基礎,並強調了開發能準確反映現實編程場景的工具的重要性。
查看論文、FullStack Bench和SandboxFusion。這項研究的所有功勞都歸於這個項目的研究人員。此外,別忘了在Twitter上關注我們,加入我們的Telegram頻道和LinkedIn小組。如果你喜歡我們的工作,你一定會喜歡我們的電子報。別忘了加入我們的60k+ ML SubReddit。
🚨 [必參加的網路研討會]:‘將概念證明轉化為生產就緒的AI應用和代理’(推廣)
新聞來源
本文由 AI 台灣 使用 AI 編撰,內容僅供參考,請自行進行事實查核。加入 AI TAIWAN Google News,隨時掌握最新 AI 資訊!








{kind=link}