


在不斷發展的機器學習領域中,數據是最重要的燃料。但當你擁有有限的標記數據和大量未標記數據時,會發生什麼呢?這時,半監督學習 (Semi-Supervised Learning, SSL) 就派上用場了。
半監督學習在監督學習和非監督學習之間取得了完美的平衡,讓模型能夠做出準確的預測,同時減少數據標記的成本。
在這篇文章中,我們將介紹什麼是半監督學習、它的重要性、運作方式、實際應用,以及在使用時需要考慮的挑戰。
什麼是半監督學習?
半監督學習是一種機器學習方法,它使用少量的標記數據,結合大量的未標記數據來訓練模型。與完全依賴標記數據集的監督學習不同,和完全不使用標記數據的非監督學習相比,半監督學習處於中間位置。
為什麼這很重要?
因為標記數據的成本高、耗時長,並且通常需要專業知識。另一方面,收集原始的未標記數據要容易得多。半監督學習填補了這個空白,讓我們能夠在最少的標記數據下最大化模型的表現。
另請參閱:什麼是數據收集?
半監督學習是如何運作的?
典型的半監督學習過程遵循以下步驟:
- 開始時使用少量的標記數據:這些是模型可以直接學習的“真實數據”。
- 與大量未標記數據結合:這些是你擁有但沒有標記的數據點。
- 初步模型訓練:模型在標記數據上進行訓練。
- 偽標記:訓練好的模型為未標記數據預測標記。
- 重新訓練:使用原始的標記數據和偽標記數據重新訓練模型。
- 迭代和改進:這個循環持續進行,直到性能穩定或達到期望的水平。
這種方法利用了模型從少量高質量標記數據中概括的能力,並利用大量未標記數據擴展其學習。
為什麼使用半監督學習?
以下是半監督學習受到關注的一些主要原因:
- 降低標記成本:你不需要龐大的標記數據集。
- 提高模型準確性:當標記數據稀缺時,半監督學習通常比純監督模型表現更好。
- 可擴展性:隨著每天生成大量未標記數據(想想那些圖片、電子郵件或交易),半監督學習提供了一種實用的方法來利用這些數據。
- 適用於自然數據集:半監督學習對文本、圖片、語音和其他現實世界數據格式非常有效。
半監督學習的優缺點
半監督學習的優點:
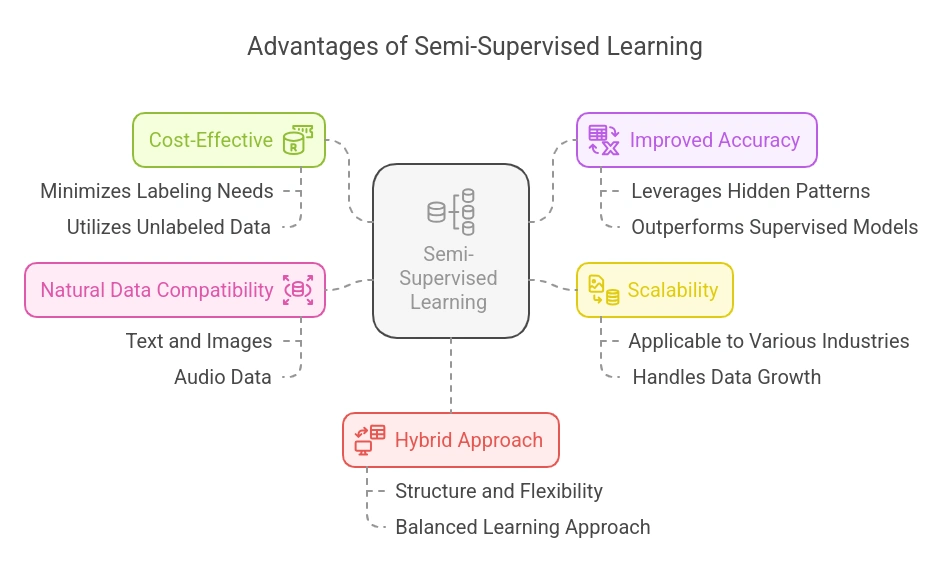
- 成本效益:標記大型數據集的成本高且耗時。半監督學習通過充分利用小型標記數據集和大量未標記數據來最小化這一需求。
- 用更少的數據提高準確性:當標記數據稀缺時,半監督學習通常能比純監督模型達到更好的準確性,因為它能利用未標記數據中的隱藏模式。
- 可擴展性:半監督學習在社交媒體、電子商務和醫療等產生大量原始未標記數據的行業中非常可擴展。
- 適用於自然數據:半監督學習算法在文本、圖片和音頻等複雜的現實世界數據集中表現良好,因為標記每個樣本是不切實際的。
- 結合兩者的優勢:通過融合監督和非監督技術,半監督學習繼承了兩種方法的優勢,平衡了結構與靈活性。
半監督學習的缺點:
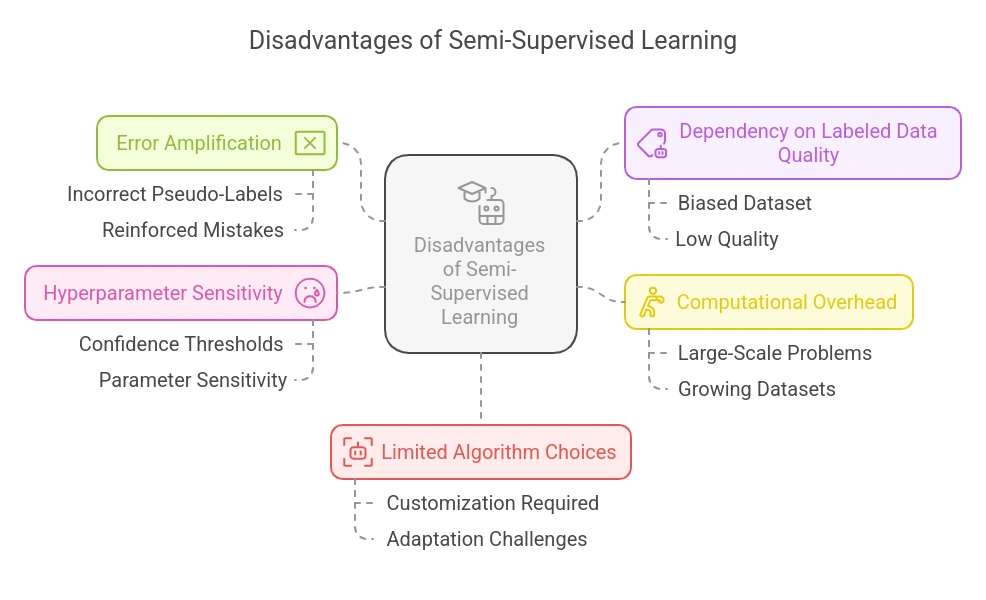
- 錯誤擴大:不正確的偽標記可能會引入噪音並加強錯誤,特別是在模型在早期迭代中自信地錯誤標記數據時。
- 對標記數據質量的依賴:如果小型標記數據集存在偏見或質量低,整個模型可能會偏斜,影響對新數據的概括能力。
- 計算開銷:在不斷增長的數據集(標記數據 + 偽標記數據)上重複訓練循環可能會變得計算上昂貴,特別是對於大規模問題。
- 超參數敏感性:半監督學習模型可能對信心閾值等參數敏感,這些參數控制哪些未標記數據被偽標記並重新用於訓練。
- 算法選擇有限:並非所有機器學習算法都能輕鬆適應半監督學習,有些需要大量定制。
半監督學習的實際應用
半監督學習不僅僅是理論,它在各行各業中被積極使用:
- 醫療:用少量範例診斷罕見疾病
- 電子商務:產品分類和推薦
- 網絡安全:檢測新類型的惡意軟件
- 自然語言處理:語言翻譯和情感分析
- 自動駕駛汽車:有限標記圖片的物體識別
流行的半監督學習算法
一些廣泛使用的算法包括:
- 自我訓練:模型標記未標記數據並重新訓練自己。
- 共同訓練:兩個模型在不同的特徵集上進行訓練,並幫助標記彼此的數據。
- 基於圖的方法:將數據表示為圖形,並通過連接的節點傳播標記。
- 生成模型:如半監督生成對抗網絡 (Semi-Supervised GANs)。
半監督學習的挑戰
儘管潛力巨大,半監督學習仍面臨挑戰:
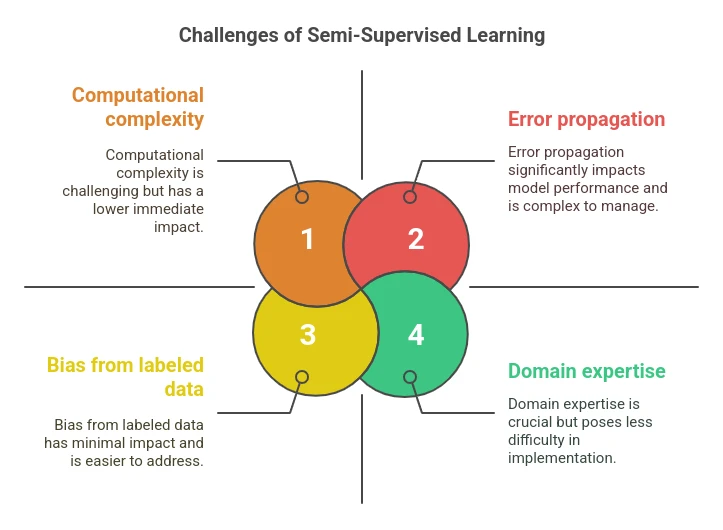
- 錯誤傳播:不正確的偽標記可能會降低模型性能。
- 標記數據的偏見:小型、不平衡的標記數據集可能會使整個模型偏斜。
- 計算複雜性:處理大型數據集的迭代重新訓練可能會變得昂貴。
- 領域專業知識:即使是初始的標記數據也必須是高質量的,以避免錯誤的累積。
半監督學習的未來
隨著數據的爆炸性增長和數據標記成本的上升,半監督學習變得比以往任何時候都更重要。隨著算法變得越來越複雜,半監督學習將在以下領域發揮核心作用:
此外,它還補充了其他學習範式,如主動學習和轉移學習,推動機器在最少人為干預下能夠實現的邊界。
想在人工智慧 (AI) 和機器學習 (ML) 領域建立成功的職業生涯嗎?報名參加這個 AI 和 ML 課程,獲得生成式 AI、MLOps、監督學習和非監督學習等尖端技術的專業知識。通過實踐項目和專門的職業支持,獲得證書,開始你的 AI 之旅吧!
常見問題 (FAQ)
1. 如何決定半監督學習中標記數據和未標記數據的比例?
沒有一個適合所有的比例,但在實踐中,當標記數據剛好足夠引導初步學習時,模型通常表現良好——有時甚至只需總數據集的 1-10%。理想的比例取決於問題的複雜性、模型類型和標記數據的質量。
2. 半監督學習適合實時系統嗎?
半監督學習可以用於實時系統,但這更具挑戰性,因為偽標記和重新訓練步驟可能計算上非常密集。對於實時應用,輕量級的半監督技術或增量學習策略更受青睞。
3. 如何驗證半監督學習中偽標記的質量?
偽標記質量通常使用信心閾值來評估。只有具有高信心分數的預測才會被重新加入訓練,以最小化錯誤傳播的風險。有些模型在關鍵階段還會使用人工驗證。
4. 半監督學習能處理噪音數據嗎?
半監督學習可以處理一些噪音,但如果標記和未標記數據集都存在噪音,錯誤擴散的風險會增加。常用的技術包括噪音過濾、穩健的損失函數和驗證循環。
5. 半監督學習與主動學習相比如何?
半監督學習自動利用未標記數據,並且人為干預最小,而主動學習則選擇最具信息量的數據點並主動詢問人類標記。這兩種方法都旨在降低標記成本,但在方法上有所不同,有時甚至會結合使用以獲得更好的結果。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}