


鏈式思考提示(Chain-of-Thought, CoT)讓大型語言模型(LLMs)能夠在自然語言中進行逐步的邏輯推理。雖然這種方法已經證明有效,但自然語言可能不是推理的最佳媒介。研究顯示,人類的數學推理並不主要依賴語言處理,這意味著其他方法可能能提高表現。研究人員的目標是改善LLMs的推理處理方式,平衡準確性和計算效率。
LLMs在推理方面的挑戰源於它們對明確的鏈式思考的依賴,這需要在得出最終答案之前生成詳細的解釋。這種方法增加了計算負擔,並減慢了推理速度。隱式鏈式思考方法試圖在不生成明確推理標記的情況下內化推理,但這些方法在歷史上表現不如明確的鏈式思考。設計能夠有效內部處理推理的模型同時保持準確性是一個主要障礙。找到一種解決方案,消除過多的計算負擔而不影響性能,對於擴展LLMs的推理能力至關重要。
之前的隱式鏈式思考方法主要依賴課程學習策略,這些策略逐步內化推理步驟。其中一種方法,名為Coconut,逐漸用連續表示替代明確的鏈式思考標記,同時保持語言建模的目標。然而,這種方法有其限制,包括錯誤傳播和訓練過程中的逐漸遺忘。因此,儘管Coconut在基準模型上有所改進,但仍然顯著落後於明確的鏈式思考方法。隱式鏈式思考方法始終未能達到明確生成的鏈式思考的推理表現。
來自倫敦國王學院(King’s College London)和艾倫·圖靈研究所(The Alan Turing Institute)的研究人員提出了CODI(透過自我蒸餾的連續鏈式思考)作為一種新框架,以解決這些限制。CODI將明確的鏈式思考推理蒸餾到一個連續空間,讓LLMs能夠在內部進行邏輯推理,而無需生成明確的鏈式思考標記。這種方法使用自我蒸餾,其中一個模型同時充當教師和學生,對齊它們的隱藏激活,以在緊湊的潛在空間中編碼推理。通過利用這項技術,CODI有效地壓縮推理而不犧牲性能。
CODI包含兩個關鍵學習任務:明確的鏈式思考生成和連續的鏈式思考推理。教師模型遵循標準的鏈式思考學習,逐步處理自然語言推理並生成明確的鏈式思考序列。相比之下,學生模型學會在緊湊的潛在表示中內化推理。為了確保知識的正確轉移,CODI強制這兩個過程之間的對齊,使用L1距離損失函數。與之前的方法不同,CODI直接將推理監督注入模型的隱藏狀態中,實現更高效的訓練。CODI採用單步蒸餾方法,而不是依賴多個訓練階段,確保最小化課程學習中固有的信息損失和遺忘問題。這個過程涉及選擇一個特定的隱藏標記,編碼關鍵的推理信息,使模型能夠有效生成連續的推理步驟,而無需明確的標記。
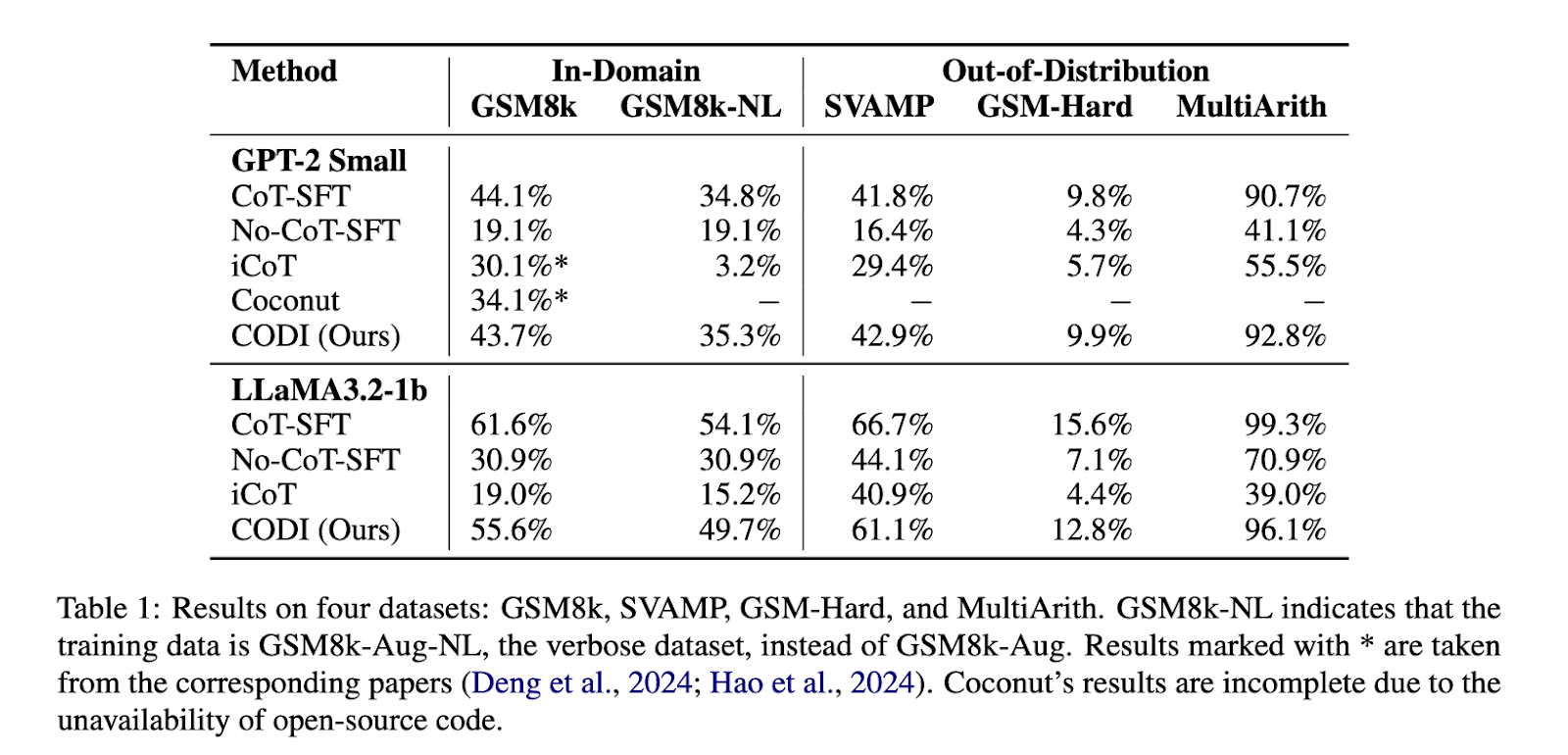
實驗結果顯示,CODI顯著超越了之前的隱式鏈式思考方法,並且是第一個在數學推理任務中達到明確鏈式思考準確性的模型。在GSM8k數據集上,CODI實現了3.1倍的壓縮比,同時保持與明確鏈式思考相當的性能。它的準確性比Coconut高出28.2%。此外,CODI具有可擴展性,能夠適應各種鏈式思考數據集,適合更複雜的推理問題。性能基準顯示,CODI在GSM8k上以GPT-2模型達到43.7%的推理準確性,而Coconut則為34.1%。在更大的模型如LLaMA3.2-1b上測試時,CODI達到了55.6%的準確性,顯示其有效的擴展能力。在效率方面,CODI的推理步驟處理速度比傳統的鏈式思考快2.7倍,當應用於更冗長的推理數據集時,速度快5.9倍。其穩健的設計使其能夠在不同領域的基準上進行泛化,並在SVAMP和MultiArith等數據集上超越了CoT-SFT。

CODI標誌著LLM推理的一次重大進步,有效地縮小了明確鏈式思考和計算效率之間的差距。利用自我蒸餾和連續表示,為人工智慧推理引入了一種可擴展的方法。該模型保持可解釋性,因為其連續的思考可以解碼為結構化的推理模式,提供決策過程的透明度。未來的研究可以探索CODI在更複雜的多模態推理任務中的應用,擴大其在數學問題解決之外的好處。這個框架確立了隱式鏈式思考作為一種計算效率高的替代方案,並為先進人工智慧系統中的推理挑戰提供了可行的解決方案。
查看論文。所有的研究功勞都歸於這個項目的研究人員。此外,隨時在Twitter上關注我們,別忘了加入我們的80k+機器學習SubReddit。
🚨 介紹Parlant:一個以LLM為首的對話式人工智慧框架,旨在為開發者提供對其人工智慧客服代理的控制和精確度,利用行為指導和運行時監督。🔧 🎛️ 它使用易於使用的命令行界面(CLI)📟和Python及TypeScript的原生客戶端SDK📦。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!



")




{kind=link}