


圖卷積網絡(GCNs)在分析複雜的圖結構數據中已成為不可或缺的一部分。這些網絡捕捉了節點及其屬性之間的關係,使其在社交網絡分析、生物學和化學等領域中不可或缺。通過利用圖結構,GCNs 能夠實現節點分類和鏈接預測任務,促進科學和工業應用的進步。
大規模圖訓練面臨著重大挑戰,特別是在保持效率和可擴展性方面。由於圖的稀疏性導致的不規則內存訪問模式以及分佈式訓練所需的大量通信,難以實現最佳性能。此外,將圖劃分為子圖以進行分佈式計算會產生不均衡的工作負載和增加的通信開銷,進一步複雜化訓練過程。解決這些挑戰對於在大規模數據集上訓練 GCNs 至關重要。
現有的 GCN 訓練方法包括小批量和全批量方法。小批量訓練通過抽樣較小的子圖來減少內存使用,使計算能夠適應有限的資源。然而,這種方法往往犧牲準確性,因為它需要保留圖的完整結構。全批量訓練在保留圖的結構時,由於增加的內存和通信需求而面臨可擴展性問題。當前大多數框架優化了 GPU 平台,但對於開發針對 CPU 基礎系統的高效解決方案的關注有限。
研究團隊包括來自東京工業大學、RIKEN、國立先進工業科學技術研究所和洛倫斯利物摩國家實驗室的合作者,已推出一個名為 SuperGCN 的新框架。該系統專為 CPU 驅動的超級計算機而設,解決了 GCN 訓練中的可擴展性和效率挑戰。該框架通過專注於優化的圖相關操作和通信減少技術,彌補了分佈式圖學習中的空白。
SuperGCN 利用幾種創新技術來提升其性能。該框架採用針對 CPU 的圖操作的優化實現,確保了高效的內存使用和線程之間的工作負載平衡。研究人員提出了一種混合聚合策略,使用最小頂點覆蓋算法將邊分類為聚合前和聚合後的集合,以減少冗餘通信。此外,該框架還整合了 Int2 量化技術,在通信過程中壓縮消息,顯著降低了數據傳輸量而沒有損害準確性。標籤傳播與量化一起使用,以減輕精度降低的影響,確保收斂並維持高模型準確性。
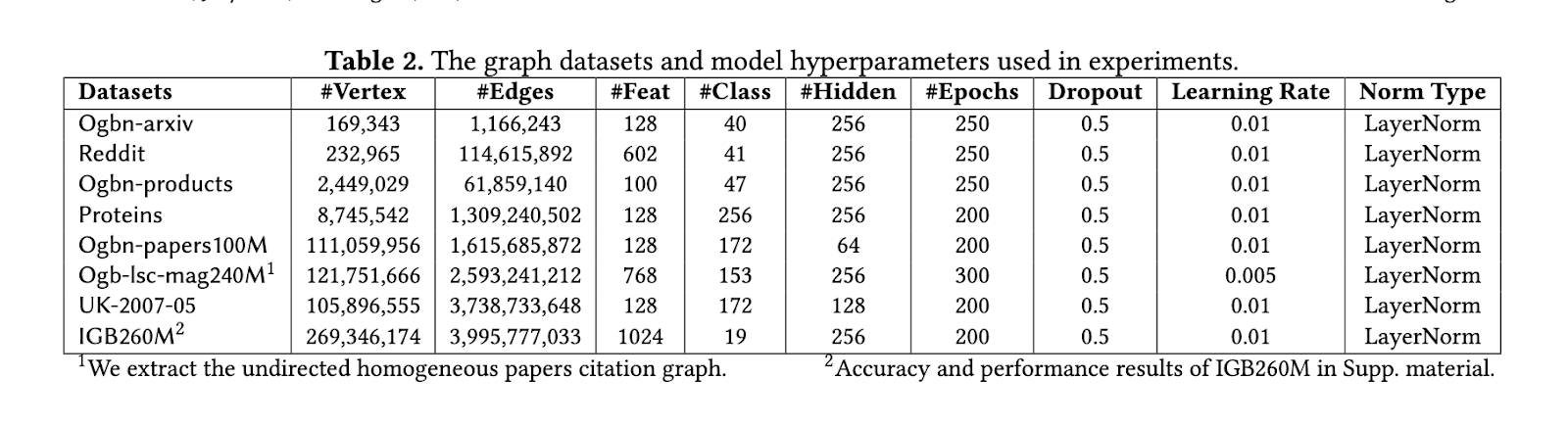
SuperGCN 的性能在 Ogbn-products、Reddit 和大規模 Ogbn-papers100M 等數據集上進行了評估,顯示出相比現有方法的顯著改進。該框架在基於 Intel 的 Xeon 系統上相比 DistGNN 實現了最多六倍的加速,並且隨著處理器數量的增加,性能呈線性擴展。在像 Fugaku 這樣的 ARM 基礎超級計算機上,SuperGCN 擴展到超過 8,000 個處理器,展示了 CPU 平台上無與倫比的可擴展性。該框架實現的處理速度可與 GPU 驅動的系統相媲美,並且所需的能量和成本顯著更低。在 Ogbn-papers100M 上,SuperGCN 在啟用標籤傳播的情況下達到了 65.82% 的準確率,超越了其他基於 CPU 的方法。
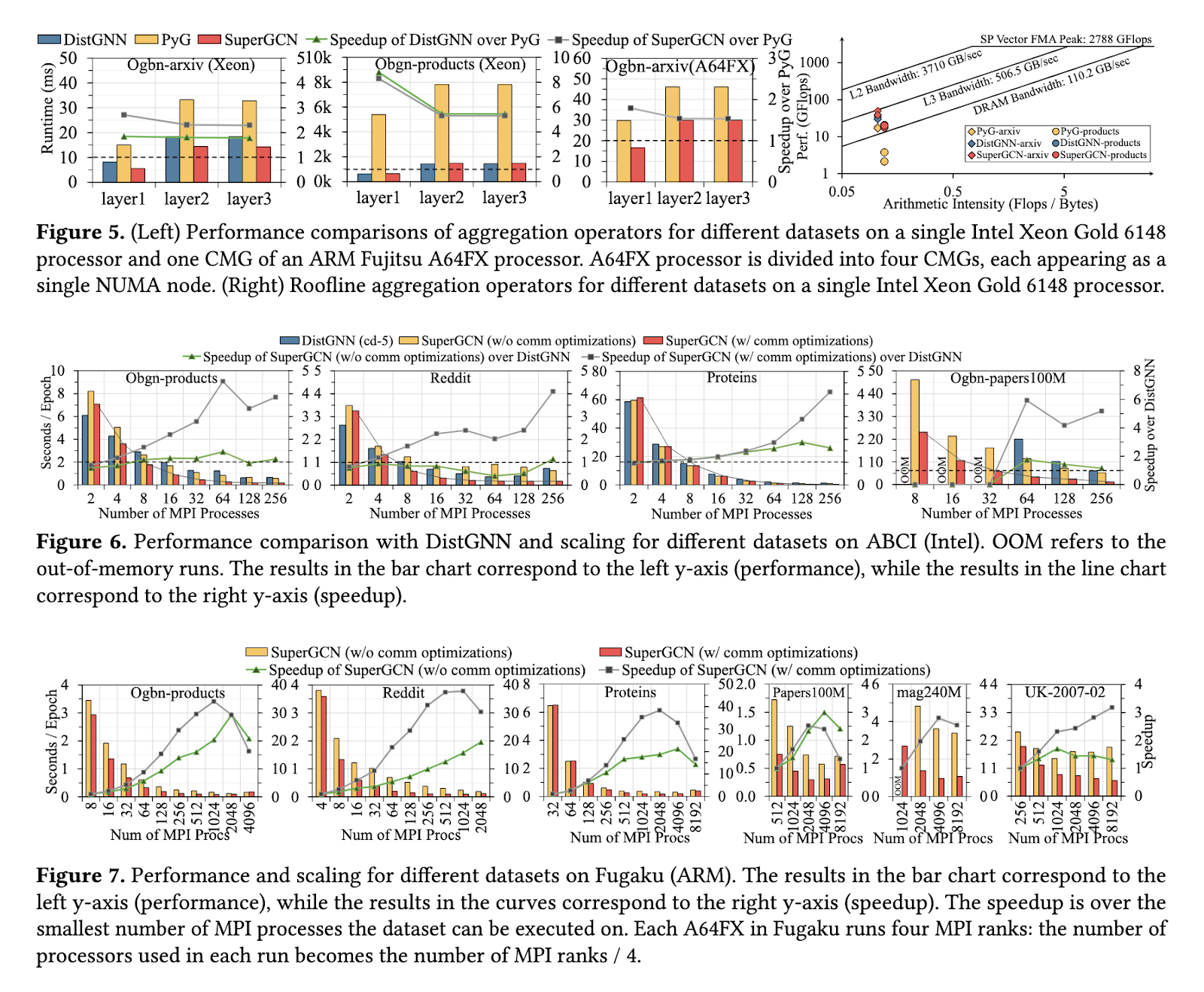
通過引入 SuperGCN,研究人員解決了分佈式 GCN 訓練中的關鍵瓶頸。他們的工作證明了在 CPU 驅動的平台上可以實現高效、可擴展的解決方案,提供了 GPU 基礎系統的成本效益替代方案。這一進展標誌著在保護計算和環境可持續性的同時,使大規模圖處理成為可能的重要一步。
查看論文。此研究的所有功勞都歸於這個項目的研究人員。此外,別忘了在 Twitter 上關注我們,並加入我們的 Telegram 頻道和 LinkedIn 群組。如果你喜歡我們的工作,你一定會喜歡我們的新聞通訊。別忘了加入我們的 55k+ ML 子 Reddit。
🎙️ 🚨 ‘大型語言模型漏洞評估:紅隊技術的比較分析’ 閱讀完整報告(推廣)






")

{kind=link}