


大型語言模型 (LLMs) 使用大量計算資源來處理和生成類似人類的文本。最近出現的一種技術稱為「測試時擴展」,它在推理過程中動態分配計算資源,目的是增強 LLM 的推理能力。這種方法希望通過改善模型的推理過程來提高回答的準確性。隨著像 OpenAI 的 o1 系列引入測試時擴展,研究人員開始探討較長的推理鏈是否能提高表現,或者是否有其他策略能獲得更好的結果。
在 AI 模型中擴展推理是一個重大挑戰,特別是在較長的思考鏈不一定能帶來更好結果的情況下。研究人員質疑增加回答長度是否真的能提高準確性,因為他們發現較長的解釋可能會引入不一致性。隨著推理鏈的延長,錯誤會累積,模型經常進行不必要的自我修正,導致表現下降而不是改善。如果測試時擴展要成為有效的解決方案,就必須平衡推理的深度與準確性,確保計算資源的有效使用,而不降低模型的效能。
目前的測試時擴展方法主要分為順序和並行兩類。順序擴展在推理過程中延長思考鏈 (CoT),期望更長的推理能提高準確性。然而,對於像 QwQ、Deepseek-R1 (R1) 和 LIMO 等模型的研究顯示,延長思考鏈並不總是能帶來更好的結果。這些模型經常使用自我修正,導致冗餘計算,降低了性能。相對而言,並行擴展同時生成多個解決方案,並根據預定標準選擇最佳解決方案。比較分析表明,並行擴展在維持準確性和效率方面更為有效。
來自復旦大學和上海人工智慧實驗室的研究人員提出了一種創新的方法,稱為「最短多數投票」,以解決順序擴展的局限性。這種方法通過利用並行計算來優化測試時擴展,同時考慮解決方案的長度。這種方法的主要見解是,較短的解決方案往往比較長的更準確,因為它們包含較少的不必要自我修正。通過將解決方案的長度納入多數投票過程,這種方法通過優先考慮頻繁且簡潔的答案來提升模型的表現。
這種方法修改了傳統的多數投票,考慮了解決方案的數量和長度。傳統的多數投票選擇生成的解決方案中出現頻率最高的答案,而最短多數投票則對出現頻繁且較短的答案賦予更高的優先權。這種方法的推理是,較長的解決方案由於過多的自我修正,往往會引入更多的錯誤。研究人員發現,當 QwQ、R1 和 LIMO 被要求改進其解決方案時,生成的回答會越來越長,通常會導致準確性降低。這種方法旨在過濾掉不必要的延伸,並通過將長度作為標準來優先考慮更精確的答案。
實驗評估顯示,最短多數投票方法在多個基準測試中顯著超越了傳統的多數投票。在 AIME 數據集上,採用這種技術的模型相比現有的測試時擴展方法顯示出準確性提升。例如,R1-Distill-32b 的準確性提高到 72.88%,而傳統方法則未達到這一水平。同樣,QwQ 和 LIMO 也顯示出增強的性能,特別是在之前延長推理鏈導致不一致的情況下。這些發現表明,認為較長的解決方案總能帶來更好結果的假設是錯誤的。相反,結構化且高效的方法,優先考慮簡潔性,能夠帶來更好的表現。
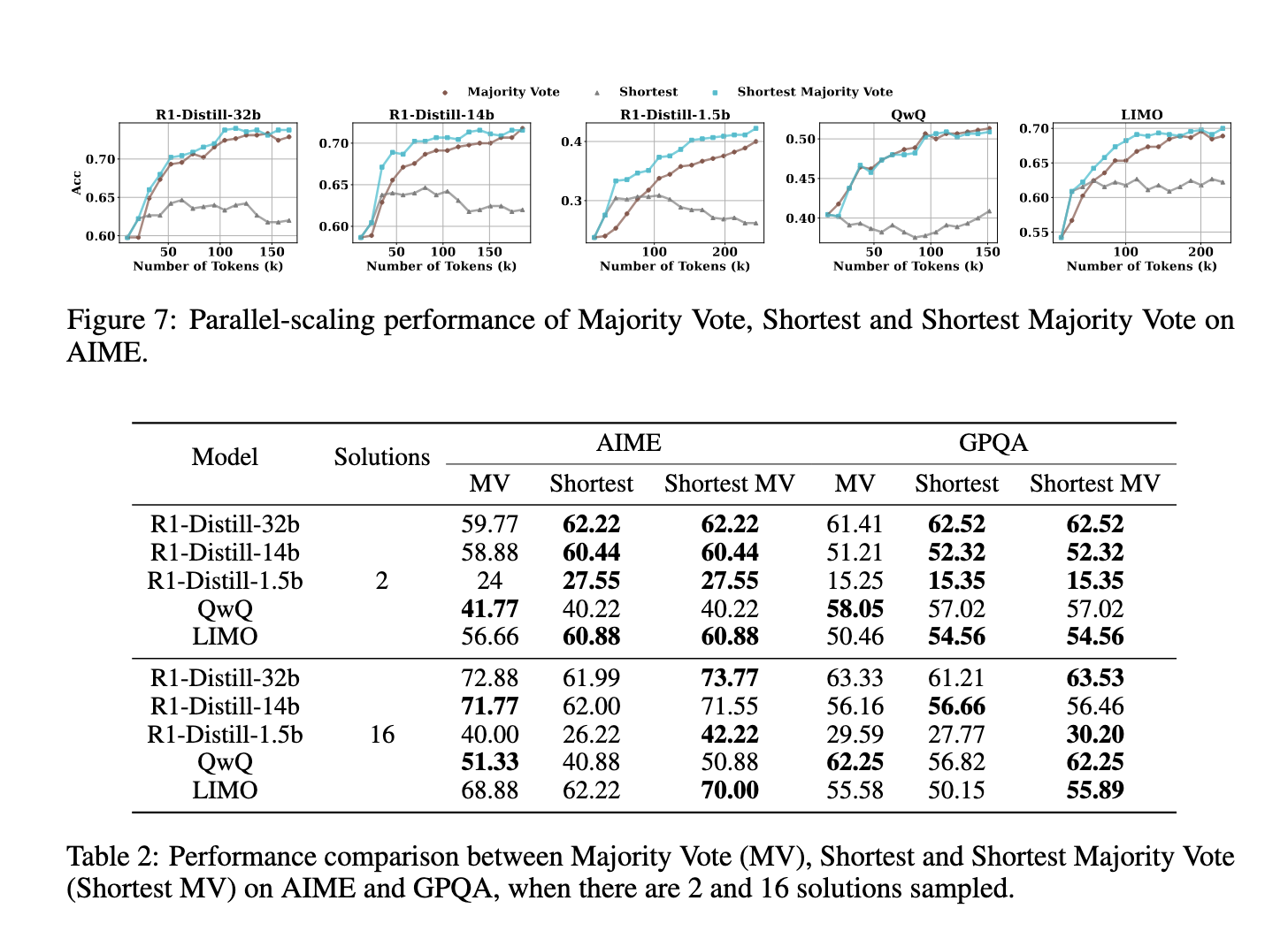
結果還顯示,順序擴展面臨收益遞減的問題。雖然初步的修正可能有助於改善回答,但過多的修正往往會引入錯誤,而不是糾正它們。特別是像 QwQ 和 R1-Distill-1.5b 這樣的模型,往往會將正確的答案改變為錯誤的,而不是提高準確性。這一現象進一步突顯了順序擴展的局限性,強調了需要更結構化的方法,例如最短多數投票,以優化測試時擴展。
這項研究強調了重新思考大型語言模型中測試時擴展應用的必要性。研究結果顯示,與其假設延長推理鏈會提高準確性,不如優先考慮簡潔且高質量的解決方案,通過並行擴展來達成更有效的策略。最短多數投票的引入提供了一種實用且經過實證驗證的改進,為優化 LLM 中的計算效率提供了一種精緻的方法。通過專注於結構化推理,而不是過度的自我修正,這種方法為更可靠和準確的 AI 驅動決策鋪平了道路。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!



")




{kind=link}