


知識圖譜(KGs)是人工智慧應用的基礎,但目前仍不完整且稀疏,影響其效能。像是 DBpedia 和 Wikidata 等成熟的知識圖譜缺少重要的實體關係,這使得它們在檢索增強生成(RAG)和其他機器學習任務中的效用降低。傳統的提取方法往往會產生稀疏的圖譜,缺少重要的連結,或是出現噪音和冗餘的表示。因此,從非結構化文本中獲得高品質的結構化知識變得困難。克服這些挑戰對於提升知識檢索、推理和洞察力至關重要,並且需要人工智慧的協助。
目前最先進的從原始文本中提取知識圖譜的方法有開放資訊提取(Open Information Extraction, OpenIE)和 GraphRAG。OpenIE 是一種依賴解析技術,能生成結構化的(主題、關係、對象)三元組,但會產生極其複雜和冗餘的節點,降低了連貫性。GraphRAG 結合了基於圖的檢索和語言模型,增強了實體連結,但無法生成密集連接的圖譜,限制了下游推理過程。這兩種技術都面臨著實體解析一致性低、連接稀疏和可泛化性差的問題,使得它們在高品質知識圖譜提取上無法有效運作。
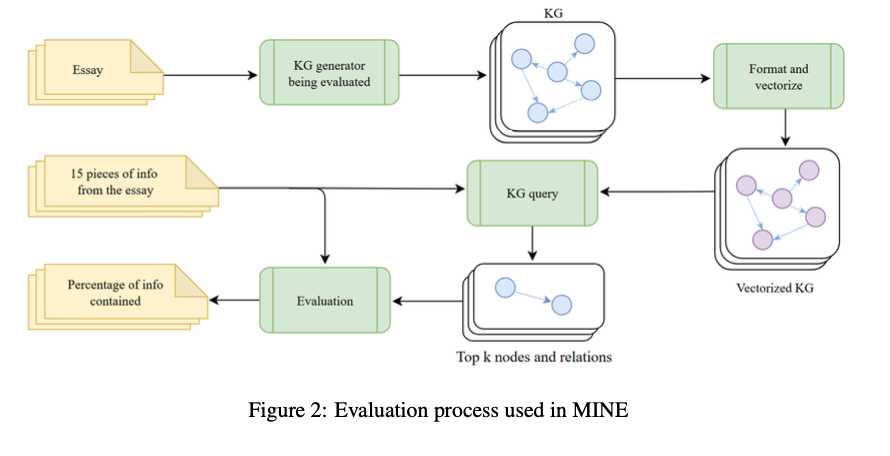
來自史丹佛大學(Stanford University)、多倫多大學(University of Toronto)和 FAR AI 的研究人員推出了 KGGen,這是一種新型的文本到知識圖譜生成器,利用語言模型和聚類算法從純文本中提取結構化知識。與早期的方法不同,KGGen 引入了一種基於語言模型的迭代聚類方法,通過合併同義實體和分組關係來增強提取的圖譜,這樣可以減少稀疏性和冗餘性,提供更具連貫性和良好連接的知識圖譜。KGGen 還引入了 MINE(節點和邊的資訊度量),這是第一個用於文本到知識圖譜提取性能的基準,能夠標準化測量提取方法的效果。
KGGen 通過一個模組化的 Python 套件運作,該套件包含實體和關係提取、聚合以及實體和邊的聚類模組。實體和關係提取模組使用 GPT-4o 從非結構化文本中獲得結構化的三元組(主題、謂詞、對象)。聚合模組將來自不同來源的提取三元組合併成一個統一的知識圖譜,確保實體的同質性表示。實體和邊的聚類模組使用迭代聚類算法來消歧同義實體、聚類相似邊並增強圖譜的連接性。通過使用 DSPy 對語言模型施加嚴格的約束,KGGen 能夠實現結構化和高保真的提取。輸出的知識圖譜以其密集的連接性、語義相關性和針對人工智慧的優化而著稱。
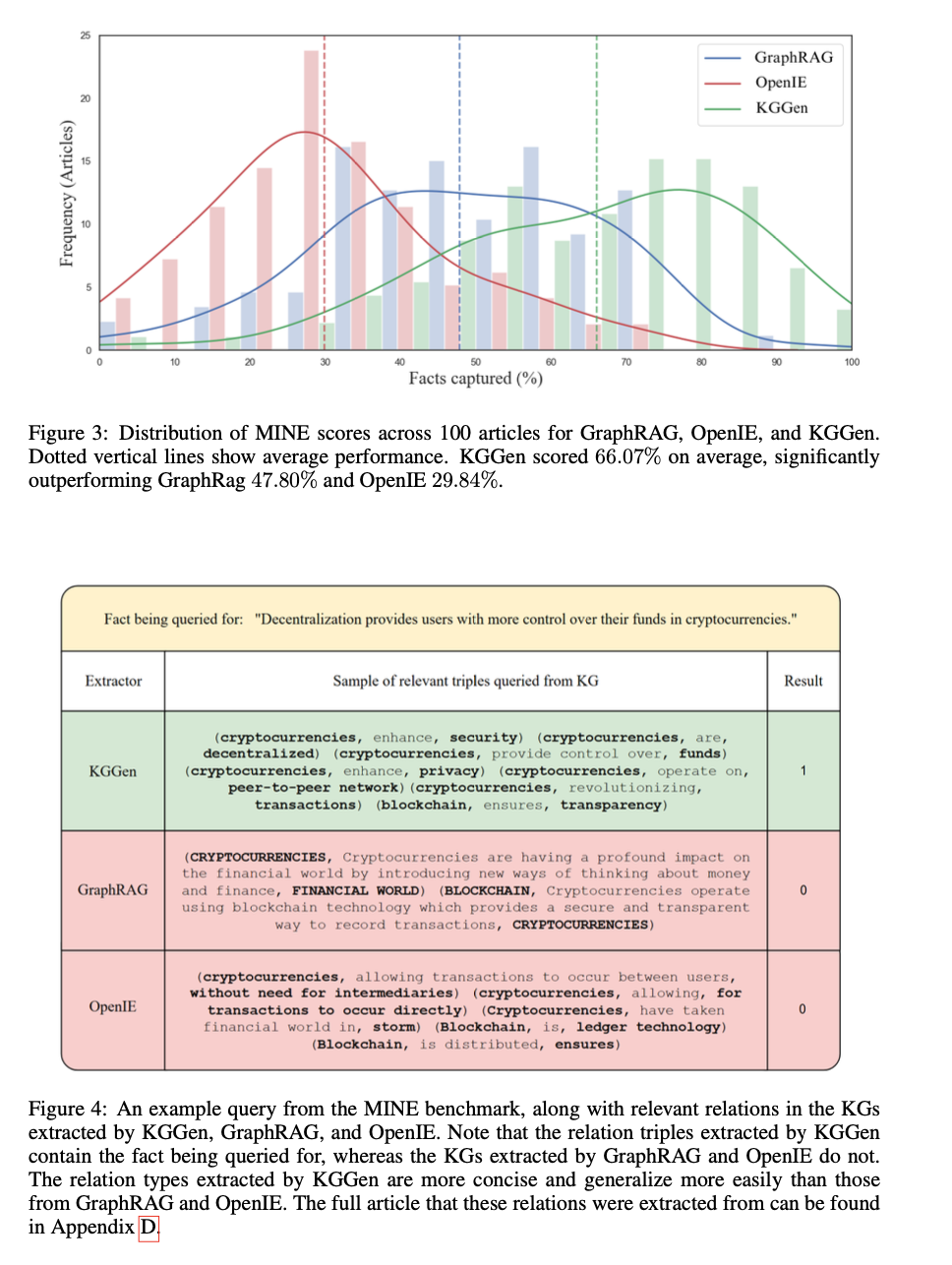
基準測試的結果顯示該方法在從文本來源提取結構化知識方面的成功。KGGen 的準確率為 66.07%,顯著高於 GraphRAG 的 47.80% 和 OpenIE 的 29.84%。該系統能夠提取和結構化知識,避免冗餘,增強連接性和連貫性。比較分析確認其提取的保真度比現有方法提高了 18%,突顯了其生成良好結構知識圖譜的能力。測試還顯示,生成的圖譜更密集且更具資訊性,使其特別適合用於知識檢索任務和基於人工智慧的推理。
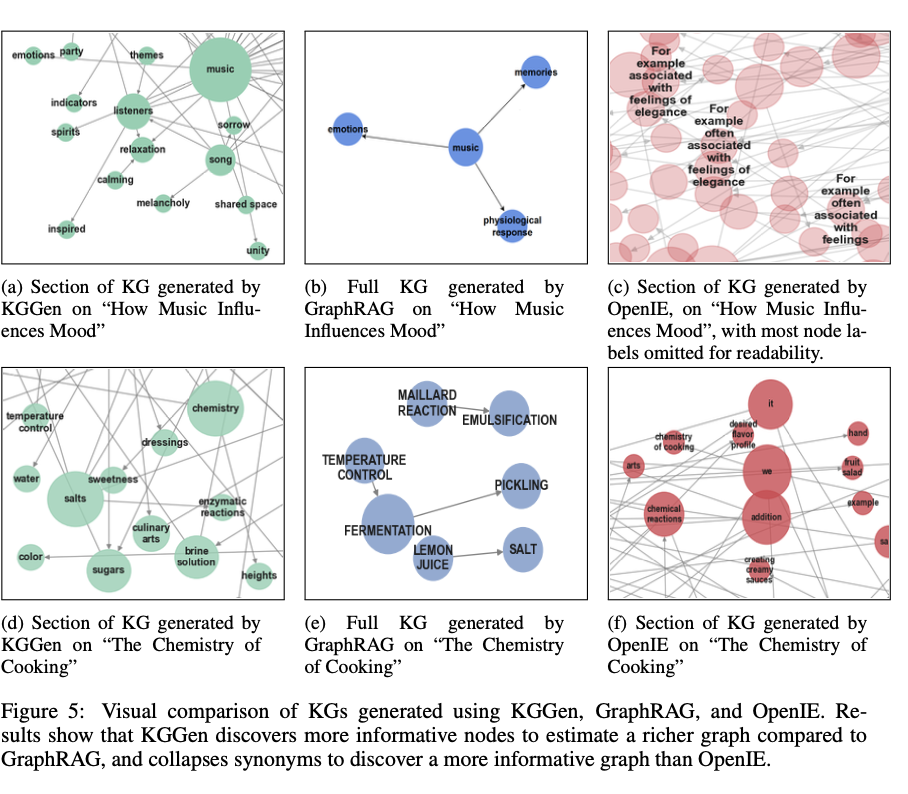
KGGen 是知識圖譜提取領域的一項突破,因為它結合了基於語言模型的實體識別和迭代聚類技術,以生成更高品質的結構化數據。通過在 MINE 基準上取得顯著提高的準確性,它為將非結構化文本轉換為有影響力的表示設立了新標準。這一突破對於基於人工智慧的知識檢索、推理操作和嵌入式學習具有深遠的影響,為進一步發展更大更全面的知識圖譜鋪平了道路。未來的發展將專注於完善聚類技術和擴展基準測試,以涵蓋更大的數據集。
查看這篇論文。所有的研究成果都歸功於這個項目的研究人員。此外,隨時歡迎在 Twitter 上關注我們,別忘了加入我們的 75k+ 機器學習 SubReddit。
🚨 推薦閱讀 – LG AI 研究發布 NEXUS:一個先進的系統,整合代理人工智慧系統和數據合規標準,以解決人工智慧數據集中的法律問題。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}