


在多代理環境中,人工智慧(AI)取得了顯著的進展,尤其是在強化學習方面。這個領域的一個核心挑戰是開發能夠通過自然語言有效溝通的AI代理。這在每個代理只能部分了解環境的情況下尤為重要,因為分享知識對於達成共同目標至關重要。社交推理遊戲提供了一個理想的框架來測試AI通過對話推斷信息的能力,因為這些遊戲需要推理、識別欺騙和戰略合作。
在AI驅動的社交推理中,一個關鍵問題是確保代理能夠進行有意義的討論,而不依賴於人類的示範。許多語言模型在多代理環境中表現不佳,因為它們依賴於大量人類對話的數據集。隨著AI代理難以評估他們的貢獻是否對決策有意義,挑戰變得更加嚴峻。沒有明確的機制來評估他們信息的有用性,這使得它們經常產生無結構且無效的溝通,導致在需要推理和說服的戰略遊戲中表現不佳。
現有的強化學習方法試圖解決這個問題,但經常未能達到預期效果。一些技術依賴於現有的人類互動數據集,而這些數據集並不總是可用或能適應新情境。另一些則將語言模型與強化學習結合,但由於反饋稀疏,AI難以改進其對話策略。因此,傳統方法無法系統性地提高溝通技巧,使得AI在多代理環境中的討論效果不佳。
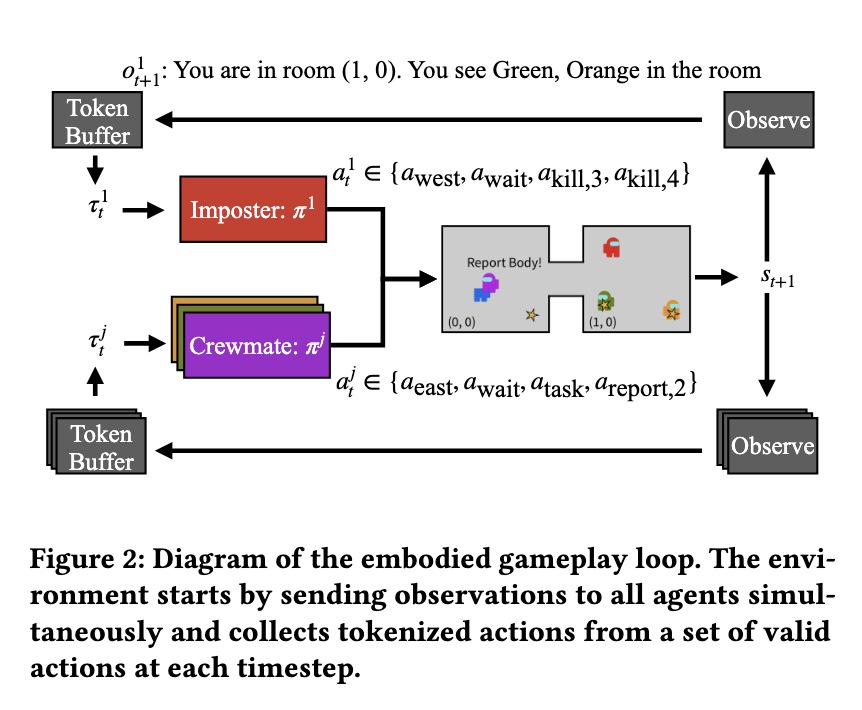
來自史丹佛大學(Stanford University)的一個研究團隊提出了一種創新的方法,旨在無需人類示範的情況下訓練AI代理進行社交推理。他們的方法利用多代理強化學習來開發能夠理解和表達有意義論點的AI。研究專注於遊戲《在我們之中》(Among Us),在這個遊戲中,船員必須通過口頭討論來識別冒名頂替者。研究人員設計了一種訓練機制,將溝通分為聆聽和發言,讓AI能夠獨立優化這兩項技能。該方法整合了一個結構化的獎勵系統,逐步使代理能夠改進其討論技巧。
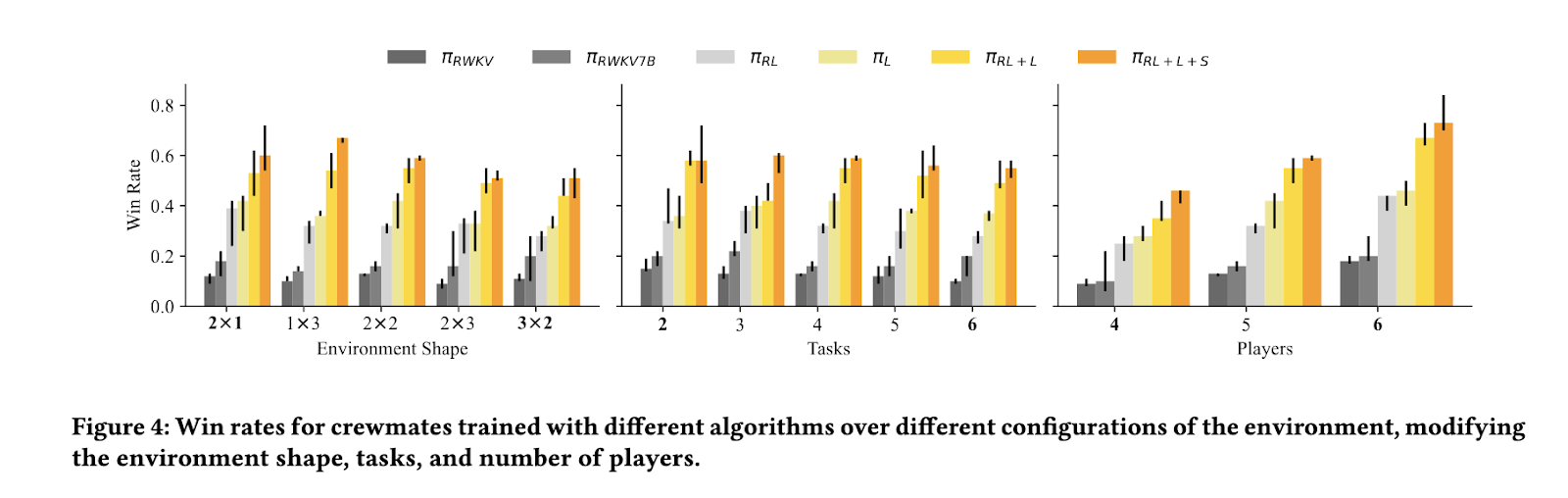
實驗結果顯示,這種訓練方法顯著提高了AI的表現,相較於傳統的強化學習技術,訓練後的AI展現出類似人類玩家的行為,包括懷疑指控、證據呈現和基於觀察行為的推理。研究顯示,使用這種結構化討論學習框架的AI模型的勝率約為56%,而沒有結構化對話框架的強化學習模型的勝率僅為28%。此外,使用這種方法訓練的AI在表現上超越了四倍大小的模型,突顯了所提訓練策略的效率。在分析討論行為時,研究團隊觀察到AI能夠以兩倍於基線強化學習方法的成功率準確識別冒名頂替者。
進一步分析顯示,在這個框架下訓練的AI模型能夠有效適應對抗策略。冒名頂替者試圖通過轉移責任來操縱討論,最初使AI船員感到困惑。然而,AI代理通過反覆訓練學會區分真實指控和誤導性陳述。研究人員發現,明確指出嫌疑人的AI生成消息更有可能影響群體決策。這種新興行為與人類直覺非常相似,顯示出AI能夠動態調整討論策略。
這項研究標誌著AI驅動的社交推理的一個重要進展。通過解決多代理環境中的溝通挑戰,這項研究提供了一個結構化且有效的框架,來訓練AI代理進行有意義的討論,而不依賴於大量的人類示範。所提方法增強了AI的決策能力,使其在需要合作和識別欺騙的環境中能進行更具說服力和邏輯性的推理。這項研究為更廣泛的應用開啟了可能性,包括能夠分析複雜討論、進行談判和策劃的AI助手。
查看論文。所有研究的榮譽歸於這個項目的研究人員。此外,隨時關注我們的Twitter,並別忘了加入我們的75k+ ML SubReddit。
🚨 推薦閱讀 – LG AI研究發布NEXUS:一個先進的系統,整合代理AI系統和數據合規標準,以解決AI數據集中的法律問題。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}