
:一個可擴展的機器學習框架以增強推理能力")

強化學習 (Reinforcement Learning, RL) 在大型語言模型 (Large Language Models, LLMs) 的應用上,傳統上依賴於基於結果的獎勵,這種獎勵只對最終結果提供反饋。這種獎勵稀疏的情況使得訓練需要多步推理的模型變得困難,例如數學問題解決和程式設計的模型。此外,信用分配變得模糊,因為模型對中間步驟沒有細緻的反饋。過程獎勵模型 (Process Reward Models, PRMs) 嘗試通過提供密集的逐步獎勵來解決這個問題,但它們需要昂貴的人為標註過程標籤,這使得它們在大規模強化學習中不可行。此外,靜態獎勵函數容易出現過度優化和獎勵黑客的問題,模型可能以意想不到的方式利用獎勵系統,最終影響模型的泛化性能。這些限制降低了強化學習在大型語言模型中的效率、可擴展性和應用性,因此需要一種新的解決方案,能夠有效結合密集獎勵而不需要高計算成本或人為標註。
現有的針對大型語言模型的強化學習方法大多使用基於結果的獎勵模型 (Outcome Reward Models, ORMs),這些模型僅對最終結果提供分數。這導致樣本效率低,因為模型必須生成和測試整個序列才能獲得反饋。一些方法使用價值模型來估計過去行動的未來獎勵,以對抗這種情況。然而,這些模型的變異性高,無法妥善處理獎勵稀疏的問題。PRMs 提供了更細緻的反饋,但需要昂貴的手動標註中間步驟,並且由於靜態獎勵函數的原因,容易出現獎勵黑客的情況。此外,大多數現有方法需要額外的訓練階段來訓練獎勵模型,增加了計算成本,使其在可擴展的在線強化學習中變得不可行。
來自清華大學 (Tsinghua University)、上海人工智慧實驗室 (Shanghai AI Lab)、伊利諾伊大學香檳分校 (University of Illinois Urbana-Champaign)、北京大學 (Peking University)、上海交通大學 (Shanghai Jiaotong University) 和香港中文大學 (CUHK) 的一組研究人員提出了一種強化學習框架,該框架通過有效利用密集反饋來消除對明確逐步標註的需求。他們提出的主要貢獻是引入了一種隱式過程獎勵模型 (Implicit Process Reward Model, Implicit PRM),該模型獨立於結果標籤生成令牌級獎勵,從而消除了對人為標註逐步指導的需求。這種方法允許獎勵模型的持續在線改進,消除了過度優化的問題,同時不允許動態策略展開調整。該框架能夠在優勢估計過程中成功整合隱式過程獎勵和結果獎勵,提供計算效率並消除獎勵黑客的問題。與之前的方法不同,新的方法直接從策略模型本身初始化 PRM,從而大大減少了開發開銷。它還與多種強化學習算法兼容,包括 REINFORCE、PPO 和 GRPO,使其在訓練大型語言模型時具有普遍性和可擴展性。

這個強化學習系統提供令牌級的隱式過程獎勵,通過學習的獎勵模型和參考模型之間的對數比率公式進行計算。獎勵函數不是通過手動標註來獲得,而是從已經獲得的原始結果標籤中學習,這些標籤已經用於策略訓練。該系統還包括獎勵函數的在線學習,以避免過度優化和獎勵黑客。它使用混合優勢估計方法,通過留一法蒙特卡羅估計器結合隱式過程獎勵和結果獎勵。政策優化是通過近端政策優化 (Proximal Policy Optimization, PPO) 使用剪裁的替代損失函數來實現穩定性。該模型使用 Qwen2.5-Math-7B-Base 訓練,這是一個針對數學推理的優化模型。該系統基於 150K 的查詢,每個查詢有四個樣本,而 Qwen2.5-Math-7B-Instruct 使用了 618K 的內部標註,這顯示了訓練過程的有效性。
這個強化學習系統在多個基準測試中顯示出顯著的樣本效率和推理性能提升。與標準的基於結果的強化學習相比,它在樣本效率上提高了 2.5 倍,在數學問題解決上提高了 6.9%。該模型在數學基準測試中超越了 Qwen2.5-Math-7B-Instruct,在競賽級任務如 AIME 和 AMC 上的準確性更高。從這個過程訓練的模型在挑戰性推理任務上超越了更大的模型,包括 GPT-4o,並且在僅使用 Qwen2.5-Math-7B-Instruct 使用的 10% 訓練數據的情況下,達到了更高的 pass@1 準確性。這些結果證實了對獎勵模型的在線更新避免了過度優化,增強了訓練穩定性,並改善了信用分配,使這成為一種非常強大的強化學習方法,適用於大型語言模型。
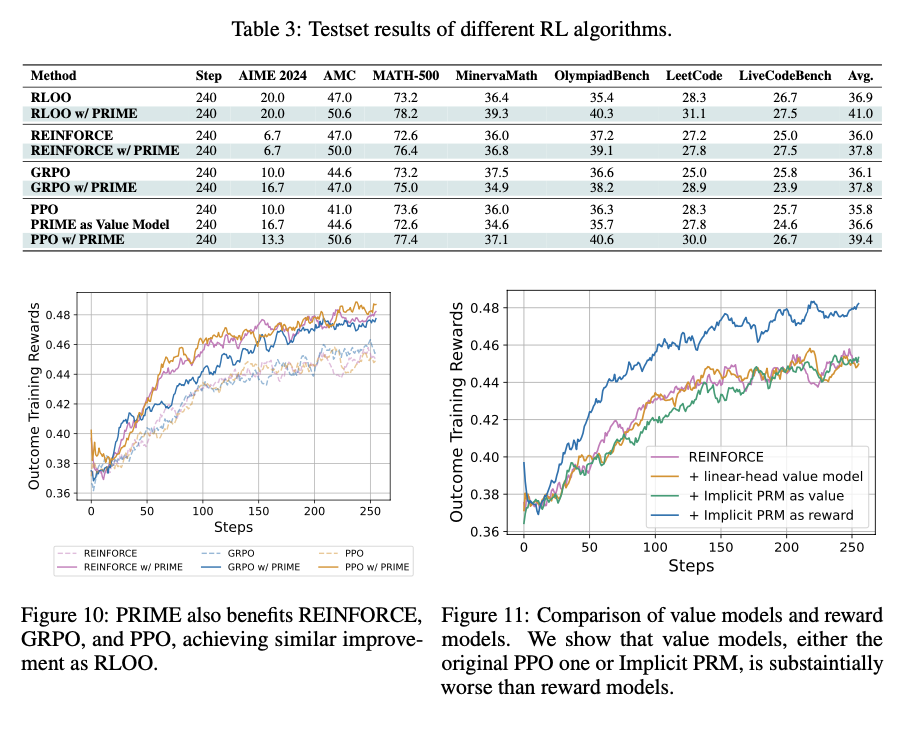
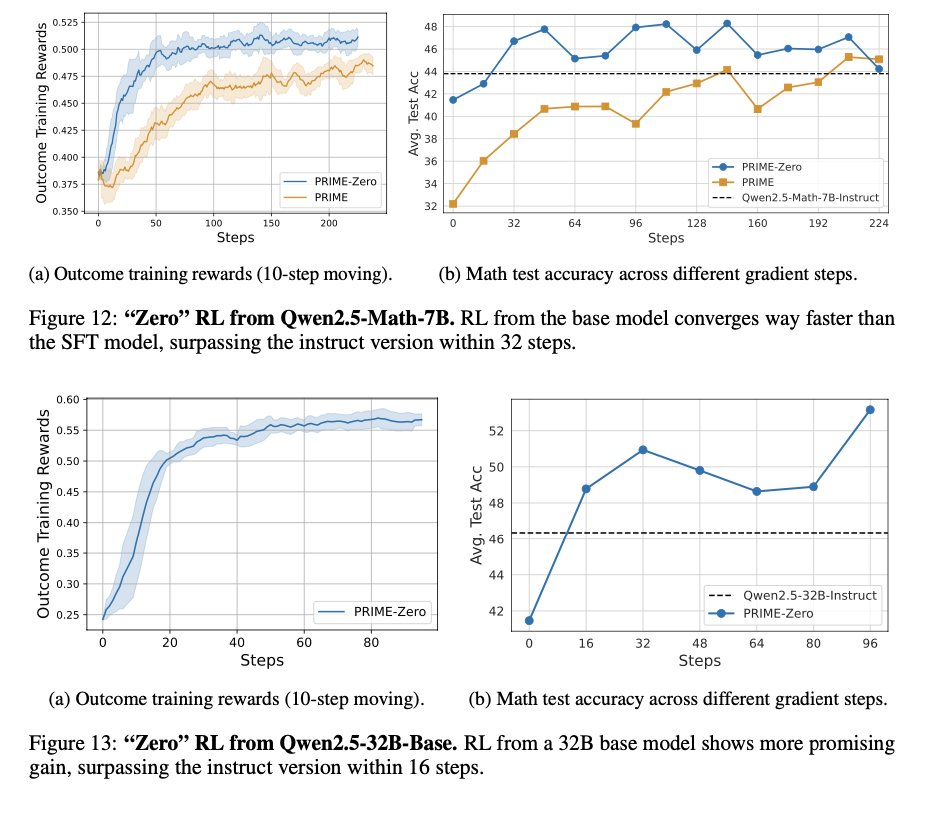
這種強化學習方法提供了一個高效且可擴展的 LLM 訓練過程,具有密集的隱式過程獎勵。這消除了逐步明確標註的需求,並最小化了訓練成本,同時提高了樣本效率、穩定性和性能。這個過程和在線獎勵建模及令牌級反饋的結合,成功解決了強化學習中長期存在的獎勵稀疏和信用分配問題。這些改進優化了 AI 模型的推理能力,使其適合數學和程式設計的問題解決應用。這項研究對基於強化學習的 LLM 訓練做出了重要貢獻,為更高效、可擴展和高性能的 AI 訓練方法鋪平了道路。
查看論文和 GitHub 頁面。所有研究的功勞都歸於這個項目的研究人員。此外,別忘了在 Twitter 上關注我們,加入我們的 Telegram 頻道和 LinkedIn 群組。也別忘了加入我們的 75k+ ML SubReddit。
🚨 推薦的開源 AI 平台:‘IntellAgent 是一個開源多代理框架,用於評估複雜的對話 AI 系統’ (推廣)
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!



")




{kind=link}