


多向檢索(Multi-vector retrieval)是一項在資訊檢索領域的重要進展,尤其是隨著基於變壓器(transformer)模型的應用。與單向檢索(single-vector retrieval)不同,單向檢索將查詢和文件編碼為單一的密集向量,而多向檢索則允許每個文件和查詢有多個嵌入(embeddings)。這種方法提供了更細緻的表示,提升了搜尋的準確性和檢索的品質。隨著時間的推移,研究人員開發了各種技術來提高多向檢索的效率和可擴展性,解決了處理大型數據集時的計算挑戰。
多向檢索的一個主要問題是平衡計算效率與檢索性能。傳統的檢索技術雖然快速,但常常無法檢索到文件中的複雜語義關係。另一方面,準確的多向檢索方法因為需要進行多次相似度計算而經常出現延遲。因此,挑戰在於建立一個系統,既能保持多向檢索的優勢特徵,又能顯著減少計算開銷,使大型應用的即時搜尋成為可能。
為了提高多向檢索的效率,已經引入了幾項改進。ColBERT引入了一種延遲互動機制來優化檢索,使查詢與文件的互動在計算上更有效率。隨後,ColBERTv2和PLAID進一步擴展了這一理念,通過引入更高效的修剪技術和在C++中優化的內核來提升性能。同時,Google DeepMind的XTR框架簡化了計分過程,無需獨立的文件收集階段。然而,這些模型仍然面臨效率問題,主要在於標記檢索和文件計分,導致延遲和資源使用率較高。
來自蘇黎世聯邦理工學院(ETH Zurich)、加州大學伯克利分校(UC Berkeley)和史丹佛大學(Stanford University)的研究團隊推出了WARP,一個旨在優化基於XTR的ColBERT檢索的搜尋引擎。WARP整合了ColBERTv2和PLAID的進展,並加入獨特的優化措施來提高檢索效率。WARP的主要創新包括WARPSELECT,一種動態相似度填補方法,消除了不必要的計算,還有一種隱式解壓機制,減少了內存操作,以及一種兩階段的減少過程以加快計分。這些改進使WARP在不妥協檢索品質的情況下,顯著提升了速度。
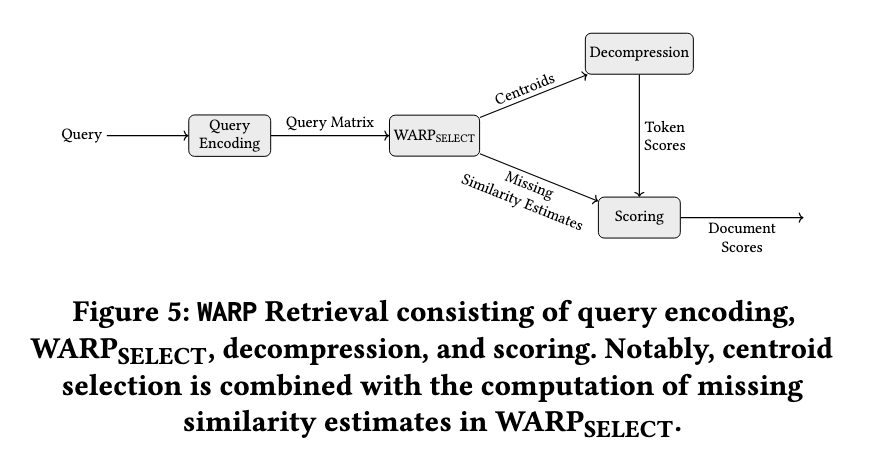
WARP檢索引擎使用結構化的優化方法來提高檢索效率。首先,它使用微調過的T5變壓器對查詢和文件進行編碼,並生成標記級別的嵌入。然後,WARPSELECT決定查詢的最相關文件集群,同時避免重複的相似度計算。在檢索過程中,WARP進行隱式解壓,以顯著減少計算開銷。接著,使用兩階段的減少方法來有效計算文件分數。這種將標記級別的分數聚合,然後將文件級別的分數相加,並動態處理缺失的相似度估計,使WARP在效率上遠超其他檢索引擎。
WARP顯著提高了檢索性能,同時大幅減少了查詢處理時間。實驗結果顯示,WARP的端到端查詢延遲比XTR參考實現降低了41倍,並將查詢響應時間從超過6秒降低到171毫秒,且僅使用單一線程。此外,WARP的速度比ColBERTv2/PLAID快三倍。索引大小也得到了優化,存儲需求比基準方法減少了2到4倍。而且,WARP在保持高品質的基準數據集上,超越了之前的檢索模型。
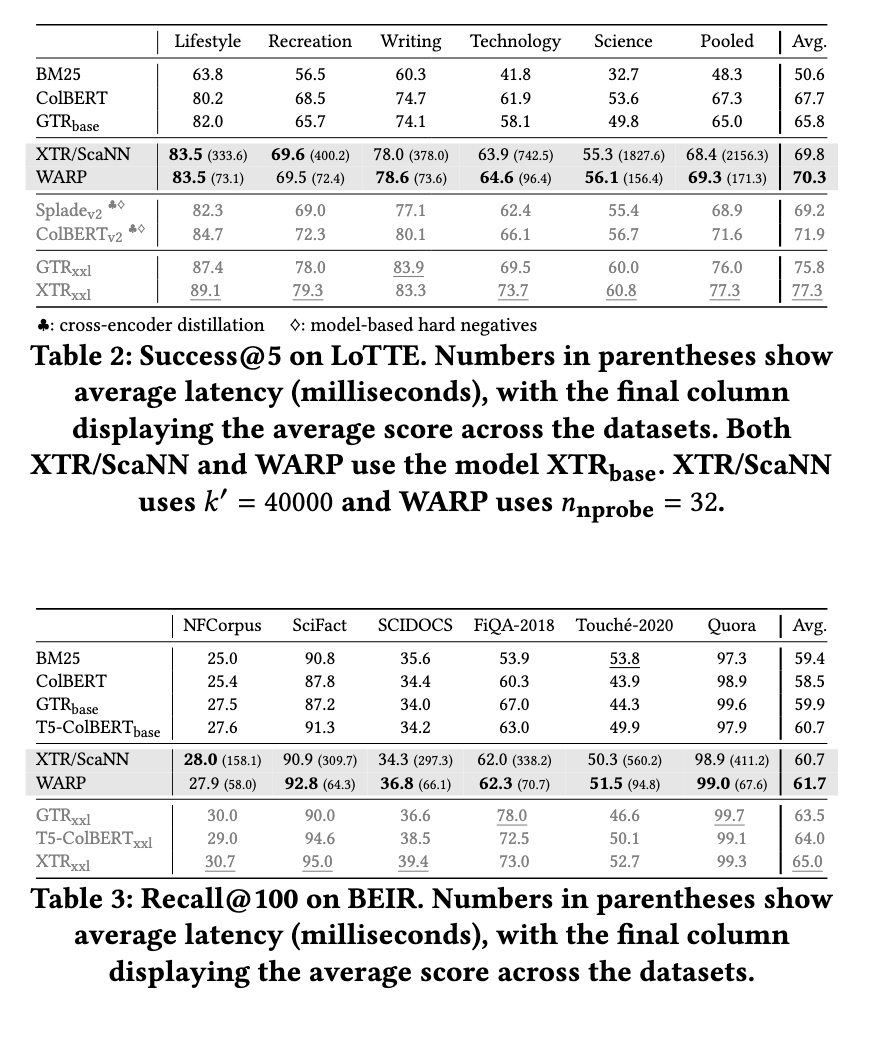
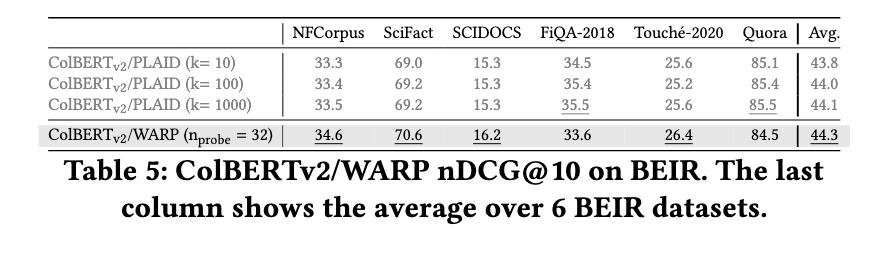
WARP的開發標誌著多向檢索優化的一個重要進步。研究團隊成功地通過將新穎的計算技術與現有的檢索框架結合,改善了速度和效率。這項研究強調了在保持檢索品質的同時減少計算瓶頸的重要性。WARP的推出為未來多向搜尋系統的改進鋪平了道路,提供了一個可擴展的高速度和準確的資訊檢索解決方案。
查看論文和GitHub頁面。這項研究的所有功勞都歸於這個項目的研究人員。此外,別忘了在Twitter上關注我們,加入我們的Telegram頻道和LinkedIn小組。也別忘了加入我們的70k+ ML SubReddit。
🚨 介紹IntellAgent:一個開源的多代理框架,用於評估複雜的對話式AI系統(廣告)
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}