


語音合成技術(TTS)的發展對於將書面內容轉換成口語語言非常重要,讓使用者能夠以聽的方式與文字互動。這項技術特別有助於理解包含複雜信息的文件,例如科學論文和技術手冊,這些文件對於僅依賴聽覺理解的人來說往往會帶來很大的挑戰。
目前的語音合成系統一個持續存在的問題是無法準確處理數學公式。這些系統通常將公式視為普通文本,導致生成的語音難以理解或不完整。這個問題在使用 LaTeX 表示數學內容的學術和技術文件中尤其常見。由於公式以獨特的格式呈現,傳統的語音合成系統無法識別其數學意義,導致語音輸出不準確或遺漏。這一限制對於使用者,尤其是在數學和科學領域的人來說,是一個重大障礙。
目前解決這個問題的方法涉及光學字符識別(OCR)技術和基本的語音合成整合。然而,這些方法有其局限性。例如,OCR 系統將公式轉換為文本,但無法解釋其語義結構,因此不適合進行準確的語音化。像 Microsoft Edge 和 Adobe Acrobat 等流行的語音合成閱讀器會跳過或錯誤讀取數學公式,這突顯了需要更複雜解決方案的必要性。一些工具試圖將 LaTeX 代碼手動映射到口語英語,但在特殊情況下表現不佳,且不適合廣泛使用。
來自首爾國立大學、中央大學和 NVIDIA 的研究人員開發了 MathReader,以彌補技術與需要閱讀數學文本的使用者之間的差距。MathReader 結合了 OCR、一個經過微調的 T5-small 語言模型和一個 TTS 系統,能夠無誤地解碼數學表達式。它克服了當前技術的局限,使文件中的公式能夠準確地被語音化。這個流程確保數學內容轉換為音頻,對視障使用者特別有幫助。
MathReader 採用五步法來處理文件。首先,使用 OCR 從文件中提取文本和公式。基於層次視覺變壓器的 Nougat-small OCR 模型將 PDF 轉換為標記語言文件,同時區分文本和 LaTeX 公式。接下來,使用獨特的 LaTeX 標記來識別公式。然後,經過微調的 T5-small 語言模型將這些公式翻譯成口語英語,有效地將數學表達式轉換為可聽的語言。隨後,翻譯後的公式替換文本中的 LaTeX 版本,以確保與 TTS 系統的兼容性。最後,VITS TTS 模型將更新的文本轉換為高品質的語音。這個流程確保了準確性和效率,使 MathReader 成為一個突破性的文件可訪問工具。

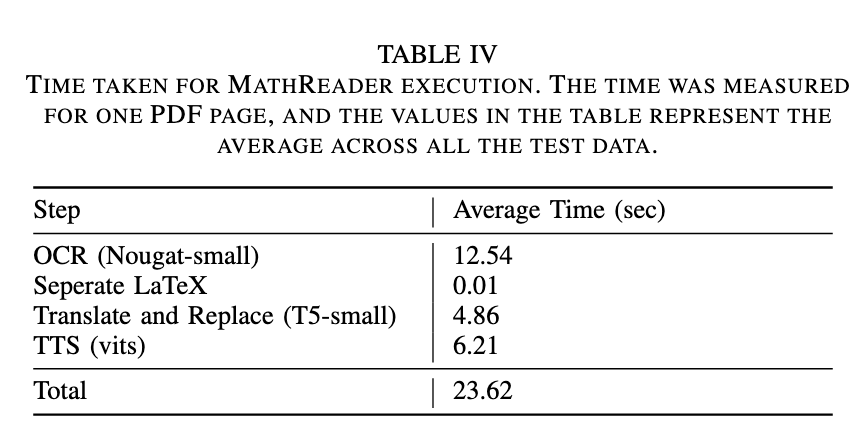
性能評估顯示 MathReader 的有效性。它的表現顯著優於現有的語音合成系統,實現了 0.281 的字錯誤率(WER),而 Microsoft Edge 為 0.510,Adobe Acrobat 為 0.617。同樣,它的字符錯誤率(CER)也非常低,為 0.148,而其他系統則為 0.341 和 0.454。這一顯著的改進顯示了 MathReader 提供準確語音輸出的能力,即使是對於低解析度或複雜數學內容的文件。例如,MathReader 成功語音化了其他系統跳過的公式,顯示了其穩健性。此外,處理單頁所需的平均時間為 23.62 秒,其中 OCR 需要 12.54 秒,TTS 轉換需要 6.21 秒,顯示了其在實時應用中的實用性。

MathReader 代表了語音合成技術的一個重大進步,解決了準確語音化數學內容的關鍵挑戰。它整合了先進的 OCR、微調的語言模型和 TTS,為依賴聽覺訪問文件的使用者提供了全面的解決方案。通過提供精確和高效的結果,MathReader 為可訪問性工具樹立了新的標準,成為視障人士不可或缺的資源,並為未來在該領域的創新鋪平了道路。
查看論文。這項研究的所有功勞都歸功於這個項目的研究人員。此外,別忘了在 Twitter 上關注我們,加入我們的 Telegram 頻道和 LinkedIn 群組。還有,別忘了加入我們的 65k+ ML SubReddit。
🚨 [推薦閱讀] Nebius AI Studio 擴展了視覺模型、新的語言模型、嵌入和 LoRA(推廣)
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!



")




{kind=link}