


自注意力機制是變壓器架構的一個重要組成部分,但在理論基礎和實際應用上面臨著巨大的挑戰。儘管在自然語言處理、計算機視覺等領域取得了成功,但它們的發展往往依賴於經驗性的方法,這限制了其可解釋性和擴展性。自注意力機制也容易受到數據損壞和對抗性攻擊的影響,這使得它們在實際應用中不可靠。所有這些問題都需要解決,以提高變壓器模型的穩健性和效率。
傳統的自注意力技術,包括softmax注意力,根據相似性來計算加權平均值,以建立輸入標記之間的動態關係。雖然這些方法有效,但也存在重大限制。缺乏正式化的框架妨礙了其適應性和對其基本過程的理解。此外,自注意力機制在面對對抗性或噪聲環境時,表現往往會下降。最後,龐大的計算需求限制了它們在資源有限的環境中的應用。這些限制呼籲需要理論上有原則、計算上高效的方法,並且對數據異常具有穩健性。
來自新加坡國立大學的研究人員提出了一種使用核主成分分析(Kernel Principal Component Analysis, KPCA)重新詮釋自注意力的創新方法,建立了一個全面的理論框架。這一新詮釋帶來了幾個重要的貢獻。它將自注意力數學上重新表述為查詢向量在特徵空間中投影到鍵矩陣的主成分軸上,使其更具可解釋性。此外,研究顯示值矩陣編碼了鍵向量的Gram矩陣的特徵向量,建立了自注意力與KPCA原則之間的密切聯繫。研究人員提出了一種穩健的機制來解決數據的脆弱性:使用穩健主成分的注意力(RPC-Attention)。利用主成分追求(Principal Component Pursuit, PCP)來區分未受污染的數據與主要矩陣中的扭曲,顯著增強了穩健性。這一方法將理論精確性與實際增強相連接,從而提高了自注意力機制的效能和可靠性。
這一構建包含多個複雜的技術組件。在KPCA框架內,查詢向量根據其在特徵空間中的表示,與主成分軸對齊。應用主成分追求將主要矩陣分解為低秩和稀疏組件,以減輕數據損壞帶來的問題。通過在某些變壓器層中小心地用更穩健的替代機制替換softmax注意力,實現了高效的實施,這在效率和穩健性之間取得了平衡。這一方法在分類數據集(如ImageNet-1K)、分割數據集(如ADE20K)和語言建模(如WikiText-103)上進行了廣泛測試,證明了其在各個領域的多樣性。
這項工作顯著提高了不同任務的準確性、穩健性和韌性。該機制提高了物體分類中的清晰準確性,並降低了在損壞和對抗性攻擊下的錯誤率。在語言建模中,它顯示出較低的困惑度,這反映了增強的語言理解能力。在圖像分割中,它在乾淨和噪聲數據集上表現出優越的性能,支持其對各種挑戰的適應性。這些結果顯示了它克服傳統自注意力方法關鍵限制的潛力。
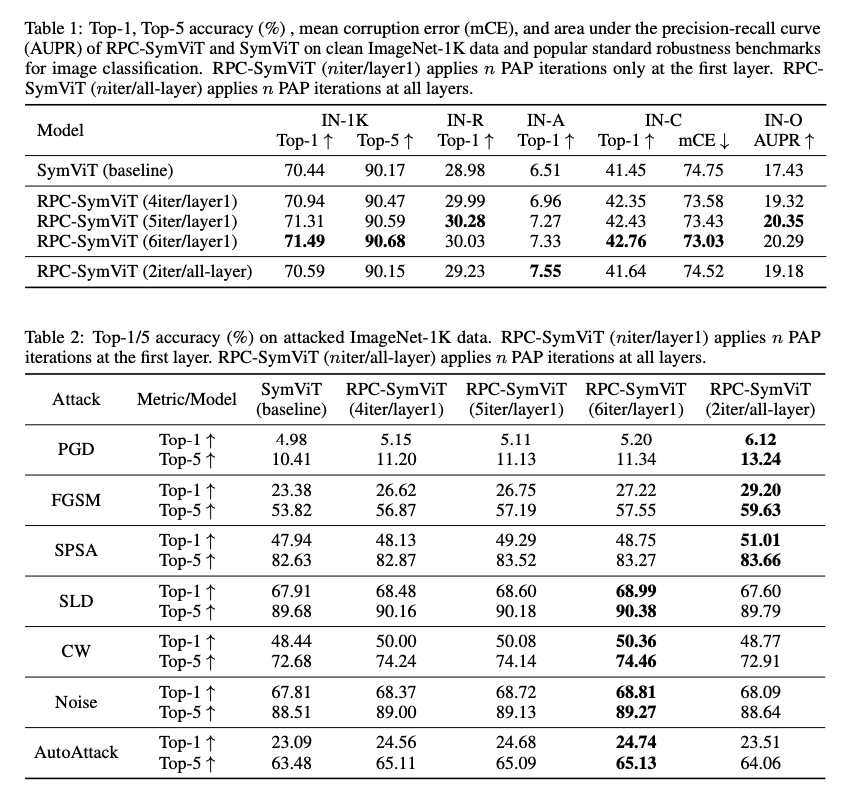
研究人員通過KPCA重新定義了自注意力,從而為應對數據脆弱性和計算挑戰提供了有原則的理論基礎和穩健的注意力機制。這些貢獻大大增強了對變壓器架構的理解和能力,促進了更穩健和高效的人工智慧應用的發展。
查看論文和GitHub頁面。這項研究的所有功勞都歸功於這個項目的研究人員。此外,別忘了在Twitter上關注我們,並加入我們的Telegram頻道和LinkedIn小組。還有,別忘了加入我們的60,000多名機器學習SubReddit。
🚨 免費即將舉行的AI網絡研討會(2025年1月15日):使用合成數據和評估智慧提升LLM準確性–加入這個網絡研討會,獲取提升LLM模型性能和準確性的可行見解,同時保護數據隱私。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}