


大型語言模型 (LLMs) 在解決語言處理、數學和推理等複雜問題中扮演著重要角色。計算技術的改進旨在讓 LLMs 更有效地處理數據,生成更準確且符合上下文的回應。隨著這些模型變得越來越複雜,研究人員努力開發方法,以在固定的計算預算內運行,而不影響性能。
優化 LLMs 的一個主要挑戰是它們無法有效地在多個任務之間推理,或進行超出其預訓練架構的計算。目前改善模型性能的方法涉及在任務處理過程中生成中間步驟,這通常會導致延遲和計算效率低下。這一限制妨礙了它們執行複雜推理任務的能力,特別是那些需要較長依賴關係或更高預測準確性的任務。
研究人員探索了像是思維鏈 (Chain-of-Thought, CoT) 提示的方法,這種方法指導 LLMs 逐步推理。雖然在某些情況下有效,但 CoT 依賴於中間推理步驟的順序處理,導致計算時間變慢。還提出了 KV 快取壓縮以減少內存使用,但對推理能力的改善幫助不大。這些方法雖然有價值,但突顯了需要一種結合效率與增強推理能力的方法。
來自 Google DeepMind 的研究人員提出了一種名為可微快取增強 (Differentiable Cache Augmentation) 的方法。這項技術使用訓練過的協處理器來增強 LLM 的鍵值 (kv) 快取,豐富模型的內部記憶。這一創新之處在於在訓練協處理器的同時保持基本 LLM 不變,協處理器以非同步方式運行。研究人員設計這種方法以增強推理能力,同時不增加任務執行期間的計算負擔。
這種方法論圍繞著三個階段的過程。首先,凍結的 LLM 從輸入序列生成 kv 快取,封裝其內部表示。這個 kv 快取被傳遞給協處理器,協處理器使用額外的可訓練軟標記進行處理。這些標記不與特定單詞相關聯,而是作為生成潛在嵌入的抽象提示。一旦處理完成,增強的 kv 快取會被反饋回 LLM,使其能夠生成上下文豐富的輸出。這種非同步操作確保了協處理器的增強能有效應用,而不會延遲 LLM 的主要功能。訓練協處理器是使用語言建模損失進行的,專注於其參數,同時保持凍結 LLM 的完整性。這種有針對性的方法允許可擴展和有效的優化。
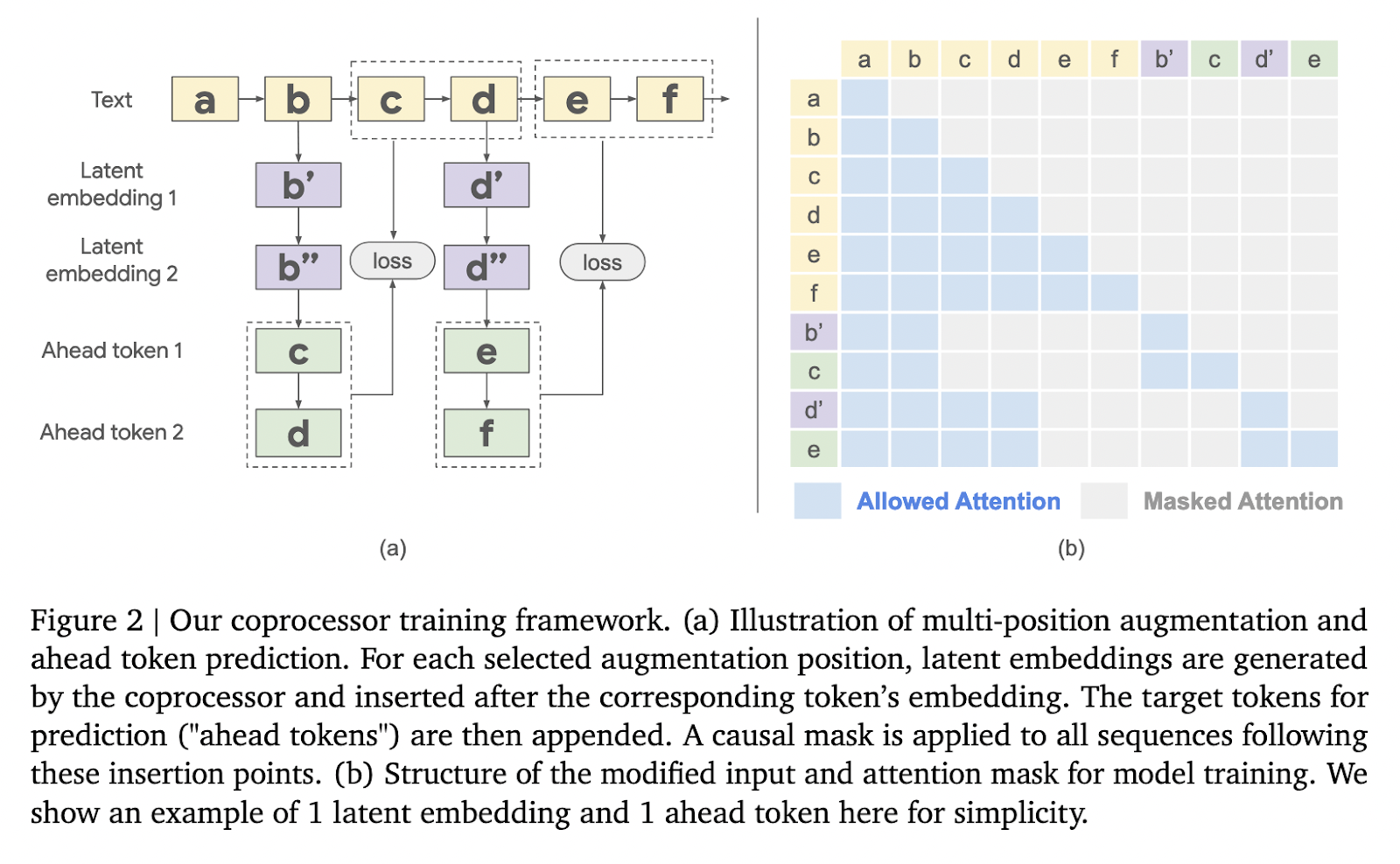
性能評估顯示出顯著的改善。這種方法在 Gemma-2 2B 模型上進行測試,在各種基準測試中取得了可觀的結果。例如,在推理密集的 GSM8K 數據集上,當使用 64 個潛在嵌入時,準確度提高了 10.05%。同樣,在相同配置下,MMLU 的性能提高了 4.70%。這些增強突顯了模型在複雜推理任務中的表現能力。此外,在多個標記位置觀察到了困惑度的降低。例如,當應用 64 個潛在嵌入時,位置一的困惑度降低了 3.94%,位置 32 的困惑度降低了 1.20%,顯示出模型在較長序列上的預測能力有所改善。
進一步分析顯示,增強的有效性隨著潛在嵌入數量的增加而增強。對於 GSM8K,準確度隨著額外嵌入的增加而逐步上升,從四個嵌入的 1.29% 到 64 個嵌入的最高改善 10.05%。在 ARC 和 MATH 等其他基準測試中也觀察到了類似的趨勢,顯示這種方法的廣泛適用性。研究人員確認,他們的方法在沒有針對特定任務的微調下,始終超越基準模型,顯示其穩健性和適應性。

這項工作代表了增強 LLM 推理能力的一個重要進展。通過引入外部協處理器來增強 kv 快取,來自 Google DeepMind 的研究人員創造了一種在保持計算效率的同時改善性能的方法。結果突顯了 LLM 在處理更複雜任務方面的潛力,為進一步探索模塊化增強和可擴展推理系統鋪平了道路。這一突破強調了在人工智慧領域持續創新的重要性,以滿足日益增長的推理密集型應用需求。
查看論文。這項研究的所有榮譽歸功於這個項目的研究人員。此外,別忘了在 Twitter 上關注我們,加入我們的 Telegram 頻道和 LinkedIn 群組。也別忘了加入我們的 60k+ ML SubReddit。
🚨 熱門消息:LG AI 研究發布 EXAONE 3.5:三個開源雙語前沿 AI 模型提供無與倫比的指令跟隨和長上下文理解,為生成 AI 卓越的全球領導地位鋪平道路……。
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}